Nutch 安装文档
安装Cygwin
我们可以到Cygwin的官方网站下载Cygwin的安装程序,地址是:
至此,笔者还要对Cygwin再多说几句。Cygwin是一个在Windows平台上模拟运行Unix的环境,用户可以通过它来熟悉与学习Unix系统的操作。对于Unix系统还不甚熟悉的读者可以参阅笔者之前写作的《 Unix 操作系统的入门与基础》、《 Unix 的轻巧“约取而实得”》系列文章,下文中对涉及使用到的Unix命令将不再给予详细解释。
2、安装 Nutch
去http://mirror.vmmatrix.net/apache/lucene/ nutch/下载到 Nutch的最新版本,将其解压到指定目录中,如笔者是将其解压到I:\ nutch-0.7.1中。
3、测试 Nutch命令
在运行 Nutch的脚本命令前,需要设置一些环境变量。Cygwin提供了一个名为cygwin.bat的文件,通过它可以自动完成必需环境变量的设置。该文件可在cygwin所在的根目录下找到,感兴趣的读者还可通过UltraEdit等编辑器打开该文件一查究竟。其实Cygwin安装完成之后,会在Windows系统桌面生成一图标,如图8所示:
此图标就是cygwin根目录下cygwin.bat文件的快捷方式,双击此图标将打开一类似DOS窗口。由于先前笔者将 Nutch的压缩包解压至I:\ nutch-0.7.1中,故在此命令窗口中输入命令“cd /cygdrive/i/ nutch-0.7.1”,读者可根据自己的安装路径进行相应的修改,然后使用命令“ls -l”可查看 nutch-0.7.1中的所有子目录及文件信息。执行命令“bin/ nutch”,如果读者能看到如图9所示的提示,那恭喜你, Nutch在Windows系统中的安装已经大功告成了!
http://www.cygwin.com/
或者直接使用下载连接来下载安装程序,下载连接是:
http://www.cygwin.com/setup.exe
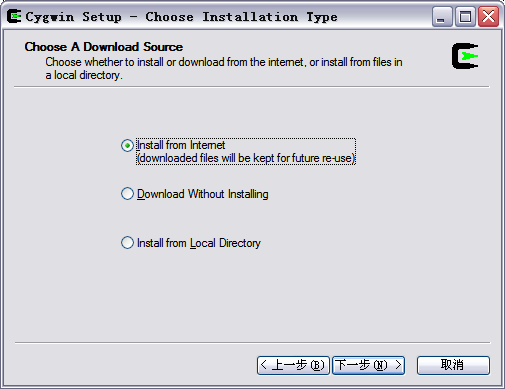
下载完成后,运行setup.exe程序,出现安装画面。直接点“下一步”,出现安装模式的对话框,如下图所示:
我们看到有三种安装模式:
