OpenType字库文件
OpenType字库文件
一个OpenType字库文件以表的格式包含有数据,这些数据包含一个TrueType或一个PostScript outline 字库。光栅化程序使用字库里包含的表中的数据来渲染TrueType或者PostScript glyph outline。这些支持数据中的一些无论在那种outline格式中都会用到;而一些支持数据则是特定于TrueType或者PostScript的。
文件名
依赖于字库中outline的种类,和创建者兼容那些本地没有提供OpenType支持的系统的欲望,OpenType字库的扩展名可能是.OTF或者.TTF。
- 在所有的情况下,只包含CFF数据(没有TrueType outlines)的字库其扩展名总是.OTF。
- 依赖于向后兼容更老的系统或者字库的前一个版本的欲望,包含有TrueType outlines的字库其扩展名可能是.OTF或者是.TTF。无论字库中是否包含有OpenType layout的表,TrueType Collection字库的扩展名应该为.TTC。
数据类型
OpenType字库文件中使用了下列的数据类型。所有的OpenType字库使用 Motorola-style字节序(大尾端):
| Data Type | Description |
|---|---|
| BYTE | 8-bit 无符号整型. |
| CHAR | 8-bit 有符号整型. |
| USHORT | 16-bit 无符号整型. |
| SHORT | 16-bit 有符号整型. |
| UINT24 | 24-bit 无符号整型. |
| ULONG | 32-bit 无符号整型. |
| LONG | 32-bit 有符号整型. |
| Fixed | 32-bit 有符号定点数 (16.16) |
| FUNIT | em空间最小可测量距离. |
| FWORD | 以FUnits描述数量的16-bit 有符号整型(SHORT). |
| UFWORD | 以FUnits描述数量的16-bit 无符号整型(SHORT). |
| F2DOT14 | 16-bit有符号定点数,其中低14 bits为小数部分(2.14). |
| LONGDATETIME | 以1904年1月1日凌晨12:00开始计时的秒数形式的日期。这个值用一个有符号64-bit整数表示。Date |
| Tag | 用于标识一个 script, language system, feature, 或 baseline的四unit8值的数组(length = 32 bits)。 |
| GlyphID | Glyph索引值,与uint16(length = 16 bits)相同 |
| Offset | 相对于一个表的偏移,与uint16(length = 16 bits)相同,NULL offset = 0x0000 |
F2DOT14 格式由一个有符号的2的补码形式的定点部分和一个无符号的小数部分组成。为了计算实际值,可以取定点部分加上小数部分。2.14值的一些例子:
| Decimal Value | Hex Value | Mantissa | Fraction |
|---|---|---|---|
| 1.999939 | 0x7fff | 1 | 16383/16384 |
| 1.75 | 0x7000 | 1 | 12288/16384 |
| 0.000061 | 0x0001 | 0 | 1/16384 |
| 0.0 | 0x0000 | 0 | 0/16384 |
| -0.000061 | 0xffff | -1 | 16383/16384 |
| -2.0 | 0x8000 | -2 | 0/16384 |
版本号
大多数表具有版本号,而且整个字库的版本号包含在表目录(Table Directory)中。注意,有两种不同的表版本号类型,它们中的每一个都有其自己的编号模式。USHORT版本号总是以零(0)开始。Fixed 版本号以一(1.0或0x00010000)开始,除非另行说明(EBDT,EBLC和EBSC表)。
实现的读取表的部分必须包含检查版本号的代码,以便于在格式发生了改变,继而版本号也改变了,而这个改变又不兼容的时候,老的实现可以优雅地拒绝新的版本。
当一个Fixed数被用于一个版本号,则高16 bits包含一个主版本号,而低16 bits包含一个次版本号。 Tables with non-zero minor version numbers always specify the literal value of the version number since the normal representation of Fixed numbers is not necessarily followed. 比如,'maxp'表的版本0.5的版本号为0x00005000,'vhea' 表的版本1.1的版本号为0x00011000。如果一个实现理解了一个主版本号,则它可以安全的处理读表的操作。次版本号表示的是对于格式的扩展,这些扩展对于那些不支持它们的实现是无法察觉的。
这个规则仅有的例外是偏移表(Offset Table)的sfnt版本。如下面的部分,'一个OpenType字库的组织',所描述的那样,它仅仅用来表示OpenType字库包含的是TrueType outline(一个1.0的值)还是CFF数据(tag 'OTTO')。
