EMC Sym V-Max漫谈 ccNUAM到存储来了
最近呢,EMC 公司发布了自己的新一代存储 产品,叫Symmetrix V-Max,趁着五一时光研究了一下,一些小的体会和大家分享。注明:以下纯属个人观点,欢迎友好讨论,恶意攻击的无聊人士请识相走开。
以下是emc历年来的产品发布历史:
1990 �C Symmetrix 4200 �C ICDA (Integrated Cached Disk Array) Technology, Total Capacity 24GB
1991 �C Symmetrix 4200 �C 4Mb DRAM, 5.25 HDAs, Mirroring RAID 1
1992 �C Symmetrix 4400 - - Dynamic Sparing, RMP Call Home
1993 �C Symmetrix 4800 �C 16MB DRAM, 1 GB Global Memory,Non-disruptive microcode, Hypervolume Extension.
1994 �C Symmetrix 5500-3 �C SRDF
1995 �C Symmetrix 3.0 Open Symmetrix- FWD SCSI- attach, 3.5’’ HDAs, RAID Protection, SRDF Host Component, Symmetrix Manager
1996 �C Symmetrix ESP �C Mix CKD/FBA
1997 �C Symmetrix 4.0 �C TimeFinder, DataReach, InfoMover, Celerra, FDRSOS, Fibre Channel, PowerPath, UltraSCSI, DMSP
1998 �C Symmetrix 4.8 �C FC-AL/FC-SW, Symmetrix Optimizer
1999 �C Symmetrix 5.0 �C 333 MHz PPC, 181 GB disks, QoS Controls
2000- Symmetrix 5.5 �C 2 GB fibre Channel, 400 MHz PPC
2000-2001 �C Symmetrix DMX �C Direct Matrix, 500 MHz PPC, 2 GB FC, Back-End Parity RAID
2001 �C 2002 �C Symmetrix DMX �C 2G FICON, Giga Ethernet SRDF, iSCSI, SRDF/A, TimeFinder/Snap
2003- Symmetrix DMX-2 �C 1 Ghz PPC, RAID 5 Data Protection, 32 GB Memory Directors
2003-2004- Symmetrix DMX-2- SRDF Mode Change, Concurrent SRDF, SRDF/Star, TimeFinder/Clone, Open Replicator
2005 �C Symmetrix DMX-3 �C 8 Processors/Directors, 1.3 GHz PPC, Low Cost FC Disks, Incremental Scalable, Upto 2400 disks, Open Migrator/LM
2005-2006 �C Symmetrix DMX-3 �C Dynamic Cache Partitioning, Symmetrix Priority Controls, Virtual LUN Technology, Symmetrix Service Credential, Tamper Proof Audit Logs, Secure Data Eraser, RAID 6 Protections.
2007- 2008 Symmetrix DMX-4 �C 4GB/s Point to point Backend, FC & SATA Intermix, RSA enVision
1991 �C Symmetrix 4200 �C 4Mb DRAM, 5.25 HDAs, Mirroring RAID 1
1992 �C Symmetrix 4400 - - Dynamic Sparing, RMP Call Home
1993 �C Symmetrix 4800 �C 16MB DRAM, 1 GB Global Memory,Non-disruptive microcode, Hypervolume Extension.
1994 �C Symmetrix 5500-3 �C SRDF
1995 �C Symmetrix 3.0 Open Symmetrix- FWD SCSI- attach, 3.5’’ HDAs, RAID Protection, SRDF Host Component, Symmetrix Manager
1996 �C Symmetrix ESP �C Mix CKD/FBA
1997 �C Symmetrix 4.0 �C TimeFinder, DataReach, InfoMover, Celerra, FDRSOS, Fibre Channel, PowerPath, UltraSCSI, DMSP
1998 �C Symmetrix 4.8 �C FC-AL/FC-SW, Symmetrix Optimizer
1999 �C Symmetrix 5.0 �C 333 MHz PPC, 181 GB disks, QoS Controls
2000- Symmetrix 5.5 �C 2 GB fibre Channel, 400 MHz PPC
2000-2001 �C Symmetrix DMX �C Direct Matrix, 500 MHz PPC, 2 GB FC, Back-End Parity RAID
2001 �C 2002 �C Symmetrix DMX �C 2G FICON, Giga Ethernet SRDF, iSCSI, SRDF/A, TimeFinder/Snap
2003- Symmetrix DMX-2 �C 1 Ghz PPC, RAID 5 Data Protection, 32 GB Memory Directors
2003-2004- Symmetrix DMX-2- SRDF Mode Change, Concurrent SRDF, SRDF/Star, TimeFinder/Clone, Open Replicator
2005 �C Symmetrix DMX-3 �C 8 Processors/Directors, 1.3 GHz PPC, Low Cost FC Disks, Incremental Scalable, Upto 2400 disks, Open Migrator/LM
2005-2006 �C Symmetrix DMX-3 �C Dynamic Cache Partitioning, Symmetrix Priority Controls, Virtual LUN Technology, Symmetrix Service Credential, Tamper Proof Audit Logs, Secure Data Eraser, RAID 6 Protections.
