grep,sed,awk的用法举例
事前准备
1.主机
node1:172.16.133.11
2.作为实验的文件
/etc/passwd

/etc/fstab

qinqin

cp /etc/passwd . cp /etc/fstab .
一、grep用法详解
1.grep是干什么的
grep的全名是Galobal research Regular Expression and Pringtiong,即搜索正则表达式,也就是说grep简单来讲就是用来搜索匹配字符的
2.grep分类
grep有基本正则表达式和扩展正则表达式之分,不过她们的作用域和使用方法大同小异
3.grep用法及选项
首先普通的用法:grep [option] 'PATTERN' file file2...
例:grep 'root' /etc/passwd搜索在/etc/passwd中的root字符的那一行
选项:
--color将搜索到的字符予以颜色加以标识,易于辨认
grep --color 'root' passwd

-v取反,即除了匹配到的行其余都显示
grep -v 'root' passwd

-i忽略大小写进行匹配
grep -i 'label' fstab
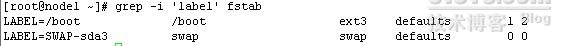
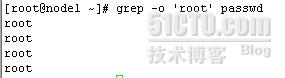
-o仅显示匹配到的字符串
grep -o 'root' passwd
单独显示本机ip地址和子网掩码
ifconfig | grep -E -o --color "\<([1-9]|[1-9][0-9]|1[1-9][1-9]|2[1-5][0-5])\>.\<([1-9]|[1-9][0-9]|1[1-9][1-9]|2[1-5][0-5])\>.\<([1-9]|[1-9][0-9]|1[1-9][1-9]|2[1-5][0-5])\>.\<([1-9]|[1-9][0-9]|1[1-9][1-9]|2[1-5][0-5])\>"

-q静默模式,不输出,在shell脚本中经常用到
grep -q 'root' passwd
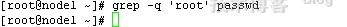
-A匹配到的行向下多显示n行,匹配到root后,连其后的n行一并显示
grep -A 2 'root' fstab

-B匹配到的行向上多显示n行,匹配到root后,连其上的n行一并显示
grep -B 3 'student' passwd

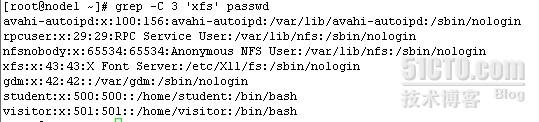
-C匹配到的行多显示其上下n行,匹配到root后,其上下n行一并显示
grep -C 3 'xfs' passwd
4.基本正则表达式
.(点号):表示匹配任意单个字符;
grep -o "r." passwd

*匹配前面一个字符任意次(可以是0次)
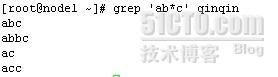
grep 'ab*c' qinqin
.*:表示任意长度的任意字符(两个一起用时,贪婪模式,能匹配多长就匹配多长)
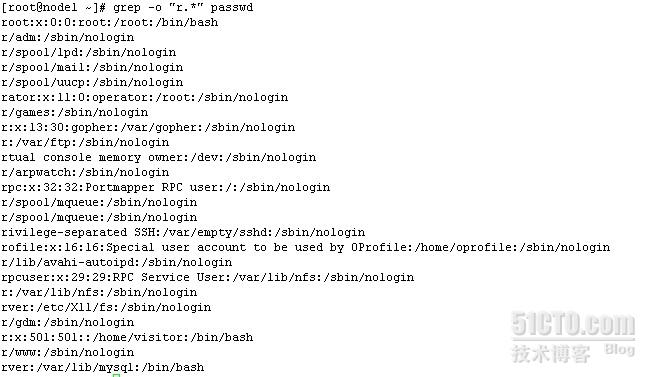
grep -o "r.*" passwd
[]指定范围内的任意单个字符[^a-z]指定范围内之外的字符
grep "a[a-z]c" qinqin

