Android性能优化
随着技术的发展,智能手机硬件配置越来越高,可是它和现在的PC相比,其运算能力,续 航能力,存储空间等都还是受到很大的限制,同时用户对手机的体验要求远远高于PC的桌面应用程序。以上理由,足以需要开发人员更加专心去实现和优化你的代 码了。选择合适的算法和数据结构永远是开发人员最先应该考虑的事情。同时,我们应该时刻牢记,写出高效代码的两条基本的原则:(1)不要做不必要的事; (2)不要分配不必要的内存。
我从去年开始接触Android开发,以下结合自己的一点项目经验,同时参考了Google的优化文档和网上的诸多技术大牛给出的意见,整理出这份文档。
1. 内存优化
Android系统对每个软件所能使用的RAM空间进行了限制(如:Nexus one 对每个软件的内存限制是24M),同时Java语言本身比较消耗内存,dalvik虚拟机也要占用一定的内存空间,所以合理使用内存,彰显出一个程序员的素质和技能。
1) 了解JIT
即时编译(Just-in-time Compilation,JIT),又称动态转译(Dynamic Translation),是一种通过在运行时将字节码翻译为机器码,从而改善字节码编译语言性能的技术。即时编译前期的两个运行时理论是字节码编译和动 态编译。Android原来Dalvik虚拟机是作为一种解释器实现,新版(Android2.2+)将换成JIT编译器实现。性能测试显示,在多项测试 中新版本比旧版本提升了大约6倍。
详细请参考http://hi.baidu.com/cool_parkour/blog/item/2802b01586e22cd8a6ef3f6b.html
2) 避免创建不必要的对象
就像世界上没有免费的午餐,世界上也没有免费的对象。虽然gc为每个线程都建立了临时对象 池,可以使创建对象的代价变得小一些,但是分配内存永远都比不分配内存的代价大。如果你在用户界面循环中分配对象内存,就会引发周期性的垃圾回收,用户就 会觉得界面像打嗝一样一顿一顿的。所以,除非必要,应尽量避免尽力对象的实例。下面的例子将帮助你理解这条原则:
当你从用户输入的数据中截取一段字符串时,尽量使用substring函数取得原始数据的一 个子串,而不是为子串另外建立一份拷贝。这样你就有一个新的String对象,它与原始数据共享一个char数组。 如果你有一个函数返回一个String对象,而你确切的知道这个字符串会被附加到一个StringBuffer,那么,请改变这个函数的参数和实现方式, 直接把结果附加到StringBuffer中,而不要再建立一个短命的临时对象。
一个更极端的例子是,把多维数组分成多个一维数组:
int数组比Integer数组好,这也概括了一个基本事实,两个平行的int数组比 (int,int)对象数组性能要好很多。同理,这试用于所有基本类型的组合。如果你想用一种容器存储(Foo,Bar)元组,尝试使用两个单独的 Foo[]数组和Bar[]数组,一定比(Foo,Bar)数组效率更高。(也有例外的情况,就是当你建立一个API,让别人调用它的时候。这时候你要注 重对API接口的设计而牺牲一点儿速度。当然在API的内部,你仍要尽可能的提高代码的效率)
总体来说,就是避免创建短命的临时对象。减少对象的创建就能减少垃圾收集,进而减少对用户体验的影响。
3) 静态方法代替虚拟方法
如果不需要访问某对象的字段,将方法设置为静态,调用会加速15%到20%。这也是一种好的做法,因为你可以从方法声明中看出调用该方法不需要更新此对象的状态。
4) 避免内部Getters/Setters
在源生语言像C++中,通常做法是用Getters(i=getCount())代替直接字段访问(i=mCount)。这是C++中一个好的习惯,因为编译器会内联这些访问,并且如果需要约束或者调试这些域的访问,你可以在任何时间添加代码。
而在Android中,这不是一个好的做法。虚方法调用的代价比直接字段访问高昂许多。通常根据面向对象语言的实践,在公共接口中使用Getters和Setters是有道理的,但在一个字段经常被访问的类中宜采用直接访问。
无JIT时,直接字段访问大约比调用getter访问快3倍。有JIT时(直接访问字段开销等同于局部变量访问),要快7倍。
5) 将成员缓存到本地
访问成员变量比访问本地变量慢得多,下面一段代码:
[java] view plaincopy
for(int i =0; i <this.mCount; i++) {
dumpItem(this.mItems);
}
最好改成这样:
[java] view plaincopy
int count = this.mCount;
Item[] items = this.mItems;
for(int i =0; i < count; i++) {
dumpItems(items);
}
另一个相似的原则是:永远不要在for的第二个条件中调用任何方法。如下面方法所示,在每次循环的时候都会调用getCount()方法,这样做比你在一个int先把结果保存起来开销大很多。
[java] view plaincopy
for(int i =0; i < this.getCount(); i++) {
dumpItems(this.getItem(i));
}
同样如果你要多次访问一个变量,也最好先为它建立一个本地变量,例如:
[java] view plaincopy
protected void drawHorizontalScrollBar(Canvas canvas, int width, int height) {
if(isHorizontalScrollBarEnabled()) {
intsize = mScrollBar.getSize(false);
if(size <=0) {
size = mScrollBarSize;
}
mScrollBar.setBounds(0, height - size, width, height);
mScrollBar.setParams(computeHorizontalScrollRange(), computeHorizontalScrollOffset(), computeHorizontalScrollExtent(),false);
mScrollBar.draw(canvas);
}
}
这里有4次访问成员变量mScrollBar,如果将它缓存到本地,4次成员变量访问就会变成4次效率更高的栈变量访问。
另外就是方法的参数与本地变量的效率相同。
1) 对常量使用static final修饰符
让我们来看看这两段在类前面的声明:
[java] view plaincopy
static int intVal = 42;
static String strVal = "Hello, world!";
必 以其会生成一个叫做clinit的初始化类的方法,当类第一次被使用的时候这个方法会被执行。方法会将42赋给intVal,然后把一个指向类中常量表的 引用赋给strVal。当以后要用到这些值的时候,会在成员变量表中查找到他们。 下面我们做些改进,使用“final”关键字:
[java] view plaincopy
static final int intVal = 42;
static final String strVal = "Hello, world!";
现在,类不再需要clinit方法,因为在成员变量初始化的时候,会将常量直接保存到类文件中。用到intVal的代码被直接替换成42,而使用strVal的会指向一个字符串常量,而不是使用成员变量。
将一个方法或类声明为final不会带来性能的提升,但是会帮助编译器优化代码。举例说,如果编译器知道一个getter方法不会被重载,那么编译器会对其采用内联调用。
你也可以将本地变量声明为final,同样,这也不会带来性能的提升。使用“final”只能使本地变量看起来更清晰些(但是也有些时候这是必须的,比如在使用匿名内部类的时候)。
2) 使用改进的For循环语法
改进for循环(有时被称为for-each循环)能够用于实现了iterable接口的集 合类及数组中。在集合类中,迭代器让接口调用hasNext()和next()方法。在ArrayList中,手写的计数循环迭代要快3倍(无论有没有 JIT),但其他集合类中,改进的for循环语法和迭代器具有相同的效率。下面展示集中访问数组的方法:
[java] view plaincopy
static class Foo {
int mSplat;
}
Foo[] mArray = ...