- Install from Internet,这种模式直接从Internet安装,适合网速较快的情况;
- Download Without Installing,这种模式只从网上下载Cygwin的组件包,但不安装;
- Install from Local Directory,这种模式与上面第二种模式对应,当你的Cygwin组件包已经下载到本地,则可以使用此模式从本地安装Cygwin。
从上述三种模式中选择适合你的安装模式,这里我们选择第一种安装模式,直接从网上安装,当然在下载的同时,Cygwin组件也保存到了本地,以便以后能够再次安装。选中后,点击“下一步”,
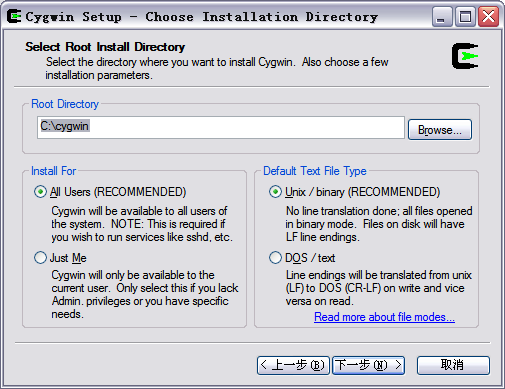
这一步选择Cygwin的安装目录,以及一些参数的设置。默认的安装位置是C:\cygwin\,你也可以选择自己的安装目录,然后选择“下一步”,
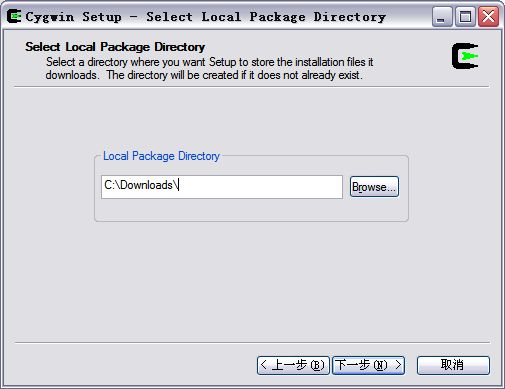
这一步我们可以选择安装过程中从网上下载的Cygwin组件包的保存位置,选择完以后,点击“下一步”,
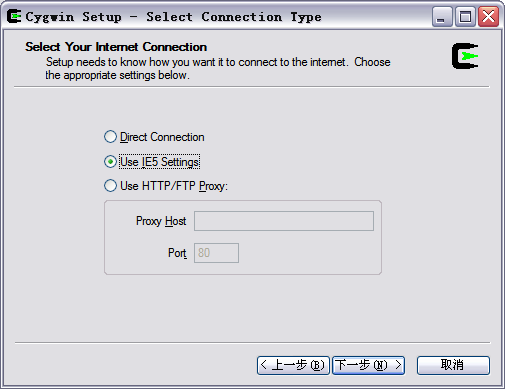
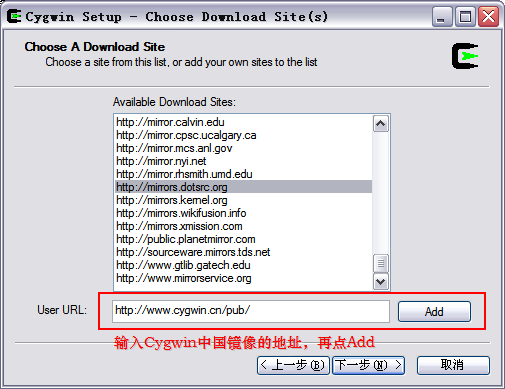
这一步选择连接的方式,选择你的连接方式,然后点击下一步,会出现选择下载站点的对话框,如下图所示,
在这一步,需要注意,为了获得最快的下载速度,我们首先在列表中寻找Cygwin中国镜像的地址:http://www.cygwin.cn,如果找到就选中这个地址;如果找不到这个地址,就在下面手动输入中国镜像的地址:http://www.cygwin.cn/pub/,再点击“Add”,然后再在列表中选中。选择完成后,点击“下一步”,
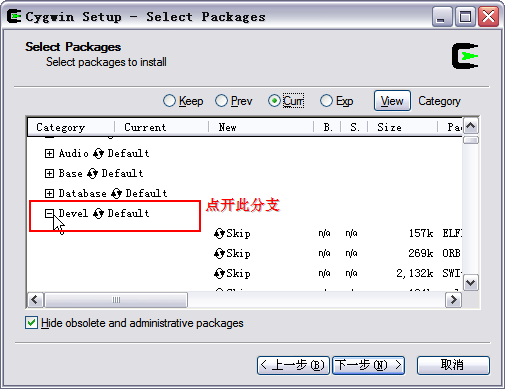
这一步,我们选择需要下载安装的组件包,为了使我们安装的Cygwin能够编译程序,我们需要安装gcc编译器,默认情况下,gcc并不会被安装,我们需要选中它来安装。为了安装gcc,我们用鼠标点开组件列表中的“Devel”分支,在该分支下,有很多组件,我们必须的是:
binutils
gcc
gcc-mingw
gdb
gcc
gcc-mingw
gdb
