Hadoop的快速入门之 Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)
目的
这篇文章主要是个人在学习Hadoop的学习笔记,主要是为了在Linux平台下搭建单机模式和伪分布模式的Hadoop环境。
所需软件
Ubuntu 10.04.1
hadoop-0.20.203.0
Hadoop简介
Hadoop是Apache开源组织的一个分布式计算框架,可以在大量廉价硬件设备组成的集群上运行应用程序,并为应用程序提供了一组稳定可靠的接口,旨在构建一个具有高可靠性和良好扩展性的分布式系统。随着云计算技术的逐渐流行与普及,该项目被越来越多的个人和企业所运用。Hadoop项目的核心是HDFS、MapReduce和HBase,它们分别是Google云计算核心技术GFS(Google File System)、MapReduce和Bigtable的开源实现。
Hadoop的运行模式
Hadoop集群有三种运行模式,分别为单机模式,伪分布模式,完全分布式模式。本书将重点介绍完全分布式模式下Hadoop的安装与配置。
1. 单机模式
单机模式是Hadoop的默认模式。在该模式下无需运行任何守护进程,所有程序都在单个JVM上执行。该模式主要用于开发调试MapReduce程序的应用逻辑。
2. 伪分布模式
在伪分布模式下,Hadoop守护进程运行在一台机器上,模拟一个小规模的集群。该模式在单机模式的基础上增加了代码调试功能,允许你检查NameNode,DataNode,JobTracker,TaskTracker等模拟节点的运行情况。
3. 完全分布式模式
单机模式和伪分布模式均用于开发与调试的目的。真实Hadoop集群的运行采用的是全分布模式。
单机模式安装步骤如下:
一、在Ubuntu下创建hadoop用户组和用户
1、添加hadoop用户到系统用户
安装前要做一件事——添加一个名为hadoop到系统用户,专门用来做Hadoop测试。
1 ~$ sudo addgroup hadoop 2 ~$ sudo adduser --ingroup hadoop hadoop
2、给hadoop用户添加权限,打开/etc/sudoers文件

给hadoop用户赋予root用户同样的权限。在root ALL=(ALL:ALL) ALL下添加hadoop ALL=(ALL:ALL) ALL

3、修改机器名
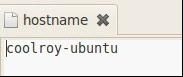
当Ubuntu安装成功时,我们的机器名都默认为:ubuntu ,但为了以后集群中能够容易分辨各台服务器,需要给每台机器取个不同的名字。机器名由 /etc/hostname文件决定。
1)打开/etc/hostname文件

2)将/etc/hostname文件中的ubuntu改为你想取的机器名,重启系统后才会生效。
二、配置SSH
配置SSH是为了实现各机器之间执行指令无需输入登录密码。务必要避免输入密码,否则,主节点每次试图访问其他节点时,都需要手动输入这个密码。
SSH无密码原理:master(namenode/jobtrack)作为客户端,要实现无密码公钥认证,连接到服务器slave(datanode/tasktracker)上时,需要在master上生成一个公钥对,包括一个公钥和一个私钥,而后将公钥复制到所有的slave上。当master通过SSH连接slave时,slave就会生成一个随机数并用master的公钥对随机数进行加密,并发送给master。Master收到密钥加密数之后再用私钥解密,并将解密数回传给slave,slave确认解密数无误后就允许master进行连接了。这就是一个公钥认证的过程,期间不需要用户手工输入密码。重要过程是将客户端master复制到slave上。
1、安装ssh
1)由于Hadoop用ssh通信,先安装ssh(其中二三步不一定需要执行)、
![]()
2)自动安装openssh-server时,可能会进行不下去,可以先进行如下操作:(我遇到了)
![]()
3)更新的快慢取决于您的网速了,如果中途因为时间过长您中断了更新(Ctrl+z),当您再次更新时,会更新不了,报错为:“Ubuntu无法锁定管理目录(/var/lib/dpkg/),是否有其他进程占用它?“需要如下操作
![]()
操作完成后继续操作第一步。
2、假设ssh安装完成以后,先启动服务。启动后,可以通过命令查看服务是否正确启动:

