Best Practices for Exception Handling
原文:http://onjava.com/pub/a/onjava/2003/11/19/exceptions.html?page=1
One of the problems with exception handling is knowing when and how to use it. In this article, I will cover some of the best practices for exception handling. I will also summarize the recent debate about the use of checked exceptions.
We as programmers want to write quality code that solves problems. Unfortunately, exceptions come as side effects of our code. No one likes side effects, so we soon find our own ways to get around them. I have seen some smart programmers deal with exceptions the following way:
public void consumeAndForgetAllExceptions(){
try {
...some code that throws exceptions
} catch (Exception ex){
ex.printStacktrace();
}
}What is wrong with the code above?
Once an exception is thrown, normal program execution is suspended and control is transferred to the catch block. The catch block catches the exception and just suppresses it. Execution of the program continues after the catch block, as if nothing had happened.
How about the following?
public void someMethod() throws Exception{
}This method is a blank one; it does not have any code in it. How can a blank method throw exceptions? Java does not stop you from doing this. Recently, I came across similar code where the method was declared to throw exceptions, but there was no code that actually generated that exception. When I asked the programmer, he replied "I know, it is corrupting the API, but I am used to doing it and it works."
It took the C++ community several years to decide on how to use exceptions. This debate has just started in the Java community. I have seen several Java programmers struggle with the use of exceptions. If not used correctly, exceptions can slow down your program, as it takes memory and CPU power to create, throw, and catch exceptions. If overused, they make the code difficult to read and frustrating for the programmers using the API. We all know frustrations lead to hacks and code smells. The client code may circumvent the issue by just ignoring exceptions or throwing them, as in the previous two examples.
The Nature of Exceptions
Broadly speaking, there are three different situations that cause exceptions to be thrown:
-
Exceptions due to programming errors: In this category, exceptions are generated due to programming errors (e.g.,
NullPointerExceptionandIllegalArgumentException). The client code usually cannot do anything about programming errors. -
Exceptions due to client code errors: Client code attempts something not allowed by the API, and thereby violates its contract. The client can take some alternative course of action, if there is useful information provided in the exception. For example: an exception is thrown while parsing an XML document that is not well-formed. The exception contains useful information about the location in the XML document that causes the problem. The client can use this information to take recovery steps.
-
Exceptions due to resource failures: Exceptions that get generated when resources fail. For example: the system runs out of memory or a network connection fails. The client's response to resource failures is context-driven. The client can retry the operation after some time or just log the resource failure and bring the application to a halt.
Types of Exceptions in Java
Java defines two kinds of exceptions:
-
Checked exceptions: Exceptions that inherit from the
Exceptionclass are checked exceptions. Client code has to handle the checked exceptions thrown by the API, either in acatchclause or by forwarding it outward with thethrowsclause. -
Unchecked exceptions:
RuntimeExceptionalso extends fromException. However, all of the exceptions that inherit fromRuntimeExceptionget special treatment. There is no requirement for the client code to deal with them, and hence they are called unchecked exceptions.
By way of example, Figure 1 shows the hierarchy for NullPointerException.
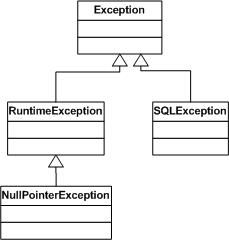
Figure 1. Sample exception hierarchy
In this diagram, NullPointerException extends from RuntimeException and hence is an unchecked exception.
I have seen heavy use of checked exceptions and minimal use of unchecked exceptions. Recently, there has been a hot debate in the Java community regarding checked exceptions and their true value. The debate stems from fact that Java seems to be the first mainstream OO language with checked exceptions. C++ and C# do not have checked exceptions at all; all exceptions in these languages are unchecked.
A checked exception thrown by a lower layer is a forced contract on the invoking layer to catch or throw it. The checked exception contract between the API and its client soon changes into an unwanted burden if the client code is unable to deal with the exception effectively. Programmers of the client code may start taking shortcuts by suppressing the exception in an empty catch block or just throwing it and, in effect, placing the burden on the client's invoker.
