Hadoop2.6.3 集群部署
Hadoop2.6.3 集群部署
本博文转载自超图研究所技术博客。
准备工作
准备三台ubuntu1404 环境
master 192.168.12.127
slave1 192.168.12.132
slave2 192.168.12.133
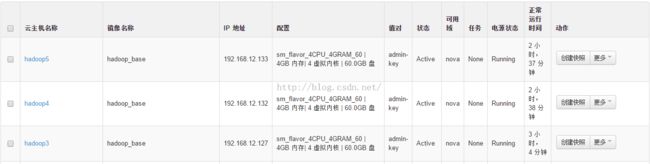
本例是通过openstack 创建的三台VM
配置三个节点间ssh 免密码登录
在slave1上
生成密钥,ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
在slave2上
生成密钥,ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
在master 上
1. 生成密钥,ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
2. 将公钥追加到授权的key中,cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
3,scp supermap@192.168.12.132:/home/supermap/.ssh/id_dsa.pub ~/.ssh/id_dsa_132.pub
4,scp supermap@192.168.12.133:/home/supermap/.ssh/id_dsa.pub ~/.ssh/id_dsa_133.pub
5,cat ~/.ssh/id_dsa_132.pub >> ~/.ssh/authorized_keys
6,cat ~/.ssh/id_dsa_133.pub >> ~/.ssh/authorized_keys
7,scp ~/.ssh/authorized_keys supermap@192.168.21.132:/home/supermap/.ssh/authorized_keys
8,scp ~/.ssh/authorized_keys supermap@192.168.21.133:/home/supermap/.ssh/authorized_keys
测试ssh
- supermap@master :~$ ssh slave1
- Welcome to Ubuntu 14.04 LTS (GNU/Linux 3.13.0-24-generic x86_64)
- * Documentation: https://help.ubuntu.com/
- System information as of Fri Jan 8 15:58:58 CST 2016
- System load: 0.01 Processes: 102
- Usage of /: 7.2% of 27.20GB Users logged in: 1
- Memory usage: 2% IP address for eth0: 192.168.12.132
- Swap usage: 0%
- Graph this data and manage this system at:
- https://landscape.canonical.com/
- Last login: Fri Jan 8 15:50:22 2016 from 192.168.13.8
- supermap@slave1:~$
安装jdk1.7
- root@slave1:~# ll /usr/lib/jvm/java-7-openjdk-amd64
- total 28
- drwxr-xr-x 7 root root 4096 Jan 8 11:02 ./
- drwxr-xr-x 3 root root 4096 Jan 8 10:58 ../
- lrwxrwxrwx 1 root root 22 Nov 19 18:39 ASSEMBLY_EXCEPTION -> jre/ASSEMBLY_EXCEPTION
- lrwxrwxrwx 1 root root 22 Nov 19 18:39 THIRD_PARTY_README -> jre/THIRD_PARTY_README
- drwxr-xr-x 2 root root 4096 Jan 8 11:02 bin/
- lrwxrwxrwx 1 root root 41 Nov 19 18:39 docs -> ../../../share/doc/openjdk-7-jre-headless/
- drwxr-xr-x 3 root root 4096 Jan 8 11:02 include/
- drwxr-xr-x 5 root root 4096 Jan 8 10:58 jre/
- drwxr-xr-x 3 root root 4096 Jan 8 11:02 lib/
- drwxr-xr-x 4 root root 4096 Jan 8 10:58 man/
- lrwxrwxrwx 1 root root 20 Nov 19 18:39 src.zip -> ../openjdk-7/src.zip
- root@slave1:~#
安装hadoop
下载hadoop2.6.3,下载链接 http://hadoop.apache.org/releases.html
解压 tar -xvf hadoop-2.6.3.tar.gz ,并在主目录下创建tmp、dfs、dfs/name、dfs/node
- supermap@slave1:~$ pwd
- /home/supermap
- supermap@slave1:~$ ll hadoop-2.6.3
- total 72
- drwxr-xr-x 12 supermap supermap 4096 Jan 8 11:33 ./
- drwxr-xr-x 5 supermap supermap 4096 Jan 8 15:53 ../
- -rw-r--r-- 1 supermap supermap 15429 Dec 18 09:52 LICENSE.txt
- -rw-r--r-- 1 supermap supermap 101 Dec 18 09:52 NOTICE.txt
- -rw-r--r-- 1 supermap supermap 1366 Dec 18 09:52 README.txt
- drwxr-xr-x 2 supermap supermap 4096 Dec 18 09:52 bin/
