核心编程之小结
标准类型共有的内建函数:
Cmp()
Repr()
Str()
Type()
数字类型拥有的内建函数:
Abs()
Coerce():返回一个包含类型转换完毕的两个数值元素的元组。
Divmod()
Pow()
Round(),四舍五入
仅仅适合整数的内建函数:
Oct() 八进制
Hex() 十六进制
Chr() 接受一个数值(0-255)返回一个字符串
Ord()接受一个字符串,返回一个数值(0-255)
Unichr () 接受一个unicode码值返回一个unicode字符
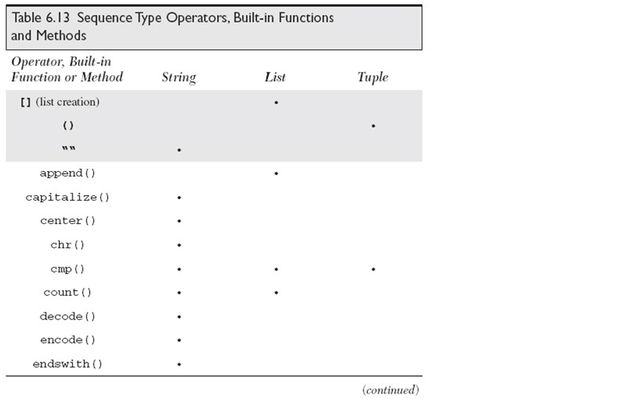
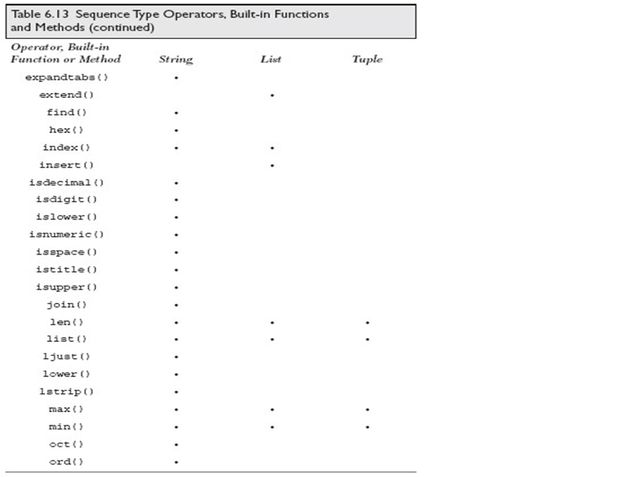
序列包括:字符串,列表,元组
序列类型操作符,内建函数和方法:
序列类型可用的内建函数:
Cmp()
Zip(list1,list2):list1 ,list2的元素必须相同,跟拉锁差不多的意思
接受一个可迭代对象作为参数,返回一个enumerate 对象(同
Enumerate(iter): 时也是一个迭代器),该对象生成由iter 每个元素的index 值和item 值组成的元组
Len(seq):
Max(iter,key=None) 返回iter 或(arg0,arg1,...)中的最大值,如果指定了key,
这个key 必须是一个可以传给sort()方法的,用于比较的回调函数.
Min(),reversed(seq).sorted(),sum(),zip()
只适合字符串的操作符:
1. 格式化操作符%
2. 格式化字符 转换方式
| %c |
转换成字符(ASCII 码值,或者长度为一的字符串)
|
| %r |
优先用repr()函数进行字符串转换 |
| %s |
优先用str()函数进行字符串转换 |
| %d / %i |
转成有符号十进制数 |
| %o |
转成无符号八进制数 |
| %ob %xb/%Xb (Unsigned) |
转成无符号十六进制数(x/X 代表转换后的十六进制字符的大小写)
|
| %e/%E |
转成科学计数法(e/E 控制输出e/E)
|
| %f/%F |
转成浮点数(小数部分自然截断)
|
| %g/%G |
%e 和%f/%E 和%F 的简写
|
| %% |
输出% |
|
|
|
格式化操作符辅助指令:
| 符号 |
作用 |
| * |
定义宽度或者小数点精度 |
| - |
用做左对齐 |
| + |
在正数前面显示加号( + ) |
| <sp> |
在正数前面显示空格 |
| # |
在八进制数前面显示零('0'),在十六进制前面显示'0x'或者'0X'(取决于用的是'x'还是'X') |
| 0 |
显示的数字前面填充‘0’而不是默认的空格 |
| % |
'%%'输出一个单一的'%' |
| (var) |
映射变量(字典参数) |
| M,n |
m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) |
列表:
内建函数:
Cmp()
Len(),max(),min(),enumerate(),zip()
Sum()
注意到这些内建函数都是序列类型 共有的,列表没有自己的专有的内建函数。
元组:元组的对象和序列类型操作符还有内建函数跟列表的完全一样

映射和集合类型
映射类型:字典
映射类型内建函数:
Cmp()
Repr()
Str()
Type(),len(),hash()
集合类型:
集合操作符和关系符号
数学符号 python符号 说明

标准类型操作符(所有的集合类型)
| 函数名 |
等价运算符 |
说明 |
| Len(s) |
|
集合基数: 集合s 中元素的个数 |
| Set([obj]) |
|
可变集合工厂函数; obj 必须是支持迭代的,由obj 中的元素创建集合,否则创建一个空集合 |
|
|
|
|
| Frozenset([obj]) |
|
不可变集合工厂函数; 执行方式和set()方法相同,但它返回的是不可变集合 |