Checked exceptions are also accused of breaking encapsulation. Consider the following:
public List getAllAccounts() throws
FileNotFoundException, SQLException{
...
}The method getAllAccounts() throws two checked exceptions. The client of this method has to explicitly deal with the implementation-specific exceptions, even if it has no idea what file or database call has failed within getAllAccounts(), or has no business providing filesystem or database logic. Thus, the exception handling forces an inappropriately tight coupling between the method and its callers.
Best Practices for Designing the API
Having said all of this, let us now talk about how to design an API that throws exceptions properly.
1. When deciding on checked exceptions vs. unchecked exceptions, ask yourself, "What action can the client code take when the exception occurs?"
If the client can take some alternate action to recover from the exception, make it a checked exception. If the client cannot do anything useful, then make the exception unchecked. By useful, I mean taking steps to recover from the exception and not just logging the exception. To summarize:
| Client's reaction when exception happens | Exception type |
|---|---|
| Client code cannot do anything | Make it an unchecked exception |
| Client code will take some useful recovery action based on information in exception | Make it a checked exception |
Moreover, prefer unchecked exceptions for all programming errors: unchecked exceptions have the benefit of not forcing the client API to explicitly deal with them. They propagate to where you want to catch them, or they go all the way out and get reported. The Java API has many unchecked exceptions, such as NullPointerException, IllegalArgumentException, and IllegalStateException. I prefer working with standard exceptions provided in Java rather than creating my own. They make my code easy to understand and avoid increasing the memory footprint of code.
2. Preserve encapsulation.
Never let implementation-specific checked exceptions escalate to the higher layers. For example, do not propagate SQLException from data access code to the business objects layer. Business objects layer do not need to know about SQLException. You have two options:
-
Convert
SQLExceptioninto another checked exception, if the client code is expected to recuperate from the exception. -
Convert
SQLExceptioninto an unchecked exception, if the client code cannot do anything about it.
Most of the time, client code cannot do anything about SQLExceptions. Do not hesitate to convert them into unchecked exceptions. Consider the following piece of code:
public void dataAccessCode(){
try{
..some code that throws SQLException
}catch(SQLException ex){
ex.printStacktrace();
}
}This catch block just suppresses the exception and does nothing. The justification is that there is nothing my client could do about an SQLException. How about dealing with it in the following manner?
public void dataAccessCode(){
try{
..some code that throws SQLException
}catch(SQLException ex){
throw new RuntimeException(ex);
}
}This converts SQLException to RuntimeException. If SQLException occurs, the catch clause throws a new RuntimeException. The execution thread is suspended and the exception gets reported. However, I am not corrupting my business object layer with unnecessary exception handling, especially since it cannot do anything about an SQLException. If my catch needs the root exception cause, I can make use of the getCause() method available in all exception classes as of JDK1.4.
If you are confident that the business layer can take some recovery action when SQLException occurs, you can convert it into a more meaningful checked exception. But I have found that just throwing RuntimeException suffices most of the time.
3. Try not to create new custom exceptions if they do not have useful information for client code.
What is wrong with following code?
public class DuplicateUsernameException
extends Exception {}It is not giving any useful information to the client code, other than an indicative exception name. Do not forget that Java Exception classes are like other classes, wherein you can add methods that you think the client code will invoke to get more information.
We could add useful methods to DuplicateUsernameException, such as:
public class DuplicateUsernameException
extends Exception {
public DuplicateUsernameException
(String username){....}
public String requestedUsername(){...}
public String[] availableNames(){...}
}The new version provides two useful methods: requestedUsername(), which returns the requested name, and availableNames(), which returns an array of available usernames similar to the one requested. The client could use these methods to inform that the requested username is not available and that other usernames are available. But if you are not going to add extra information, then just throw a standard exception:
throw new Exception("Username already taken");Even better, if you think the client code is not going to take any action other than logging if the username is already taken, throw a unchecked exception:
throw new RuntimeException("Username already taken");Alternatively, you can even provide a method that checks if the username is already taken.