2007- 2008 Symmetrix DMX-4 �C 4GB/s Point to point Backend, FC & SATA Intermix, RSA enVision
罗罗嗦嗦讲了这么多,到了最近EMC突然发布了一个新的东东,叫做什么V MAX,先到各大IT网址上面找找,这是个什么东西呢,以下是一些典型的定位:EMC推出针对虚拟 数据 中心的新存储 系统 ,EMC主席兼首席执行官Joe Tucci在 在线 虚拟会议上向记者、分析师和IT管理员们表示该系统是"自Symmetrix系统诞生18年来最重要的Symmetrix创新。"他表示IT管理员可以利用V-Max和 VMware 的Virtual Data Center Operating System(虚拟数据中心操作系统)来构建内部基于云的虚拟系统,而这种系统将比当前系统更加灵活而有效。他说:"它是IT业最先进的存储系统。"哇噻,如此诱惑的文字,那么这个V MAX到底是个什么东东呢....
先抛出俺的观点...V-Max只是一个numa体系架构的多CPU intel服务器而已。类似于90年代Sequent numa机或者2000年代的SGI的Origin服务器或者Altrix服务器,也有点类似于 ibm 当年的SP 节点机。只可惜Sequent早被IBM收购,SGI也与最近被收购,至于IBM的SP节点机,除了当年有个“深蓝”战胜棋王的故事外,在ibm的产品线中早就被抛弃得无影无踪了....numa结构对于超级计算来说有些用处(只可惜SGI信错了安腾芯片,搞了半天安腾的芯片也和MIPS芯片一样还是打不过IBM的pwoer芯片),但是对于OLTP应用来说缺并不是一个很好的 选择 ...
诸位看官估计亲E派已经要抛砖头了,别急,什么叫numa呢....先让俺翻翻十年前俺做超级 计算机 解决方案的资料,翻出来给大家瞅瞅:
均匀访存模型(UMA:Uniform. Memory Access或者叫SMP):内存模块与计算结点分离,分别位于互联 网络 的两侧(图2.2.1),互联网络一般采用系统总线、交叉开关和多级网络,称之为紧耦合系统(Tightly Coupled System)。具有如下特征:
1 物理存储器被所有结点均匀共享;
2 所有结点访问任意存储单元的 时间 相同;
3 访存竞争时,仲裁策略对每个结点均是机会等价的;
4 各结点的CPU可带有局部私有高速缓存(Cache);
5 外围I/O设备也可以共享,且对各结点等价。
1 物理存储器被所有结点均匀共享;
2 所有结点访问任意存储单元的 时间 相同;
3 访存竞争时,仲裁策略对每个结点均是机会等价的;
4 各结点的CPU可带有局部私有高速缓存(Cache);
5 外围I/O设备也可以共享,且对各结点等价。
非均匀访存模型(NUMA:Nonuniform. Memory Access):内存模块局部在各个结点内部(图2.2.2),所有局部内存模块构成并行机的全局内存模块。具有如下特征:
1 任意结点可以直接访问任意内存模块;
2 结点访问内存模块的时间不一致:访问本地存储模块的速度一般是访问其他结点内存模块的3倍以上;
3 访存竞争时,仲裁策略对结点可能是不等价的;
4 各结点的CPU可带有局部私有高速缓存(Cache);
5 外围I/O设备也可以共享。
1 任意结点可以直接访问任意内存模块;
2 结点访问内存模块的时间不一致:访问本地存储模块的速度一般是访问其他结点内存模块的3倍以上;
3 访存竞争时,仲裁策略对结点可能是不等价的;
4 各结点的CPU可带有局部私有高速缓存(Cache);
5 外围I/O设备也可以共享。
Cache一致性非均匀访存模型(CC-NUMA:Coherent-Cache Nonuniform. Memory Access):存在专用硬件设备保证在任意时刻,各结点Cache中数据与全局内存数据的一致性,具有特征:
1 各CPU的局部Cache数据来源于全局内存,并保证所有结点中数据的一致性;