public void zero() {
int sum = 0;
for (int i = 0; i < mArray.length; ++i) {
sum += mArray[i].mSplat;
}
}
public void one() {
int sum = 0;
Foo[] localArray = mArray;
int len = localArray.length;
for (int i = 0; i < len; ++i) {
sum += localArray[i].mSplat;
}
}
public void two() {
int sum = 0;
for (Foo a : mArray) {
sum += a.mSplat;
}
}
}
在zero()中,每次循环都会访问两次静态成员变量,取得一次数组的长度。
在one()中,将所有成员变量存储到本地变量。
two()使用了在java1.5中引入的foreach语法。编译器会将对数组的引用和数 组的长度保存到本地变量中,这对访问数组元素非常好。但是编译器还会在每次循环中产生一个额外的对本地变量的存储操作(对变量a的存取)这样会比 one()多出4个字节,速度要稍微慢一些。
3) 避免使用浮点数
通常的经验是,在Android设备中,浮点数会比整型慢两倍,在缺少FPU和JIT的G1上对比有FPU和JIT的Nexus One中确实如此(两种设备间算术运算的绝对速度差大约是10倍)
从速度方面说,在现代硬件上,float和double之间没有任何不同。更广泛的讲,double大2倍。在台式机上,由于不存在空间问题,double的优先级高于float。
但即使是整型,有的芯片拥有硬件乘法,却缺少除法。这种情况下,整型除法和求模运算是通过软件实现的,就像当你设计Hash表,或是做大量的算术那样,例如a/2可以换成a*0.5。
4) 了解并使用类库
选择Library中的代码而非自己重写,除了通常的那些原因外,考虑到系统空闲时会用汇编代码调用来替代library方法,这可能比JIT中生成的等价的最好的Java代码还要好。
i. 当你在处理字串的时候,不要吝惜使用String.indexOf(),String.lastIndexOf()等特殊实现的方法。这些方法都是使用C/C++实现的,比起Java循环快10到100倍。
ii. System.arraycopy方法在有JIT的Nexus One上,自行编码的循环快9倍。
iii. android.text.format包下的Formatter类,提供了IP地址转换、文件大小转换等方法;DateFormat类,提供了各种时间转换,都是非常高效的方法。
详细请参考http://developer.android.com/reference/android/text/format/package-summary.html
iv. TextUtils类
对于字符串处理Android为我们提供了一个简单实用的TextUtils类,如果处理比较简单的内容不用去思考正则表达式不妨试试这个在android.text.TextUtils的类,详细请参考http://developer.android.com/reference/android/text/TextUtils.html
v. 高性能MemoryFile类。
很多人抱怨Android处理底层I/O性能不是很理想,如果不想使用NDK则可以通过MemoryFile类实现高性能的文件读写操作。
MemoryFile适用于哪些地方呢?对于I/O需要频繁操作的,主要是和外部存储相关的 I/O操作,MemoryFile通过将 NAND或SD卡上的文件,分段映射到内存中进行修改处理,这样就用高速的RAM代替了ROM或SD卡,性能自然提高不少,对于Android手机而言同 时还减少了电量消耗。该类实现的功能不是很多,直接从Object上继承,通过JNI的方式直接在C底层执行。
详细请参考http://developer.android.com/reference/android/os/MemoryFile.html
在此,只简单列举几个常用的类和方法,更多的是要靠平时的积累和发现。多阅读Google给的帮助文档时很有益的。
5) 合理利用本地方法
本地方法并不是一定比Java高效。最起码,Java和native之间过渡的关联是有消耗 的,而JIT并不能对此进行优化。当你分配本地资源时(本地堆上的内存,文件说明符等),往往很难实时的回收这些资源。同时你也需要在各种结构中编译你的 代码(而非依赖JIT)。甚至可能需要针对相同的架构来编译出不同的版本:针对ARM处理器的GI编译的本地代码,并不能充分利用Nexus One上的ARM,而针对Nexus One上ARM编译的本地代码不能在G1的ARM上运行。
当你想部署程序到存在本地代码库的Android平台上时,本地代码才显得尤为有用,而并非为了Java应用程序的提速。
6) 复杂算法尽量用C完成
复杂算法尽量用C或者C++完成,然后用JNI调用。但是如果是算法比较单间,不必这么麻烦,毕竟JNI调用也会花一定的时间。请权衡。
7) 减少不必要的全局变量
尽量避免static成员变量引用资源耗费过多的实例,比如Context。Android提供了很健全的消息传递机制(Intent)和任务模型(Handler),可以通过传递或事件的方式,防止一些不必要的全局变量。
8) 不要过多指望gc