鼠标点击组件前面的循环按钮,会出现组建的版本日期,我们选择最新的版本安装,下图是选中后的四类组件的截图:
 binutils组件 |
 gcc组件 |
 gcc-mingw组件 |
 gdb组件 |
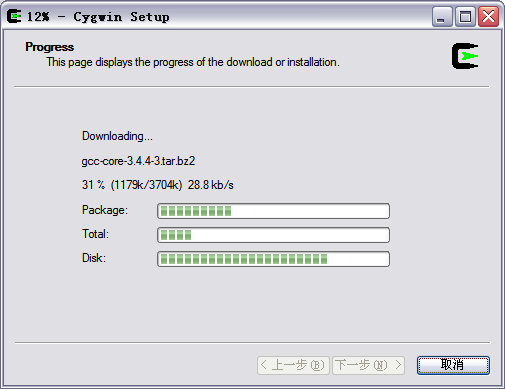
选完以后,我们选择下一步,进入安装过程,如下图所示,
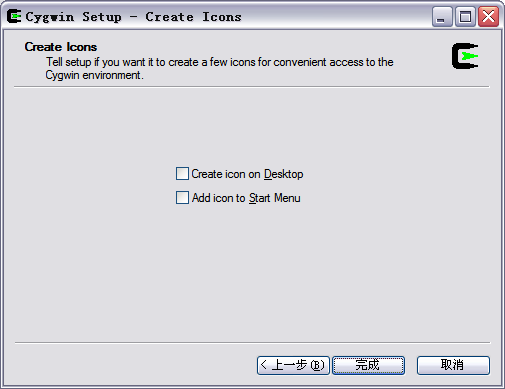
安装的时间依据你选择的组件以及网络情况而定。安装完成后,安装程序会提示是否在桌面上创建Cygwin图标等,点击完成退出安装程序。
至此,笔者还要对Cygwin再多说几句。Cygwin是一个在Windows平台上模拟运行Unix的环境,用户可以通过它来熟悉与学习Unix系统的操作。对于Unix系统还不甚熟悉的读者可以参阅笔者之前写作的《 Unix 操作系统的入门与基础》、《 Unix 的轻巧“约取而实得”》系列文章,下文中对涉及使用到的Unix命令将不再给予详细解释。
2、安装 Nutch
去http://mirror.vmmatrix.net/apache/lucene/ nutch/下载到 Nutch的最新版本,将其解压到指定目录中,如笔者是将其解压到I:\ nutch-0.7.1中。
3、测试 Nutch命令
在运行 Nutch的脚本命令前,需要设置一些环境变量。Cygwin提供了一个名为cygwin.bat的文件,通过它可以自动完成必需环境变量的设置。该文件可在cygwin所在的根目录下找到,感兴趣的读者还可通过UltraEdit等编辑器打开该文件一查究竟。其实Cygwin安装完成之后,会在Windows系统桌面生成一图标,如图8所示:
此图标就是cygwin根目录下cygwin.bat文件的快捷方式,双击此图标将打开一类似DOS窗口。由于先前笔者将 Nutch的压缩包解压至I:\ nutch-0.7.1中,故在此命令窗口中输入命令“cd /cygdrive/i/ nutch-0.7.1”,读者可根据自己的安装路径进行相应的修改,然后使用命令“ls -l”可查看 nutch-0.7.1中的所有子目录及文件信息。执行命令“bin/ nutch”,如果读者能看到如图9所示的提示,那恭喜你, Nutch在Windows系统中的安装已经大功告成了!