3、作为一个安全通信协议(ssh生成密钥有rsa和dsa两种生成方式,默认情况下采用rsa方式),使用时需要密码,因此我们要设置成免密码登录,生成私钥和公钥:
1 hadoop@scgm-ProBook:~$ ssh-keygen -t rsa -P ""
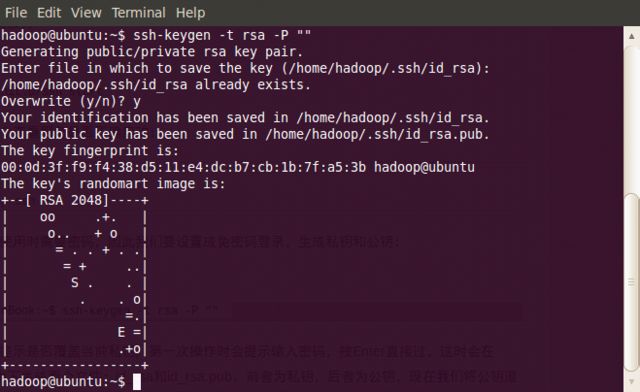
(注:回车后会在~/.ssh/下生成两个文件:id_rsa和id_rsa.pub这两个文件是成对出现的前者为私钥,后者为公钥)
进入~/.ssh/目录下,将公钥id_rsa.pub追加到authorized_keys授权文件中,开始是没有authorized_keys文件的(authorized_keys用于保存所有允许以当前用户身份登录到ssh客户端用户的公钥内容):
~$ cat ~/.ssh/id_rsa.pub>> ~/.ssh/authorized_keys
现在可以登入ssh确认以后登录时不用输入密码:
~$ ssh localhost
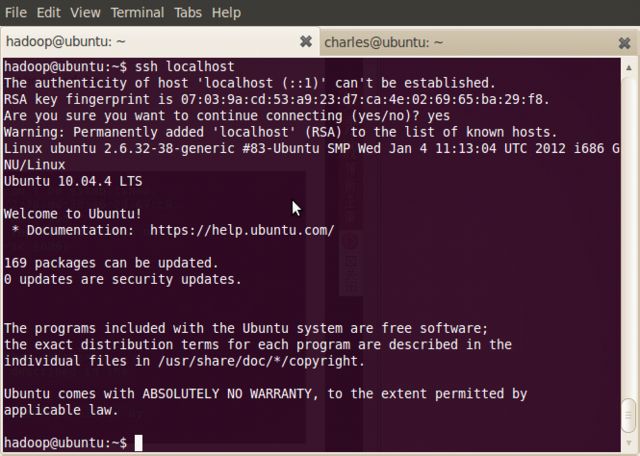
( 注:当ssh远程登录到其它机器后,现在你控制的是远程的机器,需要执行退出命令才能重新控制本地主机。)
登出:~$ exit
这样以后登录就不用输入密码了。
三、安装Java
~$ sudo apt-get install openjdk-6-jdk
~$ java -version

四、安装hadoop-0.20.203
到官网下载hadoop源文件,我采用的是hadoop-0.20.203.0 因为该版本稳定。
解压并放到你希望的目录中。我是放到/usr/local/hadoop,并将解压后的文件夹重命名为hadoop
![]()

要确保所有的操作都是在用户hadoop下完成的,所以将该hadoop文件夹的属主用户设为hadoop
![]()
五、配置hadoop-env.sh(Java 安装路径)
进入hadoop目录,打开conf目录下到hadoop-env.sh,添加以下信息:(找到#export JAVA_HOME=...,去掉#,然后加上本机jdk的路径)
export JAVA_HOME=/usr/lib/jvm/java-6-openjdk (视你机器的java安装路径而定)
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:/usr/local/hadoop/bin