当一个USHORT 数被用来表示版本时,它应该被当作一个次版本号;比如,所有的格式变化都是可兼容的扩展。
一个OpenType字库的组织
OpenType格式的一个重要特征是TrueType sfnt “wrapper”,它提供了以一种通用的和可扩展的方式组织一组表的方法。
OpenType字库含有偏移表(Offset Table)。如果字库文件只包含一个字库,则偏移表(Offset Table)将以文件的0字节为起始位置。如果字库文件是一个TrueType集合,则每一个字库的偏移表(Offset Table)的起始点将在TTCHeader中说明。
| Type | Name | Description |
|---|---|---|
| Fixed | sfnt version | 0x00010000 for version 1.0. |
| USHORT | numTables | 表的个数 |
| USHORT | searchRange | (Maximum power of 2 <= numTables) x 16. |
| USHORT | entrySelector | Log2(maximum power of 2 <= numTables). |
| USHORT | rangeShift | NumTables x 16-searchRange. |
Offset Table
包含TrueType outlines的OpenType字库应该使用1.0作为sfnt版本。包含CFF数据的OpenType字库应该使用tag 'OTTO'作为sfnt 版本号。
注意:Apple的TrueType字库specification允许使用'true'和'typ1'作为sfnt版本。这些版本tag不应该被用在那些包含OpenType表的字库中。
偏移表(Offset Table)后面紧跟着的便是表记录(TableRecord)项。表记录(Table Record)中的项必须以tag的升序排序。表记录(Table Record)中的偏移值以字库文件的开始处来计算。
| Type | Name | Description |
|---|---|---|
| ULONG | tag | 4 -byte identifier. |
| ULONG | checkSum | CheckSum for this table. |
| ULONG | offset | Offset from beginning of TrueType font file. |
| ULONG | length | Length of this table. |
表记录(Table Record)使得一个特定的字库文件只包含他实际需要的那些表成为了可能。因而并没有一个标准的numTables值。Tags是给OpenType字库文件中的表分配的名字。所有的tag名称由四个字符组成。如果后面跟有所需数量的空格的话,名称包含少于4个的字符也可以的。一个字库中定义的所有的tag名称(比如,表名称,feature tags,language tags)必须由ASCII 值在32-126之间的可打印字符构建。
计算校验和
表的校验和是一个给定的表的longs的无符号和。在C中,下面的函数可用于计算一个校验和:
ULONG
CalcTableChecksum(ULONG *Table, ULONG Length)
{
ULONG Sum = 0L;
ULONG *Endptr = Table+((Length+3) & ~3) / sizeof(ULONG);
while (Table < EndPtr)
Sum += *Table++;
return Sum;
}
注意:这个函数暗含着一个表的长度必须是一个四字节的倍数。实际上,如果没有正确填充的话,一个字库不被认为是被正确的结构化了的。所有的表必须以四字节边界开始,而两个表之间剩余的任何空间则以0填充。表记录(table record)中所有的表的长度应该以它们的实际长度来记录(而不是它们填充后的长度)。
为了计算其本身包含有整个字库的checkSumAdjustment 项的‘head’表的校验和,可以像下面这样来做:
- 设置checkSumAdjustment 为0。
- 计算包含‘head’表在内的所有表的校验和,并将其值输入到表目录(table directory)中。
- 计算整个字库的校验和。
- 用16进制值B1B0AFBA减去那个值。
- 将结果存进checkSumAdjustment。
包含有整个字库的checkSumAdjustment 项的‘head’表的校验和在此时是不准确的。那不是问题。不要去改变它。一个应用程序要尝试去验证‘head’表没有被改动过的话,它应该计算不包含checkSumAdjustment 值时那个表的校验和,然后将结果和表目录中的项做比较。
TrueType集合
一个TrueType集合(TTC)是一种用一个文件结构来发布多个OpenType字库的手段。当要一起发布的字库共享许多共有的glyphs的时候,TrueType集合最有用。通过允许多个字库共享glyph集合,TTCs可以有效的节省文件空间。