安装配置nutch
安装步骤:
1
,安装
JDK
安装路径:
C:\j2sdk1.4.2_042
,
2
,安装
tomcat
,安装路径:
D:\jakarta-tomcat-5.0.28
3
,安装
nutch-0.8.1.tar.gz
将下载的压缩包解压缩到:
D:\cygwin\nutch-0.8.1
配置步骤:
1、配置环境变量:
NUTCH_JAVA_HOME="C:\j2sdk1.4.2_04"
2、创建目录
在
nutch\bin 目录下创建一个urls目录,然后在目录里面新建一个文件,文件名为 “url.txt”,内容为你要爬行的网站如: http://www.sina.com.cn 或者 http://133.40.188.130:8880/klms
3、修改nutch\conf\crawl-urlfilter.txt文件
打开
nutch\conf\crawl-urlfilter.txt文件,把MY.DOMAIN.NAME字符替换为url.txt内的url的域名,其实更简单点,直接删除MY.DOMAIN.NAME这几个字就可以了,也就是说,只保存+^http://([a-z0-9]*\.)*这几个字就可以了,表示所有http的网站都同意爬行。
如:+^http://([a-z0-9]*\.)*133.40.188.130:8880/
如:+^http://([a-z0-9]*\.)*133.40.188.130:8880/
或者:+^http://([a-z0-9]*\.)*sina.com.cn/
4、修改nutch\conf\conf/nutch-site.xml文件
打开
nutch\conf\conf/
nutch-site.xml文件,在<configuration></configuration>内插入一下内容:
注:如果是
sina.com.cn
则value
的值修改为:http://www.sina.com.cn
<property>
<name>http.robots.agents</name>
<value>http://133.40.188.130:8880/klms</value>
</property>
<property>
<name>http.agent.name</name>
<value>http://133.40.188.130:8880/klms</value>
</property>
<property>
<name>http.agent.url</name>
<value>http://133.40.188.130:8880/klms</value>
</property>
把<name>XXX</name>之间的内容替换为其他字符,当然就算是不替换也无所谓,这里的设置,是因为
nutch遵守了robots协议,在获取response时,把自己的相关信息提交给被爬行的网站,以供识别。
5、修改nutch\conf\nutch-default.xml
打开
nutch\conf\
nutch-default.xml 文件,找到<name>http.agent.name</name> ,然后把Value值随便设计一个。
<name>http.agent.name</name>
<value>sina</value>
以上配置,是爬取intranet的配置方式。
6、执行nutch
由于配置
nutch采用的是单独网站的配置方式,所以执行上我们也采用的是单网查询,全网查询在以后的内容中介绍。
先看一看
nutch给出的命令:
nutch crawl urls -dir crawl -depth 3 -topN 50
crawl:通知
nutch.jar,执行crawl的main方法。
urls:存放需要爬行的url.txt文件的目录,注意,这个名字需要和你的文件夹目录相同,如果你的文件夹为search,那这里也应该改成search。
-dir crawl:爬行后文件保存的位置,可以在
nutch/bin目录下找到。
-depth 3:爬行次数,或者成为深度,不过还是觉得次数更贴切,建议测试时改为1。
-topN 50:一个网站保存的最大页面数。
执行命令的步骤:
1. 进入cygwin界面。
2. 使用cd命令,进入
nutch\bin路径下。
3. 执行:sh
nutch crawl urls -dir crawl -depth 3 -topN 50
4. 具体的爬行日志可以在
nutch/logs目录下看到,注意查找“INFO fetcher.Fetcher - fetching
http://XXXXXXX”这样的内容,这里是抓去过程日志。
7、查询搜索:
nutch提供了类似google、baidu的网页页面,在
nutch压缩包下找到
nutch-0.8.war文件,放到tomcat/webapps目录下,修改webapps/
nutch/WEB-INF/classes/
nutch-site.xml文件内容如下:
<property>
<name>searcher.dir</name> <value>E:\\software\\splider\\
nutch\\
nutch-0.8\\
nutch-0.8\\crawl</value>
</property>
<value/>的内容是刚才爬行后的crawl目录位置,提供给客户端来查询。
8.解决中文问题
打开tomcat 目录下的conf\server.xml ,解决中文问题。
<Connector port="8880"
maxThreads="150" minSpareThreads="25" maxSpareThreads="75"
enableLookups="false" redirectPort="8443" acceptCount="100"
debug="0" connectionTimeout="20000"