X\{m,n\}:X出现大于m次,小于n次
grep "ab\{1,3\}c" qinqin

X\{m,\}:X出现大于m次,无上限
grep "ab\{2,\}c" qinqin

X\{0,n\}:X出现小于n次
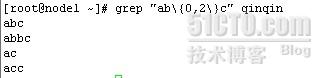
grep "ab\{0,2\}c" qinqin
?:匹配其前面的字符0次或一次(-E,使用扩展表达式)
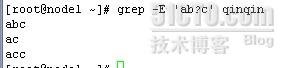
grep -E 'ab?c' qinqin
锚定符:
^:锚定行首(行首匹配)
grep "^root" passwd

$:锚定行尾(行尾匹配)
grep "bash$" passwd

^$:空白行
\<或者\b:锚定词首;
grep "\<root" passwd

\>或者\b:锚定词尾
grep "bash\>" passwd

\(\):分组后向引用:\1,\2
grep "l\([0-9]\{1,\}\):\1:.* \1" /etc/inittab

5.扩展正则表达式
extended regexp:扩展正则表达式(egrep支持这种)
\{\}-->{}
\(\)-->()
+:做次数匹配,表示匹配其前的字符一次或多次
|:或者 a|b,C|cat:C,cat;(C|c)at:Cat,cat
明标签时使用 :label的格式,跳转时不用冒号;
二、sed命令详解
1.sed是什么
Sed全名为Stream EDitor,即流式编辑器,行编辑器
2.sed常用用法
sed [options] 'script(模式命令)' input_file...
sed [options] -f script_file(sed脚本) input_file...
sed 'ADDR1,ADDR2command' input_file;例如sed '1,2d' fstab(可输出重定向到别的文件)
sed '1,2!(对命令取反)d' fstab除了第一行,第二行,其余全删除

sed '/PATTERN/command' input_file(使用基本正则表达式的原字符,而不实用grep)
sed '/PATTERN1/,/PATTERN2/command' input_file从第一次被模式PATTERN1匹配到的行到第一次被PATTERN2匹配到的行执行命令command
3.sed常用选项及模式
(1).常用选项
-n静默模式,不打印模式空间中的内容,例如sed '1,3p' fstab会显示所有文件,其中前三行,显示两次,加了-n之后只会显示前三行
sed -n '1,3p' fstab
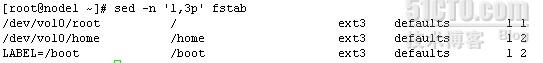
-i直接操作原文件
-i
sed -i '5d' fstab

-r使用扩展正则表达式
-e多脚本处理
sed -e 's/a/e/g' -e 's/b/f/g' -e 's/c/g/g' qinqin
(2).常用模式
d删除指定行
p模式空间中的文本在处理之前,每一次都会先显示:p,显示,指定行会被显示两次
$表示最后一行
a \:在模式匹配到的行后面添加新内容
sed '/a/a \this is a comment line.\n' qinqin

r FILE:读文件追加到别的文件后面
sed '2r qinqin' fstab
i \:在模式匹配到的行前面添加新内容
sed '/abc/i \this is a test' qinqin

w FILE:把这个文件中模式所匹配到的行写到另一个文件中
sed -n '/root/w qinqin' fstab

s :s/PATTERN/string/ 例如:s@/dev/vo10/root@/dev/sda2/
g:匹配全文
i:忽略大小写
s/PATTERN/&string/在前面匹配到的PATTERN后面加上string
sed 's/root/qinqin/g' fstab

n:读取下一行,以覆盖方式,一次读进来
sed 'n;p' fstab

N:读取下一行,以追加方式,在模式空间中两行做一行处理(N;N三行一起处理)
sed 'N;p' fstab

扩展sed 'N;s/\n/ /g' fstab

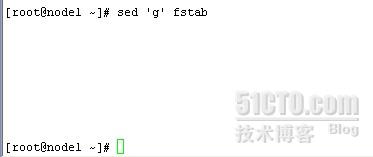
g:将保留空间中的内容复制到模式空间,覆盖的方式
sed 'g' fstab
G:将保留空间中的内容复制到模式空间,追加的方式
sed 'G' fstab