比如,一组日语的字库可以每一个都有他们自己的kana glyphs的设计,却共享kanji glyphs的相同的设计。通过普通的OpenType字库文件,包含通用的kanji glyphs的仅有的方法就是将它们的glyph数据拷贝进每一个字库。由于kanji代表比kana更多的数据,这将导致大量glyph数据不经济的复制。TTCs被定义出来以解决这个问题。
CFF光栅化程序目前还不支持TTC文件。
TTC文件结构
一个TrueType集合文件包含一个TTCHeader表,在表目录(Table Directories)中包含一个或多个偏移表(Offset Tables),和一定数量的OpenType表。TTCHeader必须要位于TTC文件的开始位置。
TTC文件必须为每一个字库包含一个完整的偏移表(Offset Tables)和表目录(Table Directory)。一个TTC文件表目录(Table Directory)与一个TTF文件的表目录(Table Directory)具有完全相同的格式。一个TTC文件中的所有的表目录(Table Directories)中的表偏移量,都是相对于TTC文件的起始位置计算的。
一个TTC文件中的每一个OpenType表通过每个使用了那些表的字库的偏移表(Offset Table)和表目录(Table Directory)来引用。有些OpenType表必须出现多次,TTC中包含的字库每个一次;而其他的表可能由TTC中的多个字库共享。
比如,考虑一个结合了两个日语字库(Font1和Font2)的TTC文件。两个字库具有不同的kana的设计(Kana1和Kana2),但使用了相同的kanji的设计。那个TTC文件中包含有一个单一的‘glyf’表,其中同时包含有kana和kanji的设计;两个字库的表目录(Table Directory)都指向这个‘glyf’表。但每一个字库的表目录(Table Directory)指向不同的‘cmap’表,‘cmap’表确定了使用的glyph的集合。Font1的'cmap'表为kana glyphs指向 'loca'和 'glyf'表的Kana1区域,同时为kanji glyphs指向kanji区域。Font2的'cmap'表为kana glyphs指向 'loca'和 'glyf'表的Kana2区域,同时为kanji glyphs指向相同的kanji区域。
那些每个字库都应该有其唯一的一份拷贝的表,是那些被系统用来识别字库和它的字符映射的表,包括 'cmap','name',和'OS/2'。那些应该由TTC中的字库共享的表,是那些定义了glyph和指令数据或者使用glyph索引来访问数据的表: 'glyf','loca','hmtx','hdmx','LTSH', 'cvt ', 'fpgm', 'prep', 'EBLC', 'EBDT','EBSC','maxp',等等。实际上两个或多个字库中具有相同数据的任何表均可以共享。
Microsoft 有一个工具来帮助创建.TTC文件。过程包括紧密注意一个字库文件中的glyph重新编号的问题及‘camp’表和其他可能导致的side effects的地方。被合并的字库必须还含有兼容的TrueType指令-即,他们的预定程序(preprograms),函数定义,和控制值必须没有冲突。
TrueType集合文件使用文件名后缀.TTC。
TTC头
有两种版本的TTC头:版本1.0用于不含有数字签名的TTC文件。版本2.0可被用于包含或者不包含数字签名的TTC文件——如果没有签名,则版本2.0头的最后3个成员被留为null。
如果使用了一个数字签名,文件的DSIG表必须是TTC文件中的最后一个表。一个TTC文件中的签名被预期为Format 1签名。
TTCHeader表的目的为定位一个TTC文件内的不同的偏移表(Offset Table)。TTCHeader位于TTC文件的起始位置(offset = 0)。它由一个标识用的tag,一个版本号,一个文件中的OpenType字库的个数值,和一个到每一个偏移表(Offset Table)的偏移量所组成的数组组成。
| Type | Name | Description |
|---|---|---|
| TAG | TTCTag | TrueType Collection ID string: 'ttcf' |
| FIXED | Version | Version of the TTC Header (1.0), 0x00010000 |
| ULONG | numFonts | Number of fonts in TTC |
| ULONG | OffsetTable[numFonts] | Array of offsets to the OffsetTable for each font from the beginning of the file |
| Type | Name | Description |
|---|---|---|
| TAG | TTCTag | TrueType Collection ID string: 'ttcf' |
| FIXED | Version | Version of the TTC Header (2.0), 0x00020000 |
| ULONG | numFonts | Number of fonts in TTC |
| ULONG | OffsetTable[numFonts] | Array of offsets to the OffsetTable for each font from the beginning of the file |