Java的gc使用的是一个有向图,判断一个对象是否有效看的是其他的对象能到达这个对象的顶点,有向图的相对于链表、二叉树来说开销是可想而知。所以不要过多指望gc。将不用的对象可以把它指向NULL,并注意代码质量。同时,显示让系统gc回收,例如图片处理时,
[java] view plaincopy
if(bitmap.isRecycled()==false) { //如果没有回收
bitmap.recycle();
}
9) 了解Java四种引用方式
JDK 1.2版本开始,把对象的引用分为4种级别,从而使程序能更加灵活地控制对象的生命周期。这4种级别由高到低依次为:强引用、软引用、弱引用和虚引用。
i. 强引用(StrongReference)
强引用是使用最普遍的引用。如果一个对象具有强引用,那垃圾回收器绝不会回收它。当内存空间不足,Java虚拟机宁愿抛出OutOfMemoryError错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足的问题。
ii. 软引用(SoftReference)
如果一个对象只具有软引用,则内存空间足够,垃圾回收器就不会回收它;如果内存空间不足了,就会回收这些对象的内存。只要垃圾回收器没有回收它,该对象就可以被程序使用。软引用可用来实现内存敏感的高速缓存。
iii. 弱引用(WeakReference)
在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程,因此不一定会很快发现那些只具有弱引用的对象。
iv. 虚引用(PhantomReference)
顾名思义,就是形同虚设。与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收。
了解并熟练掌握这4中引用方式,选择合适的对象应用方式,对内存的回收是很有帮助的。
详细请参考http://blog.csdn.net/feng88724/article/details/6590064
10) 使用实体类比接口好
假设你有一个HashMap对象,你可以将它声明为HashMap或者Map:
[java] view plaincopy
Map map1 = new HashMap();
HashMap map2 = new HashMap();
哪个更好呢?
按照传统的观点Map会更好些,因为这样你可以改变他的具体实现类,只要这个类继承自Map 接口。传统的观点对于传统的程序是正确的,但是它并不适合嵌入式系统。调用一个接口的引用会比调用实体类的引用多花费一倍的时间。如果HashMap完全 适合你的程序,那么使用Map就没有什么价值。如果有些地方你不能确定,先避免使用 Map,剩下的交给IDE提供的重构功能好了。(当然公共API是一个例外:一个好的API常常会牺牲一些性能)
11) 避免使用枚举
枚举变量非常方便,但不幸的是它会牺牲执行的速度和并大幅增加文件体积。例如:
[java] view plaincopy
public class Foo {
public enum Shrubbery { GROUND, CRAWLING, HANGING }
}
会 产生一个900字节的.class文件(Foo$Shubbery.class)。在它被首次调用时,这个类会调用初始化方法来准备每个枚举变量。每个枚 举项都会被声明成一个静态变量,并被赋值。然后将这些静态变量放在一个名为”$VALUES”的静态数组变量中。而这么一大堆代码,仅仅是为了使用三个整 数。
这样:Shrubbery shrub =Shrubbery.GROUND;会引起一个对静态变量的引用,如果这个静态变量是final int,那么编译器会直接内联这个常数。
一方面说,使用枚举变量可以让你的API更出色,并能提供编译时的检查。所以在通常的时候你毫无疑问应该为公共API选择枚举变量。但是当性能方面有所限制的时候,你就应该避免这种做法了。
有些情况下,使用ordinal()方法获取枚举变量的整数值会更好一些,举例来说:
[java] view plaincopy
for(int n =0; n < list.size(); n++) {
if(list.items[n].e == MyEnum.VAL_X) {
// do something
} else if(list.items[n].e == MyEnum.VAL_Y) {
// do something
}
}
替换为:
[java] view plaincopy
int valX = MyEnum.VAL_X.ordinal();
int valY = MyEnum.VAL_Y.ordinal();
int count = list.size();
MyItem items = list.items();
for(int n =0; n < count; n++) {
intvalItem = items[n].e.ordinal();
if(valItem == valX) {
// do something
} else if(valItem == valY) {
// do something
}
}
会使性能得到一些改善,但这并不是最终的解决之道。
12) 在私有内部内中,考虑用包访问权限替代私有访问权限
[java] view plaincopy
public class Foo {
public class Inner {