h:将模式中的模式空间复制到保留空间,覆盖的方式
sed -n 'h;n;G;h;n;G;p' fstab

H:将模式中的模式空间复制到保留空间,追加的方式
sed -n 'H;n;G;h;n;G;p' fstab

b label:跳转 例如:sed -n '3b;p'跳转到第三行 seb '\#b' test跳过有#号的行
x:将保留空间和模式空间对调
t label: 测试:前面的s命令执行成功就跳转到标记位置
三、awk命令详解
awk常用用法
awk [options] 'script' file1, file2, ...
awk [options] 'PATTERN { action }' file1, file2, ...
-F指定分隔符
1.awk的输出:
(1).print
print的使用格式:
print item1, item2, ...
要点:
①.各项目之间使用逗号隔开,而输出时则以空白字符分隔;
②.输出的item可以为字符串或数值、当前记录的字段(如$1)、变量或awk的表达式;数值会先转换为字符串,而后再输出;
③.print命令后面的item可以省略,此时其功能相当于print $0, 因此,如果想输出空白行,则需要使用print "";
例子:
awk 'BEGIN { print "line one\nline two\nline three" }'
awk -F: '{ print $1, $2 }' passwd

④.内置变量:
ORS(output record separator)
OFS(output field separator)
FS: field separator,默认是空白字符;
RS: Record separator,默认是换行符;
NR: The number of input records,awk命令所处理的记录数;如果有多个文件,这个数目会把处理的多个文件中行统一计数;
NF:Number of Field,当前记录的field个数;
FNR: 与NR不同的是,FNR用于记录正处理的行是当前这一文件中被总共处理的行数;
ARGV: 数组,保存命令行本身这个字符串,如awk '{print $0}' a.txt b.txt这个命令中,ARGV[0]保存awk,ARGV[1]保存a.txt;
ARGC: awk命令的参数的个数;
(2).printf
printf命令的使用格式:
printf format, item1, item2, ...
要点:
①.其与print命令的最大不同是,printf需要指定format;
②.format用于指定后面的每个item的输出格式;
③.printf语句不会自动打印换行符;\n
④.format格式的指示符都以%开头,后跟一个字符;如下:
%c: 显示字符的ASCII码;
%d, %i:十进制整数;
%e, %E:科学计数法显示数值;
%f: 显示浮点数;
%g, %G: 以科学计数法的格式或浮点数的格式显示数值;
%s: 显示字符串;
%u: 无符号整数;
%%: 显示%自身;
⑤.修饰符:
N: 显示宽度;
-: 左对齐;
+:显示数值符号;
例子:
awk -F: '{printf "%-15s %i\n",$1,$3}' passwd

2.awk输出重定向
print items > output-file
print items >> output-file
print items | command
特殊文件描述符:
/dev/stdin:标准输入
/dev/sdtout: 标准输出
/dev/stderr: 错误输出
/dev/fd/N: 某特定文件描述符,如/dev/stdin就相当于/dev/fd/0;
例子:
awk -F: '{printf "%-15s %i\n",$1,$3 >> "qinqin" }' passwd