2 大多数访存可以局部在本地高速Cache;
3 基于目录的Cache一致性协议
1 各CPU的局部Cache数据来源于全局内存,并保证所有结点中数据的一致性;
2 大多数访存可以局部在本地高速Cache;
3 基于目录的Cache一致性协议
请注意以前EMC的存储器产品线主要分成两块Symmetrix高端而Clarion是模块化,但是从DMX800、1000、2000系列发布后,EMC逐步用所谓直连矩阵DMX概念来强化其高端的地位(如DMX3 DMX4),可是到了这一代,DMX不见了,也不叫 DMX 5了,却又把Symmetrix这个老名头拿出来了,为什么呢(借用小沈阳的名言),因为存储其实也是计算机,特别是高端存储,从本质上来说也就是一台多CPU耦合的共享内存的一台“大计算机”,EMC从90年代起采用的是多总线 技术 来把多个powerpc和host direcotr和disk director连接起来,由于总线速度的限制Symmetrix 4000到8000系列所采用的总线式架构已经走到尽头,只好另寻出路;从DMX开始弄了个所谓的直连架构,弄了几代以后也弄不下去了(熟悉体系结构的可以看到从第一代DMX到DMX4,整个DMX矩阵除了一次频率升级以外没有太大变化,磁盘缺从DMX2-P的288块直奔1920块)从DMX第一代到DMX 4直连矩阵体系架构看来也到了尽头,但是从本质来说都是采用SMP体系架构,SMP对称式共享存储:任意处理器可直接访问任意内存地址,且访问延迟、带宽、几率都是相同的,因此非常适合于OLTP的多应用访问;而这一次的V代表第五代或者流行的所谓“虚拟化”,Max=Matrix?自己做不出无阻塞交换背板,也不好意思说采用crossbar架构(这么多年一直攻击crossbar架构),因此OEM第三方RapidIO公司的交换设备作为其NUMA体系中的通讯方式,2.5G serial RapidIO v1.3。(参考 http://www.rapidio.org/ ) 。可以说这一次EMC抛弃了以前的SMP架构,转向了numa,那么numa真的适合于 数据库 应用么?另外这次vmax的核心底板是采用了别人的产品 rapidio,而不是自己研发了,大存储缺少背板这个核心技术就像主机缺少自己的芯片研发一样不能说不是一个遗憾。
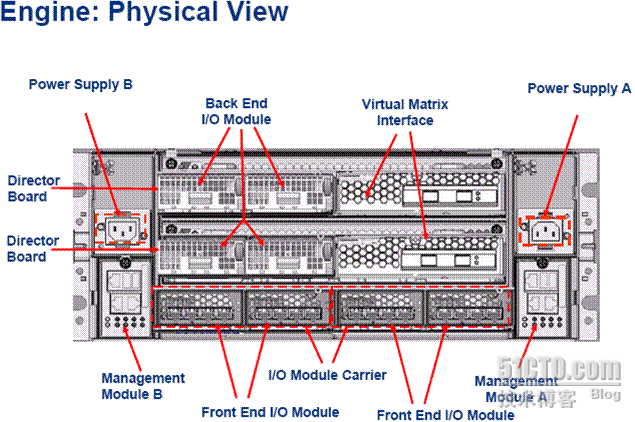
先来看看V-MAX的存储引擎本质上是什么:
是什么呢,其实每个节点和CX4很类似,拥有48到360个磁盘,一个单一的V-Max引擎,两对导向器,并支持Ficon、光纤通道、iSCSI(互联网小型计算机系统接口)和GB级以太网连接。在一个节点或者说是SE engine内访问时还是非常快速的,但是扩到多个节点的时候,整个VMAX有很多特殊的限制,我给大家归纳一下(实在贴图不方便,我就写下来把)
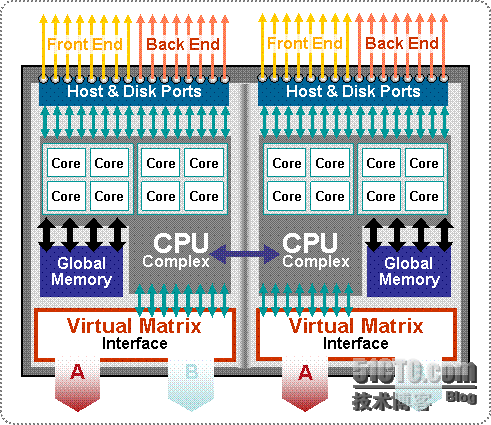
1 每个VMAX的缓存(即那个pc服务器的内存)分成3个部分:cs主要是存放微码;S&F缓存是做存储转发();而GM代表的global memory。V-Max systems use a store-and-forward (S&F) architecture. In this version of the microcode, all I/O is completed from the local S&F buffer, and then is moved to the relevant Global Memory space. Note that since Global Memory is distributed, the relevant Global Memory space may reside either on the Director that received the I/O, or on a different Director.