|
|
obj in s |
成员测试:obj 是s 中的一个元素吗? |
| obj not in s |
非成员测试:obj 不是s 中的一个元素吗? |
|
| s.issubset(t) |
s == t |
等价测试: 测试s 和t 是否具有相同的元素? |
| s != t |
不等价测试: 与==相反 |
|
| s < t |
(严格意义上)子集测试; s != t 而且s 中 所 有的元素都是t 的成员 |
|
| s <= t |
子集测试(允许不严格意义上的子集): s 中所有的元素 都是t 的成员 |
|
| s.issuperset(t) |
s > t |
(严格意义上)超集测试: s != t 而且t 中所有的元素 都是s 的成员 |
| s >= t |
超集测试(允许不严格意义上的超集): t 中所有的元素 都是s 的成员 |
|
| s.union(t) |
s | t |
合并操作:s 或t 中的元素 |
| s.intersec-tion(t) |
S&t |
合并操作:s 或t 中的元素 |
| s.difference(t) |
s-t |
差分操作: s 中的元素,而不是t 中的元素 |
| s.symmetric_difference(t) |
s ^ t |
对称差分操作:s 或t 中的元素,但不是s 和t 共有 的元素 |
| s.copy() |
|
复制操作:返回s 的(浅复制)副本 |
|
|
|
|
仅用于可变集合
| 函数/方法名字 |
操作符 |
等价描述 |
| s.update(t) |
s |= t |
(Union) 修改操作: 将t 中的成员添加s |
| s.intersection_update(t) |
s &= t |
交集修改操作: s 中仅包括s 和t 中共有的成员 |
| s.difference_update(t) |
s -= t |
差修改操作: s 中包括仅属于s 但不属于t 的成员 |
| s.symmetric_ difference_ update(t) |
s ^= t |
对称差分修改操作: s 中包括仅属于s 或仅属于t 的成员 |
| s.add(obj) |
|
加操作: 将obj 添加到s |
| s.remove(obj) |
|
删除操作: 将obj 从s 中删除;如果s 中不存在obj,将引发KeyError |
| s.discard(obj) |
|
丢弃操作: remove() 的 友 好 版 本 - 如 果 s 中存在obj,从s 中删除它 |
| s.pop() |
|
Pop 操作: 移除并返回s 中的任意一个元素 |
| s.clear() |
|
清除操作: 移除s 中的所有元素 |
|
|
|
|
|
|
|
|
迭代器:iter(),next()
reversed() 内建函数将返回一个反序访问的迭代器. enumerate() 内建函数同样也返回迭代器.另外两个新的内建函数, any() 和 all()
example:
>>> myTuple = (123, 'xyz', 45.67)
>>> i=iter(myTuple)
>>> i.next()
123
>>> i.next()
'xyz'
>>> i.next()
45.67
>>> i.next()
Traceback (most recent call last):
File "<pyshell#13>", line 1, in <module>
i.next()
StopIteration
对一个对象调用 iter() 就可以得到它的迭代器. 它的语法如下:
iter(obj)
iter(func, sentinel )
如果你传递一个参数给 iter() , 它会检查你传递的是不是一个序列, 如果是, 那么很简单:根据索引从 0 一直迭代到序列结束. 另一个创建迭代器的方法是使用类, 一个实现了 __iter__() 和 next() 方法的类可以作为迭代器使用.