3.awk的操作符:
(1).算术操作符:
-x: 负值
+x: 转换为数值;
x^y:
x**y: 次方
x*y: 乘法
x/y:除法
x+y:
x-y:
x%y:
(2).字符串操作符:
只有一个,而且不用写出来,用于实现字符串连接;
(3).赋值操作符:
=
+=
-=
*=
/=
%=
^=
**=
++
--
需要注意的是,如果某模式为=号,此时使用/=/可能会有语法错误,应以/[=]/替代;
(4).布尔值
awk中,任何非0值或非空字符串都为真,反之就为假;
(5).比较操作符:
x < y True if x is less than y.
x <= y True if x is less than or equal to y.
x > y True if x is greater than y.
x >= y True if x is greater than or equal to y.
x == y True if x is equal to y.
x != y True if x is not equal to y.
x ~ y True if the string x matches the regexp denoted by y.
x !~ y True if the string x does not match the regexp denoted by y.
subscript in array True if the array array has an element with the subscript subscript.
(6)表达式间的逻辑关系符:
&&
||
(7).条件表达式:
selector?if-true-exp:if-false-exp
(8).函数调用:
function_name (para1,para2)
4.awk的模式:
awk 'program' input-file1 input-file2 ...
其中的program为:
pattern { action }
pattern { action }
常见的模式类型:
(1).Regexp: 正则表达式,格式为/regular expression/
(2).expresssion: 表达式,其值非0或为非空字符时满足条件,如:$1 ~ /foo/ 或 $1 == "magedu",用运算符~(匹配)和~!(不匹配)。
(3).Ranges: 指定的匹配范围,格式为pat1,pat2
(4).BEGIN/END:特殊模式,仅在awk命令执行前运行一次或结束前运行一次
(5).Empty(空模式):匹配任意输入行;
常见的Action有:
(1).Expressions:
(2).Control statements
(3).Compound statements
(4).Input statements
(5).Output statements
/正则表达式/:使用通配符的扩展集。
关系表达式:可以用下面运算符表中的关系运算符进行操作,可以是字符串或数字的比较,如$2>%1选择第二个字段比第一个字段长的行。
模式匹配表达式:
模式,模式:指定一个行的范围。该语法不能包括BEGIN和END模式。
BEGIN:让用户指定在第一条输入记录被处理之前所发生的动作,通常可在这里设置全局变量。
END:让用户在最后一条输入记录被读取之后发生的动作。
5.awk控制语句:
(1).if-else
语法:if (condition) {then-body} else {[ else-body ]}
例子:
awk -F: '{if ($1=="root") print $1, "Admin"; else print $1, "Common User"}' passwd

awk -F: '{if ($1=="root") printf "%-15s: %s\n", $1,"Admin"; else printf "%-15s: %s\n", $1, "Common User"}' passwd

awk -F: -v sum=0 '{if ($3>=500) sum++}END{print sum}' passwd
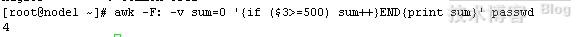
(2).while
语法: while (condition){statement1; statment2; ...}
(3).do-while
语法: do {statement1, statement2, ...} while (condition)
(4).for
语法: for ( variable assignment; condition; iteration process) { statement1, statement2, ...}
for循环还可以用来遍历数组元素:
语法: for (i in array) {statement1, statement2, ...}
(5).case
语法:switch (expression) { case VALUE or /REGEXP/: statement1, statement2,... default: statement1, ...}
(6).break 和 continue
常用于循环或case语句中
(7).next
提前结束对本行文本的处理,并接着处理下一行;
6.awk中使用数组:
array[index-expression]
index-expression可以使用任意字符串;需要注意的是,如果某数据组元素事先不存在,那么在引用其时,awk会自动创建此元素并初始化为空串;因此,要判断某数据组中是否存在某元素,需要使用index in array的方式。
要遍历数组中的每一个元素,需要使用如下的特殊结构:
for (var in array) { statement1, ... }
其中,var用于引用数组下标;
例子:
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
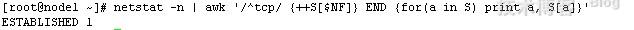
每出现一被/^tcp/模式匹配到的行,数组S[$NF]就加1,NF为当前匹配到的行的最后一个字段,此处用其值做为数组S的元素索引;
awk '{counts[$1]++}; END {for(url in counts) print counts[url], url}' /var/log/httpd/access_log
用法与上一个例子相同,用于统计某日志文件中IP地的访问量
7.awk的内置函数:
split(string, array [, fieldsep [, seps ] ])
功能:将string表示的字符串以fieldsep为分隔符进行分隔,并将分隔后的结果保存至array为名的数组中;
netstat -ant | awk '/:80/{split($5,clients,":");IP[clients[1]]++}END{for(i in IP){print IP[i],i}}' | sort -rn | head -50
length([string])
功能:返回string字符串中字符的个数;
substr(string, start [, length])
功能:取string字符串中的子串,从start开始,取length个;start从1开始计数;
system(command)
功能:执行系统command并将结果返回至awk命令
systime()
功能:取系统当前时间
本文出自 “周钰钦” 博客,请务必保留此出处http://zhouyuqin.blog.51cto.com/5132926/967141