public void stuff() {
Foo.this.doStuff(Foo.this.mValue);
}
}
private int mValue;
public void run() {
Inner in = new Inner();
mValue = 27;
in.stuff();
}
private void doStuff(int value) {
System.out.println("value:"+value);
}
}
需要注意的关键是:我们定义的一个私有内部类(Foo$Inner),直接访问外部类中的一个私有方法和私有变量。这是合法的,代码也会打印出预期的“Value is 27”。
但问题是,虚拟机认为从Foo$Inner中直接访问Foo的私有成员是非法的,因为他们是两个不同的类,尽管Java语言允许内部类访问外部类的私有成员,但是通过编译器生成几个综合方法来桥接这些间隙的。
[java] view plaincopy
/*package*/static int Foo.access$100(Foo foo) {
return foo.mValue;
}
/*package*/static void Foo.access%200(Foo foo,int value) {
foo.duStuff(value);
}
内部类会在外部类中任何需要访问mValue字段或调用doStuff方法的地方调用这些静态方法。这意味着这些代码将直接存取成员变量表现为通过存取器方法访问。之前提到过存取器访问如何比直接访问慢,这例子说明,某些语言约会定导致不可见的性能问题。
如果你在高性能的Hotspot中使用这些代码,可以通过声明被内部类访问的字段和成员为包访问权限,而非私有。但这也意味着这些字段会被其他处于同一个包中的类访问,因此在公共API中不宜采用。
13) 将与内部类一同使用的变量声明在包范围内
请看下面的类定义:
[java] view plaincopy
public class Foo {
private class Inner {
void stuff() {
Foo.this.doStuff(Foo.this.mValue);
}
}
private int mValue;
public void run() {
Inner in = new Inner();
mValue = 27;
in.stuff();
}
private void doStuff(int value) {
System.out.println("Value is " + value);
}
}
这其中的关键是,我们定义了一个内部类(Foo$Inner),它需要访问外部类的私有域变量和函数。这是合法的,并且会打印出我们希望的结果Value is 27。
问题是在技术上来讲(在幕后)Foo$Inner是一个完全独立的类,它要直接访问Foo的私有成员是非法的。要跨越这个鸿沟,编译器需要生成一组方法:
[java] view plaincopy
/*package*/ static int Foo.access$100(Foo foo) {
return foo.mValue;
}
/*package*/ static void Foo.access$200(Foo foo, int value) {
foo.doStuff(value);
}
内部类在每次访问mValueg和gdoStuffg方法时,都会调用这些静态方法。就是 说,上面的代码说明了一个问题,你是在通过接口方法访问这些成员变量和函数而不是直接调用它们。在前面我们已经说过,使用接口方法(getter、 setter)比直接访问速度要慢。所以这个例子就是在特定语法下面产生的一个“隐性的”性能障碍。
通过将内部类访问的变量和函数声明由私有范围改为包范围,我们可以避免这个问题。这样做可以 让代码运行更快,并且避免产生额外的静态方法。(遗憾的是,这些域和方法可以被同一个包内的其他类直接访问,这与经典的OO原则相违背。因此当你设计公共 API的时候应该谨慎使用这条优化原则)。
14) 缓存
适量使用缓存,不要过量使用,因为内存有限,能保存路径地址的就不要存放图片数据,不经常使用的尽量不要缓存,不用时就清空。
15) 关闭资源对象
对SQLiteOpenHelper,SQLiteDatabase,Cursor,文件,I/O操作等都应该记得显示关闭。
2. 视图优化
1) View优化
i. 减少不必要的View以及View的嵌套层次。
比如实现一个listview中常用的layout,可以使用RelativeLayout减少嵌套,要知道每个View的对象会耗费1~2k内存,嵌套层次过多会引起频繁的gc,造成ANR。
ii. 通过HierarchyViewer查看布局结构
利用HierarchyViewer来查看View的结构:~/tools/hierarchyviewer,能很清楚地看到RelativeLayout下面的扁平结构,这样能加快dom的渲染速度。
详细请参考http://developer.android.com/guide/developing/tools/hierarchy-viewer.html
iii. 通过Layoutopt优化布局
通过Android sdk中tools目录下的layoutopt 命令查看你的布局是否需要优化。详细请参考http://apps.hi.baidu.com/share/detail/34247942
