记录一次3ware 卡的Raid10重建
我们公司有唯一一台长城的服务器
NS3120
,有
12
个
250G
硬盘。应该是
2005
年
8
月份左右买的,用来做公司主存储,命名主机名称用
nas
。到去年
8
月份就过了保修期。
上周
6
突然收到很多这样的邮件警告:
Subject
:
3ware 3DM2 alert -- host: nas
20090919192526 - Controller 0
WARNING - Sector repair completed: port=2, LBA=0x1B6BD900
后来又有内容如下的警告:
20090919192925 - Controller 0
ERROR - Degraded unit: unit=0, port=2
20090919192925 - Controller 0
ERROR - Drive timeout detected: port=2
20090919000129 - Controller 0
WARNING - SMART threshold exceeded: port=2
因为是周末邮件都是到了晚上才看到。当然服务器日志message里面也出现了很多这样的错误。
这时候我登录到nas服务器上,输入tw_cli(有很多人可能喜欢tw_cli 后直接接命令,像tw_cli info c0 u0 等,但我更喜欢先进入tw_cli的命令界面后,再进行别的操作),得到:
[root@nas ~]# tw_cli
//nas> info c0 u0
Unit UnitType Status % Cmpl Port Stripe Size(GB) Blocks
-----------------------------------------------------------------------
u0 RAID-10 DEGRADED* - - 64K 1396.92 2929557504
u0-0 RAID-1 OK - - - - -
u0-0-0 DISK OK - p10 - 232.82 488259584
u0-0-1 DISK OK - p11 - 232.82 488259584
u0-1 RAID-1 OK - - - - -
u0-1-0 DISK OK - p8 - 232.82 488259584
u 0-1-1 DISK OK - p9 - 232.82 488259584
u0-2 RAID-1 OK - - - - -
u0-2-0 DISK OK - p6 - 232.82 488259584
u 0-2-1 DISK OK - p7 - 232.82 488259584
u0-3 RAID-1 OK - - - - -
u0-3-0 DISK OK - p4 - 232.82 488259584
u 0-3-1 DISK OK - p5 - 232.82 488259584
u0-4 RAID-1 DEGRADED - - - - -
u0-4-0 DISK DEGRADED - p2 - 232.82 488259584
u 0-4-1 DISK OK - p3 - 232.82 488259584
u0-5 RAID-1 OK - - - - -
u0-5-0 DISK OK - p0 - 232.82 488259584
u 0-5-1 DISK OK - p1 - 232.82 488259584
//nas> info c0
Unit UnitType Status %Cmpl Stripe Size(GB) Cache AVerify IgnECC
------------------------------------------------------------------------------
u0 RAID-10 DEGRADED - 64K 1396.92 ON OFF OFF
Port Status Unit Size Blocks Serial
---------------------------------------------------------------
p0 OK u0 232.88 GB 488397168 WD-WCAL76280314
p1 OK u0 232.88 GB 488397168 WD-WCAL76207833
p2 DEVICE-ERROR u0 232.88 GB 488397168 WD-WCAL73516836
p3 OK u0 232.88 GB 488397168 WD-WCAL73587842
p4 OK u0 232.88 GB 488397168 WD-WCAL75670919
p5 OK u0 232.88 GB 488397168 WD-WCAL76197410
p6 OK u0 232.88 GB 488397168 WD-WCAL73498032
p7 OK u0 232.88 GB 488397168 WD-WCAL73588557
p8 OK u0 232.88 GB 488397168 WD-WCAL76291855
p9 OK u0 232.88 GB 488397168 WD-WCAL76254218
p10 OK u0 232.88 GB 488397168 WD-WCAL76251971
p11 OK u0 232.88 GB 488397168 WD-WCAL76280979
查看
raid
卡序列号
//nas> info c0 serial
/c0 Serial Number = F 19302A 4430087
查看
raid
卡型号
//nas> info c0 model
/c0 Model = 9500S-12
由上面的输出,显示
u0-4-0 DISK DEGRADED - p2 - 232.82 488259584
这个硬盘已经降级,发现
p2 DEVICE-ERROR u0 232.88 GB 488397168 WD-WCAL73516836
在
Port2
出现
device-error
,基本可以判定
port2
上的硬盘坏了(或者说可能快坏了,最好更换)。
拨长城
400
技术售后电话,无法接通(不再上班时间段),等到周日再拨,叫我联系苏州地区维修点。苏州维修点周日不上班,再等到周一。
这时候心里其实很着急的,因为这个主存储器上放了公司很多重要的东西,而且硬盘被频繁读写了这么多年,如果损坏影响会比较大,不过唯一比较安慰的就是从周
5
到周
6
晚上我已经完成了重要数据的备份。使用
rsync
同步
1.1T
共
8053566
个左右文件,耗时共
39.5
小时。
好不容易挨到周一,打苏州维修告诉了他们具体情况比如(机器型号,硬盘大小,
raid
卡型号
3ware 9500S-12
),因为对长城的服务器不熟,因为我们服务器不方便关机重启,然后咨询了几个问题
1.
我们这个服务器是否支持热插拔
2.
是否支持
raid
卡的
raid10
自动重建
3.
如果我自己更换一个
320G
的硬盘是否可以
4.
如果不支持我怎么自己来
rebuild
他们说需要查询总部,然后没消息了,打过几次电话过去给了些没用的信息,打长城总部技术支持也这样,还联系过南京维修点。共打了估计
10
次电话吧,总之都没有人回答我这几个基本问题。这次对长城服务器的售后维护这块超级不满意。到我记录为止(现在已经周
3
早上了,还没有给我明确答复)。我估计是因为可能长城不主攻服务器市场,里面的技术工程师都是桌面机的。而且他们和客户联系的好像都是普通工程师,问个什么问题都说要和后台工程师确认,而且效率超级慢,为什么不能让“厉害”的后台工程师直接和客户联系呢?
最后看来是不能指望长城的售后了,只能自己到
3ware
的网站去翻资料,熟悉了下
9500s-12
卡,但是没有明确看到
autorebuild
功能。
因为同步过一次数据,心里稍微放心点,心想自己弄吧。如果真坏了,大不了就用我备份服务器上的数据。根据以往换别的服务器的经验,周一晚上定了块
320G
的西数企业硬盘(目前市场上很难买到
250G
的西数企业硬盘了。)周
2
拿到了硬盘,然后再次同步了下最重要的
cvs
数据。
到了晚上,我走进机房,再次确认了下是
port2
口,拨下硬盘然后用
tw_cli info c0 u0
查看信息没任何变化。
更换托架新硬盘插入,输出信息还是没有任何变化。这个卡不支持自动
rebuild
?
只能手动了
rebuild
了。
通过网上的资料,输入:

我这里输入的是
p0
,当时由于按错了本来应该输入
p2
的,哈哈,还好
RAID10,
移除一个没有问题。
错误移除了
p0
,那就先对
p0
重建吧。

过了会查看状态:
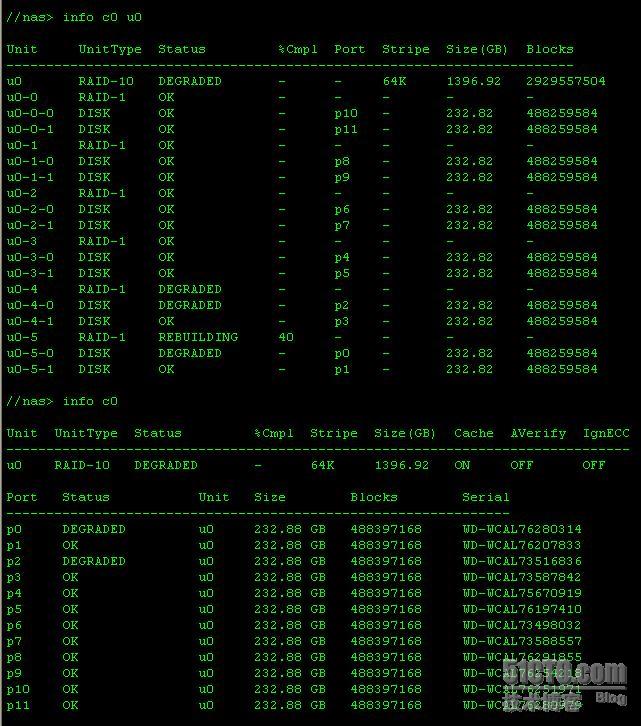
可以看出
p0
上的硬盘已经
rebuild
完成了
40%
。
差不多
1
个半小时,
P0
上的硬盘全部完成。
按照同样的方法对
p2
硬盘
rebuild.
maint remove c0 p2
maint rescan c0
maint rebuild c0 u0 p2
再等了差不多
1
个半小时全部完成。

可以看出
p2
上的硬盘是
WD-WCAT
和别的硬盘
WD-WCAL
不一样的,这个是我新换上的
320G
的硬盘。到此
raid10
修复全部完成。
其实,最重要就是胆大(我主要是有备份所有心里不怎么担心),心细(当然不能像我这样把
p2
,打成
p0
哦,如果你是
raid5
,那就惨了。)
这
2
天的担心终于可以轻松下了,以后再出现这样的硬盘问题就能很快更换上。