It is worth repeating that checked exceptions are to be used in situations where the client API can take some productive action based on the information in the exception. Prefer unchecked exceptions for all programmatic errors. They make your code more readable.
4. Document exceptions.
You can use Javadoc's @throws tag to document both checked and unchecked exceptions that your API throws. However, I prefer to write unit tests to document exceptions. Tests allow me to see the exceptions in action and hence serve as documentation that can be executed. Whatever you do, have some way by which the client code can learn of the exceptions that your API throws. Here is a sample unit test that tests for IndexOutOfBoundsException:
public void testIndexOutOfBoundsException() {
ArrayList blankList = new ArrayList();
try {
blankList.get(10);
fail("Should raise an IndexOutOfBoundsException");
} catch (IndexOutOfBoundsException success) {}
}The code above should throw an IndexOutOfBoundsException when blankList.get(10) is invoked. If it does not, the fail("Should raise an IndexOutOfBoundsException") statement explicitly fails the test. By writing unit tests for exceptions, you not only document how the exceptions work, but also make your code robust by testing for exceptional scenarios.
Best Practices for Using Exceptions
The next set of best practices show how the client code should deal with an API that throws checked exceptions.
1. Always clean up after yourself
If you are using resources like database connections or network connections, make sure you clean them up. If the API you are invoking uses only unchecked exceptions, you should still clean up resources after use, with try - finally blocks.
public void dataAccessCode(){
Connection conn = null;
try{
conn = getConnection();
..some code that throws SQLException
}catch(SQLException ex){
ex.printStacktrace();
} finally{
DBUtil.closeConnection(conn);
}
}
class DBUtil{
public static void closeConnection
(Connection conn){
try{
conn.close();
} catch(SQLException ex){
logger.error("Cannot close connection");
throw new RuntimeException(ex);
}
}
}DBUtil is a utility class that closes the Connection. The important point is the use of finally block, which executes whether or not an exception is caught. In this example, the finally closes the connection and throws a RuntimeException if there is problem with closing the connection.
2. Never use exceptions for flow control
Generating stack traces is expensive and the value of a stack trace is in debugging. In a flow-control situation, the stack trace would be ignored, since the client just wants to know how to proceed.
In the code below, a custom exception, MaximumCountReachedException, is used to control the flow.
public void useExceptionsForFlowControl() {
try {
while (true) {
increaseCount();
}
} catch (MaximumCountReachedException ex) {
}
//Continue execution
}
public void increaseCount()
throws MaximumCountReachedException {
if (count >= 5000)
throw new MaximumCountReachedException();
}The useExceptionsForFlowControl() uses an infinite loop to increase the count until the exception is thrown. This not only makes the code difficult to read, but also makes it slower. Use exception handling only in exceptional situations.
3. Do not suppress or ignore exceptions
When a method from an API throws a checked exception, it is trying to tell you that you should take some counter action. If the checked exception does not make sense to you, do not hesitate to convert it into an unchecked exception and throw it again, but do not ignore it by catching it with {} and then continue as if nothing had happened.
4. Do not catch top-level exceptions
Unchecked exceptions inherit from the RuntimeException class, which in turn inherits from Exception. By catching the Exception class, you are also catching RuntimeException as in the following code:
try{
..
}catch(Exception ex){
}The code above ignores unchecked exceptions, as well.
5. Log exceptions just once
Logging the same exception stack trace more than once can confuse the programmer examining the stack trace about the original source of exception. So just log it once.
Summary
These are some suggestions for exception-handling best practices. I have no intention of staring a religious war on checked exceptions vs. unchecked exceptions. You will have to customize the design and usage according to your requirements. I am confident that over time, we will find better ways to code with exceptions.
I would like to thank Bruce Eckel, Joshua Kerievsky, and Somik Raha for their support in writing this article.