2) 多线程解决复杂计算
占用CPU较多的数据操作尽可能放在一个单独的线程中进行,通过handler等方式把执行的结果交于UI线程显示。特别是针对的网络访问,数据库查询,和复杂的算法。目前Android提供了AsyncTask,Hanlder、Message和Thread的组合。
对于多线程的处理,如果并发的线程很多,同时有频繁的创建和释放,可以通过concurrent类的线程池解决线程创建的效率瓶颈。
另外值得注意的是,应用开发中自定义View的时候,交互部分,千万不要写成线程不断刷新界面显示,而是根据TouchListener事件主动触发界面的更新。
3) 布局用Java完成比XML快
一般情况下对于Android程序布局往往使用XML文件来编写,这样可以提高开发效率,但 是考虑到代码的安全性以及执行效率,可以通过Java代码执行创建,虽然Android编译过的XML是二进制的,但是加载XML解析器的效率对于资源占 用还是比较大的,Java处理效率比XML快得多,但是对于一个复杂界面的编写,可能需要一些套嵌考虑,如果你思维灵活的话,使用Java代码来布局你的 Android应用程序是一个更好的方法。
4) 对大型图片进行缩放
图片读取是OOM(Out of Memory)的常客,当在Android手机上直接读取4M的图片时,死神一般都会降临,所以导致往往自己手机拍摄的照片都不能直接读取。对大型图片进 行缩放有,处理图片时我们经常会用到BitmapFactory类,android系统中读取位图Bitmap时分给虚拟机中图片的堆栈大小只有8M。用 BitmapFactory解码一张图片时,有时也会遇到该错误。这往往是由于图片过大造成的。这时我们需要分配更少的内存空间来存储。 BitmapFactory.Options.inSampleSize设置恰当的inSampleSize可以使BitmapFactory分配更少的 空间以消除该错误。Android提供了一种动态计算的,如下:
读取图片之前先查看其大小:
[java] view plaincopy
BitmapFactory.Options opts = new BitmapFactory.Options();
opts.inJustDecodeBounds = true;
Bitmap bitmap = BitmapFactory.decodeFile(imageFile, opts);
使用得到的图片原始宽高计算适合自己的smaplesize
[java] view plaincopy
BitmapFactory.Options opts = new BitmapFactory.Options();
opts.inSampleSize = 4 ;// 4就代表容量变为以前容量的1/4
Bitmap bitmap = BitmapFactory.decodeFile(imageFile, opts);
对于过时的Bitmap对象一定要及时recycle,并且把此对象赋值为null。
[java] view plaincopy
bitmap.recycle();
bitmap = null;
5) 合理使用ViewStub
ViewStub 是一个隐藏的,不占用内存空间的视图对象,它可以在运行时延迟加载布局资源文件。当ViewStub可见,或者调用 inflate()函数时,才会加载这个布局资源文件。 该ViewStub在加载视图时在父容器中替换它本身。因此,ViewStub会一直存在于视图中,直到调用setVisibility(int) 或者inflate()为止。ViewStub的布局参数会随着加载的视图数一同被添加到ViewStub父容器。同样,你也可以通过使用 inflatedId属性来定义或重命名要加载的视图对象的Id值。所以我们可以使用ViewStub延迟加载某些比较复杂的layout,动态加载 View,采用ViewStub 避免一些不经常的视图长期握住引用。
详细请参考http://developer.android.com/reference/android/view/ViewStub.html
6) 针对ListView的性能优化
i. 复用convertView。
ii. 在getItemView中,判断convertView是否为空,如果不为空,可复用。如果couvertview中的view需要添加 listerner,代码一定要在if(convertView==null){}之外。
iii. 异步加载图片,item中如果包含有web image,那么最好异步加载。
iv. 快速滑动时不显示图片
当快速滑动列表时(SCROLL_STATE_FLING),item中的图片或获取需要消 耗资源的view,可以不显示出来;而处于其他两种状态(SCROLL_STATE_IDLE 和SCROLL_STATE_TOUCH_SCROLL),则将那些view显示出来。
v. item尽可能的减少使用的控件和布局的层次;背景色与cacheColorHint设置相同颜色;ListView中item的布局至关重要,必须尽可 能的减少使用的控件,布局。RelativeLayout是绝对的利器,通过它可以减少布局的层次。同时要尽可能的复用控件,这样可以减少 ListView的内存使用,减少滑动时gc次数。ListView的背景色与cacheColorHint设置相同颜色,可以提高滑动时的渲染性能。