2 Sym VMAX
•
依然没改正上一代读写
IO
全镜像的缺陷,缓存资源浪费很大,而
控制和数据缓存空间和缓存通道都不分离,效率不高
3 至少每两个引擎的缓存配置必须是一样的;这意味着每个引擎的缓存配置固定,不能灵活升级缓存空间;由于采用跨引擎缓存镜像机制,意味着当扩展到多个引擎,第一个引擎的缓存需要重分配,势必影响第一个引擎的正常的IO响应
4 正因为这些原因,当本地节点缓存访问不命中时,整个缓存机制将非常复杂(这是numa结构所导致的,ccnuma本身就决定了远程访问缓存的时延较大且不可控)。更加要命的是当有多个存储节点SE时,v max规定一个节点的缓存将会强行跨节点镜像,因此。。。不具备SMP的天生优势(缓存访问),因此我前文说过numa不适合商业计算,更加适合高性能计算。
另外呢我本来很想一幅幅的图和大家详细分析v max,无奈本人太笨,实在不知道怎么弄这个博客,贴图要么就贴在一起,要么就贴不上,很多图干脆就不弄了,后面统一贴图上来,大家将就看把。
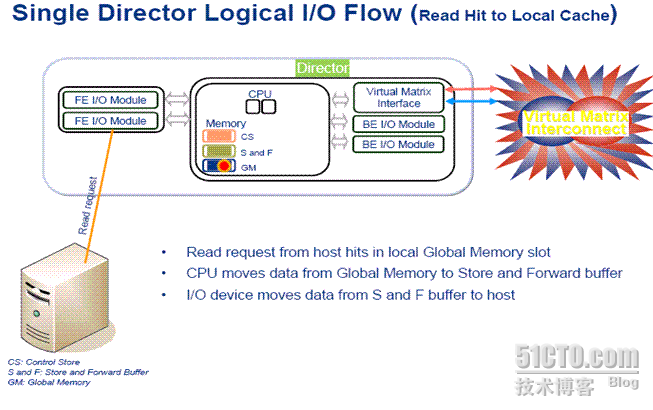
1 本地缓存板命中,反应迅速
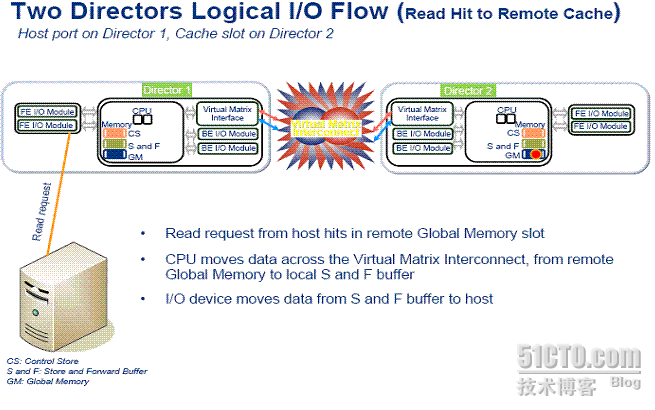
2 远程缓存板命中,跨越背板造成延迟
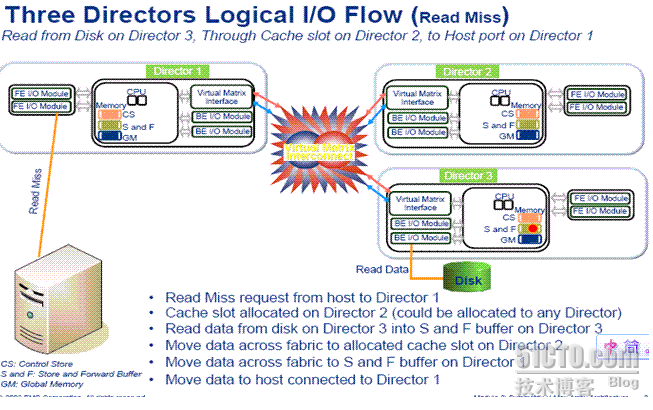
3 缓存不命中,IO需跨越多个引擎,复杂低效
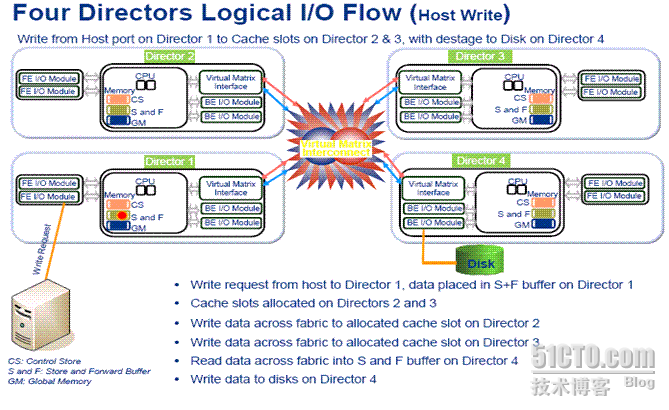
4 写操作跨多引擎,低效复杂且耗费大量内部带宽