| ULONG | ulDsigTag | Tag indicating that a DSIG table exists, 0x44534947 ('DSIG') (null if no signature) |
| ULONG | ulDsigLength | The length (in bytes) of the DSIG table (null if no signature) |
| ULONG | ulDsigOffset | The offset (in bytes) of the DSIG table from the beginning of the TTC file (null if no signature) |
TTC Header Version 2.0
字库表
如果表都被适当的填充而每一个都以4-byte边界为起始位置,则光栅化程序有一个简单得多的次数来遍历表。强烈建议所有的表都是long对齐并用0填充的。
OpenType表
一个OpenType文件中,无论是TrueType还是PostScript outline都会被用到的表,下面的表是功能正常的字库所必须的:
Required Tables
| Tag | Name |
|---|---|
| cmap | Character to glyph mapping |
| head | Font header |
| hhea | Horizontal header |
| hmtx | Horizontal metrics |
| maxp | Maximum profile |
| name | Naming table |
| OS/2 | OS/2 and Windows specific metrics |
| post | PostScript information |
对于基于TrueType outlines的OpenType字库,需要用到下面的表:
TrueType Outlines相关的表
| Tag | Name |
|---|---|
| cvt | Control Value Table |
| fpgm | Font program |
| glyf | Glyph data |
| loca | Index to location |
| prep | CVT Program |
PostScript字库扩展定义了一个新的表的集合,其中包含特定于PostScript字库的数据,用于替换上面所列的表:
PostScript Outlines相关的表
| Tag | Name |
|---|---|
| CFF | PostScript font program (compact font format) |
| VORG | Vertical Origin |
It is strongly recommended that CFF OpenType fonts that are used for vertical writing include a Vertical Origin ('VORG') table . Multiple Master support in OpenType, has been discontinued as of version 1.3 of the specification. The 'fvar', 'MMSD', 'MMFX' tables have hence been removed.
Bitmap Glyphs相关的表
| Tag | Name |
|---|---|
| EBDT | Embedded bitmap data |
| EBLC | Embedded bitmap location data |
| EBSC | Embedded bitmap scaling data |
OpenType fonts may also contain bitmaps of glyphs, in addition to outlines. Hand-tuned bitmaps are especially useful in OpenType fonts for representing complex glyphs at very small sizes. If a bitmap for a particular size is provided in a font, it will be used by the system instead of the outline when rendering the glyph. (Note: ATM does not currently support hinted bitmaps in OpenType fonts.)
也有一些可选的支持竖直布局和其他高级排版功能的表:
高级排版的表
| Tag | Name |
|---|---|
| BASE | Baseline data |
| GDEF | Glyph definition data |
| GPOS | Glyph positioning data |
| GSUB | Glyph substitution data |
| JSTF | Justification data |
关于通用表格式的信息,请参考 OpenType布局通用表格式 .