disableUploadTimeout="true" URIEncoding="UTF-8" useBodyEncodingForURI="true" />
配置完成后,启动tomcat,输入
http://localhost:8080/nutch,输入关键字,就会看到结果了:
现在可以开始抓网页了
用cygwin进入/home/
nutch目录,
./bin/
nutch crawl ./URLS/URLS-20060212 -dir sina.com.cn -depth 2 -threads 4
depth 参数指爬行的深度,这里处于测试的目的,选择深度为 2 ;
threads 参数指定并发的进程 这是设定为 4 ;
3,配置tomcat
将D:\Program Files\Tomcat 5.5\webapps\ROOT目录下文件全部删除
将D:\cygwin\home\ nutch中 nutch-0.7.1.war解压缩到ROOT目录中
(可以直接使用winrar解压缩,或者用命令jar xvf nutch-0.7.1.war)
配置文件:D:\Program Files\Tomcat 5.5\webapps\ROOT\WEB-INF\classes\ nutch-site.xml
< nutch-conf>
<property>
<name>searcher.dir</name>
<value>D:\cygwin\home\ nutch\sina.com.cn</value>
</property>
</ nutch-conf>
重启tomcat服务器
IE中输入http://localhost:8080
你就可以看到自己的搜索引擎了
将D:\cygwin\home\ nutch中 nutch-0.7.1.war解压缩到ROOT目录中
(可以直接使用winrar解压缩,或者用命令jar xvf nutch-0.7.1.war)
配置文件:D:\Program Files\Tomcat 5.5\webapps\ROOT\WEB-INF\classes\ nutch-site.xml
< nutch-conf>
<property>
<name>searcher.dir</name>
<value>D:\cygwin\home\ nutch\sina.com.cn</value>
</property>
</ nutch-conf>
重启tomcat服务器
IE中输入http://localhost:8080
你就可以看到自己的搜索引擎了
Nutch 爬行方式
Nutch 的爬虫有两种方式:
1、爬行企业内部网
1、爬行企业内部网(Intranet crawling)。针对少数网站进行。用 crawl 命令。
2、爬行整个互联网
2.1、爬行整个互联网。 使用低层的 inject, generate, fetch 和 updatedb 命令。具有更强的可控制性。
2.1.1、全网爬行
全网爬行设计去处理非常大量的爬行,它可能要花几个星期的时间才能完成,并起需要多台电脑来运行它。
2.1.2 下载 http://rdf.dmoz.org/rdf/content.rdf.u8.gz 然后解压 解压命令为: gunzip content.rdf.u8.gz
2.1.3 创建目录 mkdir dmoz
2.1.4 每搜索5000条URL记录选择一个存进urls文件: bin/
nutch org.apache.
nutch.tools. DmozParser content.rdf.u8 -subset 5000 > dmoz/urls
4.4 初始化crawldb: bin/
nutch inject crawl/crawldb dmoz
4.5 从crawldb生成fetchlist: bin/
nutch generate crawl/crawldb crawl/segments
4.6 fetchlist放置在重新创造的段目录,段目录根据指定的时间创建,我们保存这段变量s1:
s1=`ls -d crawl/segments/2* | tail -1`
echo $s1 显示结果如:crawl/segments/2006******* /*号部分表示是月日时的数字,如20060703150028
4.7 运行这段: bin/
nutch fetch $s1
4.8 完成后更新数据结果: bin/
nutch updatedb crawl/crawldb $s1
4.9现在数据库的参考页设在最初,接着来取得新的1000页:
bin/
nutch generate crawl/crawldb crawl/segments -topN 1000
s2=`ls -d crawl/segments/2* | tail -1`
echo $s2
bin/
nutch fetch $s2
bin/
nutch updatedb crawl/crawldb $s2
4.10 让我们取得周围的更多:
bin/
nutch generate crawl/crawldb crawl/segments -topN 1000
s3=`ls -d crawl/segments/2* | tail -1`
echo $s3
bin/
nutch fetch $s3
bin/
nutch updatedb crawl/crawldb $s3
4.11 创建索引:
bin/ nutch invertlinks crawl/linkdb -dir crawl/segments
bin/ nutch invertlinks crawl/linkdb -dir crawl/segments
4.12 使用索引命令: bin/
nutch index crawl/indexes crawl/crawldb crawl/linkdb crawl/segments/*