实例:
class iterclass(object):
def __init__(self,seq):
self.iter=iter(seq)
def __iter__(self):
return self
def __str__(self):
return str(self.data)
def next(self):
return self.iter.next()
i=iterclass([1,2,3,5,9,8])
for t in i:
print t
文件 类型的内建函数:
open(),file()
文件对象的访问模式:
| 文件模式 |
操作 |
| r |
以读方式打开 |
| rU 或 Ua |
以读方式打开, 同时提供通用换行符支持 (PEP 278) |
| w |
以写方式打开 (必要时清空) |
| a |
以追加模式打开 (从 EOF 开始, 必要时创建新文件) |
| r+ |
以读写模式打开 |
| w+ |
以读写模式打开 (参见 w ) |
| a+ |
以读写模式打开 (参见 a ) |
| rb |
以二进制读模式打开 |
| wb |
以二进制写模式打开 (参见 w ) |
| ab |
以二进制追加模式打开 (参见 a ) |
| rb+ |
以二进制读写模式打开 (参见 r+ ) |
| ab+ |
以二进制读写模式打开 (参见 a+ ) |
| wb+ |
以二进制读写模式打开 (参见 w+ ) |
os 模块属性 描述
linesep 用于在文件中分隔行的字符串
sep 用来分隔文件路径名的字符串
pathsep 用于分隔文件路径的字符串
curdir 当前工作目录的字符串名称
pardir (当前工作目录的)父目录字符串名称
os 模块的文件/目录访问函数
| 函数 |
描述 |
| 文件处理 |
|
| mkfifo()/mknod()a |
创建命名管道/创建文件系统节点 |
| remove()/unlink() |
Delete file 删除文件 |
| rename()/renames()b |
重命名文件 |
| *statc() |
返回文件信息 |
| symlink() |
创建符号链接 |
| utime() |
更新时间戳 |
| tmpfile() |
创建并打开('w+b')一个新的临时文件 |
| walk()a |
生成一个目录树下的所有文件名 |
| chdir()/fchdir()a |
改变当前工作目录/通过一个文件描述符改变当前工作目录 |
| chroot()d |
改变当前进程的根目录 |
| listdir() |
列出指定目录的文件 |
| getcwd()/getcwdu() |
返回当前工作目录/功能相同, 但返回一个 Unicode 对象 |
| mkdir()/makedirs() |
创建目录/创建多层目录 |
| rmdir()/removedirs() |
删除目录/删除多层目录 |
| 访问/权限 |
|
| access() |
检验权限模式 |
| chmod() |
改变权限模式 |
| chown()/lchown()a |
改变 owner 和 group ID/功能相同, 但不会跟踪链接 |
| umask() |
设置默认权限模式 |
| 文件描述符操作 |
|
| open() |
底层的操作系统 open (对于文件, 使用标准的内建 open() 函数) |
| read()/write() |
根据文件描述符读取/写入数据 |
| dup()/dup2() |
复制文件描述符号/功能相同, 但是是复制到另一个文件描述符 |
| 设备号 |
|
| makedev()a |
从 major 和 minor 设备号创建一个原始设备号 |
| major()a /minor()a |
从原始设备号获得 major/minor 设备号 |
| os.path 模块中的路径名访问函数 |
|
| 函数 |
描述 |
| 分隔 |
|
| basename() |
去掉目录路径, 返回文件名 |
| dirname() |
去掉文件名, 返回目录路径 |
| join() |
将分离的各部分组合成一个路径名 |
| split() |
返回 (dirname(), basename()) 元组 |
| splitdrive() |
返回 (drivename, pathname) 元组 |
| splitext() |
返回 (filename, extension) 元组 |
| 信息 |
|
| getatime() |
返回最近访问时间 |
| getctime() |
返回文件创建时间 |
| getmtime() |
返回最近文件修改时间 |
| getsize() |
返回文件大小(以字节为单位) |
| 查询 |
|
| exists() |
指定路径(文件或目录)是否存在 |
| isabs() |
指定路径是否为绝对路径 |
| isdir() |
指定路径是否存在且为一个目录 |
| isfile() |
指定路径是否存在且为一个文件 |
| islink() |
指定路径是否存在且为一个符号链接 |
| ismount() |
指定路径是否存在且为一个挂载点 |
| samefile() |
两个路径名是否指向同个文件 |
函数的内建函数:
内建函数apply()、filter()、map()、reduce()
| 内建函数 |
描述 |
| apply(func[, nkw][, kw]) |
用可选的参数来调用func,nkw 为非关键字参数,kw 关键字参数;返回值是函数调用的返回值 |
| filter(func, seq) |
调用一个布尔函数func 来迭代遍历每个seq 中的元素; 返回一个使func 返回值为ture 的元素的序列。 |
| map(func, seq1[,seq2...]) |
将函数func 作用于给定序列(s)的每个元素,并用一个列表来提供返回值;如果func 为None, func 表现为一个身份函数,返回一个含有每个序列中元素集合的n 个元组的列表。 |
| reduce(func, seq[, init]) |
将二元函数作用于seq 序列的元素,每次携带一对(先前的结果以及下一个序列元素),连续的将现有的结果和下雨给值作用在获得的随后的结果上,最后减少我们的序列为一个单一的返回值;如果初始值init 给定,第一个比较会是init 和第一个序列元素而不是序列的头两个元素。 |