其他的OpenType表
| Tag | Name |
|---|---|
| DSIG | Digital signature |
| gasp | Grid-fitting/Scan-conversion |
| hdmx | Horizontal device metrics |
| kern | Kerning |
| LTSH | Linear threshold data |
| PCLT | PCL 5 data |
| VDMX | Vertical device metrics |
| vhea | Vertical Metrics header |
| vmtx | Vertical Metrics |
OpenType字库组织的例子
以Microsoft提供的一个蒙古文字库monbaiti.ttf为例,来看一下OpenType字库文件的组织:
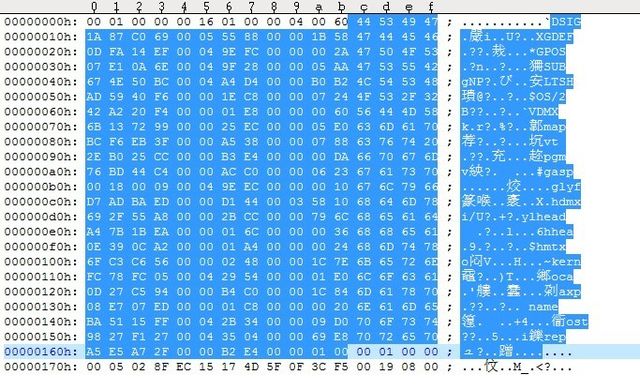
首先,我们从字库文件的开头12个字节中解出来Offset表:
| 类型 | Fixed | USHORT |
USHORT |
USHORT |
USHORT |
| 字段 | sfnt version |
numTables |
searchRange |
entrySelector |
rangeShift |
| 实际值 | 0x00010000 = 1.0 |
0x0016 = 22 | 0x0100 | 0x0004 | 0x0060 |
由Offset表中,我们可以看到,字库文件中主要包含22个表。接下来,我们从字库文件开头的部分中解出这所有的22个Table Record项出来:
| 类型 | ULONG |
ULONG |
ULONG |
ULONG |
| 字段名 | tag |
checkSum |
offset |
length |
| |
0x44534947 = 'DSIG' | 0x1A87C069 | 0x00055588 | 0x00001B58 = 7000 |
| |
0x47444546 = 'GDEF' | 0x0DFA14EF | 0x00049EFC | 0x0000002A = 42 |
| |
0x47504F53 = 'GPOS' | 0x07E10A6E |
0x00049F28 |
0x000005AA = 1450 |
| |
0x47535542 = 'GSUB' | 0x674E50BC | 0x0004A4D4 | 0x0000B0B2 = 45234 |
| |
0x4C545348 = 'LTSH' | 0xAD5940F6 | 0x00001EC8 | 0x00000724 |
| |
0x4F532F32 = 'OS/2' | 0x42A220F4 | 0x000001E8 | 0x00000060 |
| |
0x56444D58 = 'VDMX' | 0x6B137299 | 0x000025EC | 0x000005E0 |
| |
0x636D6170 = 'cmap' | 0xBCF6EB3F | 0x0000A538 | 0x00000788 = 1928 |
| |
0x63767420 = 'cvt' | 0x2EB025CC | 0x0000B3E4 | 0x000000DA |
| |
0x6670676D = 'fpgm' | 0x76BD44C4 | 0x0000ACC0 | 0x00000623 |
| |
0x67617370 = 'gasp' | 0x00180009 | 0x00049EEC | 0x00000010 |
| |
0x676C7966 = 'glyf' | 0xD7ADBAED | 0x0000D144 | 0x00035810 = 219152 |
| |
0x68646D78 = 'hdmx' | 0x692F55A8 | 0x00002BCC | 0x0000796C |
| |
0x68656164 = 'head' | 0xA47B1BEA | 0x0000016C | 0x00000036 |
| |
0x68686561 = 'hhea' | 0x0E390CA2 | 0x000001A4 | 0x00000024 |
| |
0x686D7476 = 'hmtx' | 0x6FC3C656 | 0x00000248 | 0x00001C7E |
| |
0x6B65726E = 'kern' | 0xFC78FC05 | 0x00042954 | 0x000001E0 = 480 |
| |
0x6C6F6361 = 'loca' | 0x0D27C594 | 0x0000B4C0 | 0x00001C84 |
| |
0x6D617870 = 'maxp' | 0x08E707ED | 0x000001C8 | 0x00000020 |
| |
0x6E616D65 = 'name' | 0xBA5115FF | 0x00042B34 | 0x000009D0 |
| |
0x706F7374 = 'post' | 0x9827F127 | 0x00043504 | 0x000069E8 |
| |
0x70726570 = 'prep' | 0xA5E5A72F | 0x0000B2E4 | 0x00000100 |
GDEF,GSUB和GPOS表是OpenType高级排版最重要的几个表,因而值得我们重点关注。 而根据offset值,则可以看出来head表是紧紧跟着这22个TableRecord的那个表。
Done。