vi. getView优化
ListView中getView是性能是关键,这里要尽可能的优化。getView方法中要重用view;getView方法中不能做复杂的逻辑计算,特别是数据库和网络访问操作,否则会严重影响滑动时的性能。优化如下所示:
[java] view plaincopy
@Override
public View getView(int position, View convertView, ViewGroup parent) {
Log.d("MyAdapter", "Position:" + position + "---" + String.valueOf(System.currentTimeMillis()));
final LayoutInflater inflater = (LayoutInflater) mContext.getSystemService(Context.LAYOUT_INFLATER_SERVICE);
View v = inflater.inflate(R.layout.list_item_icon_text, null);
((ImageView) v.findViewById(R.id.icon)).setImageResource(R.drawable.icon);
((TextView) v.findViewById(R.id.text)).setText(mData[position]);
return v;
}
建议改为:
[java] view plaincopy
@Override
public View getView(int position, View convertView, ViewGroup parent) {
Log.d("Adapter", "Position:" + position + " : " + String.valueOf(System.currentTimeMillis()));
ViewHolder holder;
if (convertView == null) {
final LayoutInflater inflater = (LayoutInflater) mContext.getSystemService(Context.LAYOUT_INFLATER_SERVICE);
convertView = inflater.inflate(R.layout.list_item_icon_text, null);
holder = new ViewHolder();
holder.icon = (ImageView) convertView.findViewById(R.id.icon);
holder.text = (TextView) convertView.findViewById(R.id.text);
convertView.setTag(holder);
} else {
holder = (ViewHolder) convertView.getTag();
}
holder.icon.setImageResource(R.drawable.icon);
holder.text.setText(mData[position]);
return convertView;
}
static class ViewHolder {
ImageView icon;
TextView text;
}
}
以上是Google IO大会上给出的优化建议,经过尝试ListView确实流畅了许多。使用1000条记录,经测试第一种方式耗时:25211ms,第二种方式耗时:16528ms。
7) 其他
i. 分辨率适配
-ldpi,-mdpi, -hdpi配置不同精度资源,系统会根据设备自适应,包括drawable, layout,style等不同资源。
ii. 尽量使用dp(density independent pixel)开发,不用px(pixel)。
iii. 多用wrap_content, fill_parent
iv. 抛弃AbsoluteLayout
v. 使用9patch(通过~/tools/draw9patch.bat启动应用程序),png格式
vi. 采用<merge> 优化布局层数;采用<include >来共享布局。
vii. 将Acitivity中的Window的背景图设置为空。getWindow().setBackgroundDrawable(null);android的默认背景是不是为空。
viii. View中设置缓存属性.setDrawingCache为true。
3. 网络优化
1) 避免频繁网络请求
访问server端时,建立连接本身比传输需要跟多的时间,如非必要,不要将一交互可以做的 事情分成多次交互(这需要与Server端协调好)。有效管理Service 后台服务就相当于一个持续运行的Acitivity,如果开发的程序后台都会一个service不停的去服务器上更新数据,在不更新数据的时候就让它 sleep,这种方式是非常耗电的,通常情况下,可以使用AlarmManager来定时启动服务。如下所示,第30分钟执行一次。
[java] view plaincopy
AlarmManager alarmManager = (AlarmManager) context.getSystemService(Context.ALARM_SERVICE);