并且,让环境变量配置生效source
~$ source /usr/local/hadoop/conf/hadoop-env.sh
至此,hadoop的单机模式已经安装成功。
现在运行一下hadoop自带的例子WordCount来感受以下MapReduce过程:
或者直接到伪分布模式。
在hadoop目录下新建input文件夹
~$ mkdir input
将conf中的所有文件拷贝到input文件夹中
~$ cp conf/* input
运行WordCount程序,并将结果保存到output中
~$ bin/hadoop jar hadoop-0.20.2-examples.jar wordcount input output
运行
~$ cat output/*
你会看到conf所有文件的单词和频数都被统计出来。
下面是伪分布模式需要的一些配置
设定*-site.xml
这里需要设定3个文件:core-site.xml hdfs-site.xml mapred-site.xml,都在/usr/local/hadoop/conf目录下
core-site.xml: Hadoop Core的配置项,例如HDFS和MapReduce常用的I/O设置等。
hdfs-site.xml: Hadoop 守护进程的配置项,包括namenode,辅助namenode和datanode等。
mapred-site.xml: MapReduce 守护进程的配置项,包括jobtracker和tasktracker。
编辑那三个文件:
core-site.xml:
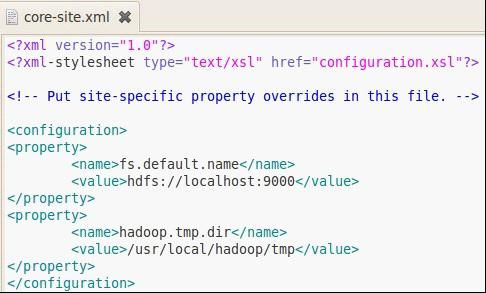
hdfs-site.xml:
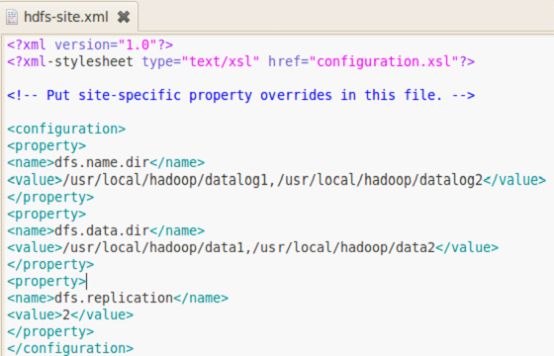
mapred-site.xml:
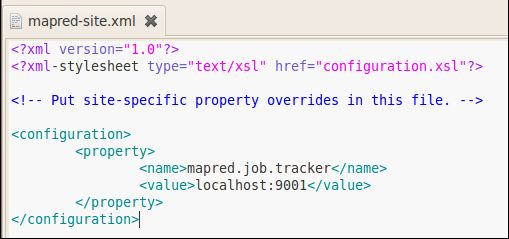

格式化HDFS
通过以上步骤,我们已经设定好Hadoop单机测试到环境,接着就是启动Hadoop到相关服务,进入hadoop目录下,格式化hdfs文件系统,初次运行hadoop时一定要有该操作。格式化namenode,secondarynamenode,tasktracker:
~$ source /usr/local/hadoop/conf/hadoop-env.sh
~$ hadoop namenode -format
看到下面的信息就说明hdfs文件系统格式化成功了

启动Hadoop
接着执行start-all.sh来启动所有服务,包括namenode,datanode,start-all.sh脚本用来装载守护进程。用Java的jps命令列出所有守护进程来验证安装成功,出现如下列表,表明成功
检查运行状态
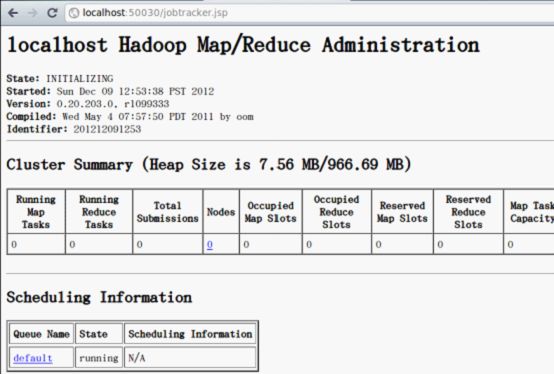
所有的设置已完成,Hadoop也启动了,现在可以通过下面的操作来查看服务是否正常,在Hadoop中用于监控集群健康状态的Web界面:
http://localhost:50030/ - Hadoop 管理介面
http://localhost:50060/ - Hadoop Task Tracker 状态
http://localhost:50070/ - Hadoop DFS 状态
Hadoop 管理介面:
Hadoop Task Tracker 状态:

Hadoop DFS 状态:
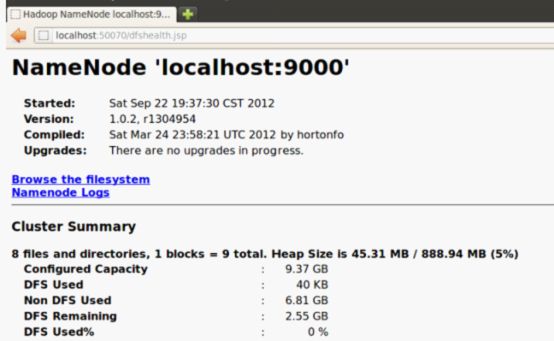
至此,hadoop的伪分布模式已经安装成功
再次在伪分布模式下运行一下hadoop自带的例子WordCount来感受以下MapReduce过程:
这时注意程序是在文件系统dfs运行的,创建的文件也都基于文件系统:
首先在dfs中创建input目录
hadoop@ubuntu:/usr/local/hadoop$ bin/hadoop dfs -mkdir input
将conf中的文件拷贝到dfs中的input
hadoop@ubuntu:/usr/local/hadoop$ hadoop dfs -copyFromLocal conf/* input
在伪分布式模式下运行WordCount
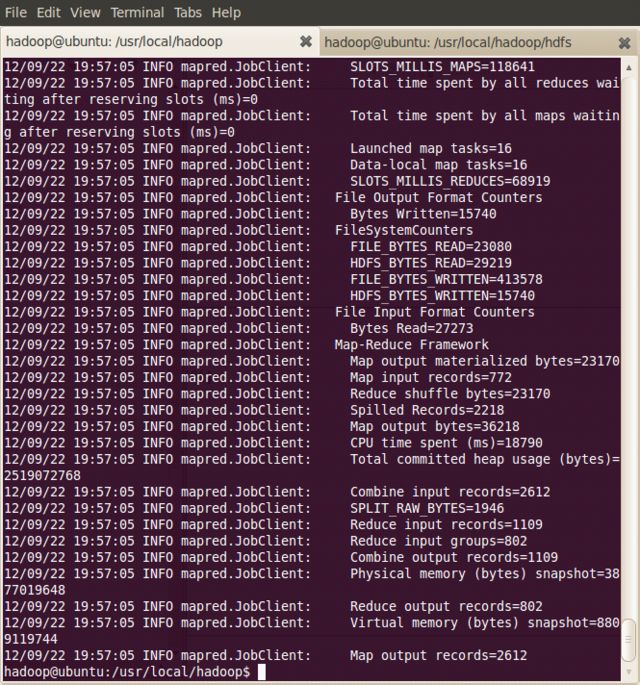
hadoop@ubuntu:/usr/local/hadoop$ hadoop jar hadoop-examples-1.0.2.jar wordcount input output
可看到以下过程
显示输出结果
hadoop@ubuntu:/usr/local/hadoop$ hadoop dfs -cat output/*
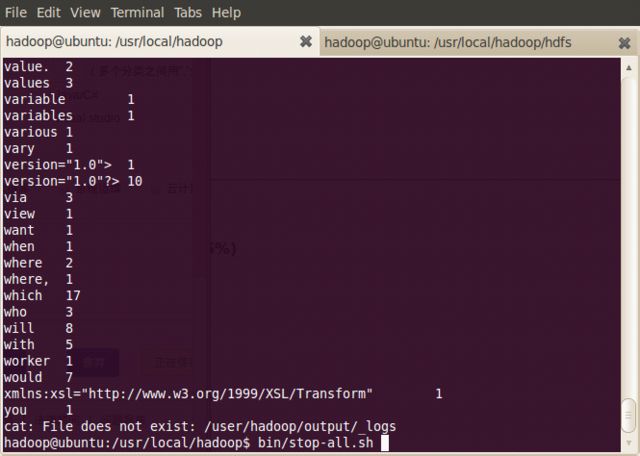
当Hadoop结束时,可以通过stop-all.sh脚本来关闭Hadoop的守护进程
hadoop@ubuntu:/usr/local/hadoop$ bin/stop-all.sh
完全分布式模式的操作方法正在尝试
基本参照他人方法,和官网介绍。
http://www.cnblogs.com/IlvDanping1024/archive/2012/12/16/2816462.html