Intent intent = new Intent(context, MyService.class);
PendingIntent pendingIntent = PendingIntent.getService(context, 0, intent, 0);
long interval = DateUtils.MINUTE_IN_MILLIS * 30;
long firstWake = System.currentTimeMillis() + interval;
am.setRepeating(AlarmManager.RTC,firstWake, interval, pendingIntent);
2) 数据压缩
传输数据经过压缩 目前大部门网站都支持GZIP压缩,所以在进行大数据量下载时,尽量使用GZIP方式下载,可以减少网络流量,一般是压缩前数据大小的30%左右。
[java] view plaincopy
HttpGet request = new HttpGet("http://example.com/gzipcontent");
HttpResponse resp = new DefaultHttpClient().execute(request);
HttpEntity entity = response.getEntity();
InputStream compressed = entity.getContent();
InputStream rawData = new GZIPInputStream(compressed);
3) 使用线程池
线程池,分为核心线程池和普通线程池,下载图片等耗时任务放置在普通线程池,避免耗时任务阻塞线程池后,导致所有异步任务都必须等待。
4) 选择合适的数据格式传输形式
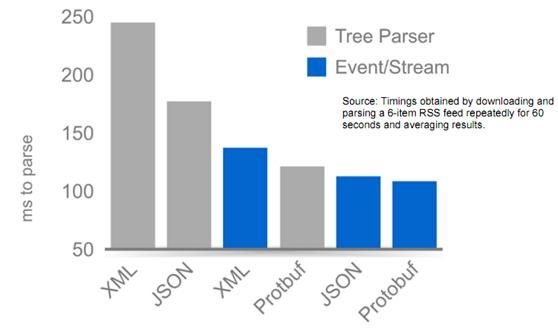
其中Tree Parse 是DOM解析 Event/Stream是SAX方式解析。
很明显,使用流的方式解析效率要高一些,因为DOM解析是在对整个文档读取完后,再根据节点 层次等再组织起来。而流的方式是边读取数据边解析,数据读取完后,解析也就完毕了。在数据格式方面,JSON和Protobuf效率明显比XML好很 多,XML和JSON大家都很熟悉。
从上面的图中可以得出结论就是尽量使用SAX等边读取边解析的方式来解析数据,针对移动设备,最好能使用JSON之类的轻量级数据格式为佳。
1) 其他
设置连接超时时间和响应超时时间。Http请求按照业务需求,分为是否可以缓存和不可缓存,那么在无网络的环境中,仍然通过缓存的HttpResponse浏览部分数据,实现离线阅读。
2. 数据库相关
1) 相对于封装过的ContentProvider而言,使用原始SQL语句执行效率高,比如使用方法rawQuery、execSQL的执行效率比较高。
2) 对于需要一次性修改多个数据时,可以考虑使用SQLite的事务方式批量处理。
3) 批量插入多行数据使用InsertHelper或者bulkInsert方法
4) 有些能用文件操作的,尽量采用文件操作,文件操作的速度比数据库的操作要快10倍左右。
3. 性能测试
对于Android平台上软件的性能测试可以通过以下几种方法来分析效率瓶颈,目前Google在Android软件开发过程中已经引入了多种测试工具包,比如Unit测试工程,调试类,还有模拟器的Dev Tools都可以直接反应执行性能。
1) 在模拟器上的Dev Tools可以激活屏幕显示当前的FPS,CPU使用率,可以帮助我们测试一些3D图形界面的性能。
2) 一般涉及到网络应用的程序,在效率上和网速有很多关系,这里需要多次的调试才能实际了解。
3) 对于逻辑算法的效率执行,我们使用Android上最普遍的,计算执行时间来查看:
[java] view plaincopy
long start = System.currentTimeMillis();
// do something
long duration = System.currentTimeMillis() - start;
最终duration保存着实际处理该方法需要的毫秒数。
4) gc效率跟踪,如果你执行的应用比较简单,可以在DDMS中查看下Logcat的VM释放内存情况,大概模拟下那些地方可以缓存数据或改进算法的。
5) 线程的使用和同步,Android平台上给我们提供了丰富的多任务同步方 法,但在深层上并没有过多的比如自旋锁等高级应用,不过对于Service和 appWidget而言,他们实际的产品中都应该以多线程的方式处理,以释放CPU时间,对于线程和堆内存的查看这些都可以在DDMS中看到。
6) 利用traceview和monkey等工具测试应用。
7) 利用layoutopt和ninepatch等工具优化视图。
4. 结束语
本文给出了一些Android 移动开发中常见的优化方法,多数情况下利用这些优化方法优化后的代码,执行效率有明显的提高,内存溢出情况也有所改善。在实际应用中对程序的优化一定要权 衡是否是必须的,因为优化可能会带来诸如增加BUG,降低代码的可读性,降低代码的移植性等不良效果。
希望不要盲目优化,请先确定存在问题,再进行优化。并且你知道当前系统的性能,否则无法衡量你进行尝试所得到的性能提升。
希望本文能给大家切实带来帮助。欢迎就上述问题进一步交流。如有发现错误或不足,请斧正。