- drwxrwxr-x 4 supermap supermap 4096 Jan 8 11:34 dfs/
- drwxrwxr-x 2 supermap supermap 4096 Jan 8 11:33 dsf/
- drwxr-xr-x 3 supermap supermap 4096 Dec 18 09:52 etc/
- drwxr-xr-x 2 supermap supermap 4096 Dec 18 09:52 include/
- drwxr-xr-x 3 supermap supermap 4096 Dec 18 09:52 lib/
- drwxr-xr-x 2 supermap supermap 4096 Dec 18 09:52 libexec/
- drwxr-xr-x 2 supermap supermap 4096 Dec 18 09:52 sbin/
- drwxr-xr-x 4 supermap supermap 4096 Dec 18 09:52 share/
- drwxrwxr-x 2 supermap supermap 4096 Jan 8 11:33 tmp/
配置hadoop
配置hadoop 守护进程的运行环境
编辑conf/hadoop-env.sh
修改其中JAVA_HOME=实际安装目录export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
配置hadoop 守护进程的运行参数
- 配置 core-site.xml文件-->>增加hadoop核心配置(hdfs文件端口是9000、file:/home/supermp/hadoop-2.6.3/tmp、)
- <configuration>
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://master:9000</value>
- </property>
- <property>
- <name>io.file.buffer.size</name>
- <value>131072</value>
- </property>
- <property>
- <name>hadoop.tmp.dir</name>
- <value>file:/home/supermp/hadoop-2.6.3/tmp</value>
- <description>Abasefor other temporary directories.</description>
- </property>
- <property>
- <name>hadoop.proxyuser.spark.hosts</name>
- <value>*</value>
- </property>
- <property>
- <name>hadoop.proxyuser.spark.groups</name>
- <value>*</value>
- </property>
- </configuration>
- 配置 hdfs-site.xml 文件-->>增加hdfs配置信息(namenode、datanode端口和目录位置)
- <configuration>
- <property>
- <name>dfs.namenode.secondary.http-address</name>
- <value>master:9001</value>
- </property>
- <property>
- <name>dfs.namenode.name.dir</name>
- <value>file:/home/supermp/hadoop-2.6.3/dfs/name</value>
- </property>
- <property>
- <name>dfs.datanode.data.dir</name>
- <value>file:/home/supermp/hadoop-2.6.3/dfs/data</value>
- </property>
- <property>
- <name>dfs.replication</name>
- <value>3</value>
- </property>
- <property>
- <name>dfs.webhdfs.enabled</name>
- <value>true</value>
- </property>
- </configuration>
- 配置 mapred-site.xml 文件-->>增加mapreduce配置(使用yarn框架、jobhistory使用地址以及web地址)
- <configuration>
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
- <property>
- <name>mapreduce.jobhistory.address</name>
- <value>master:10020</value>
- </property>
- <property>
- <name>mapreduce.jobhistory.webapp.address</name>
- <value>master:19888</value>
- </property>
- </configuration>
- 配置 yarn-site.xml 文件-->>增加yarn功能
- <configuration>
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- <property>
- <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
- <value>org.apache.hadoop.mapred.ShuffleHandler</value>
- </property>
- <property>
- <name>yarn.resourcemanager.address</name>
- <value>master:8032</value>
- </property>
- <property>
- <name>yarn.resourcemanager.scheduler.address</name>
- <value>master:8030</value>
- </property>
- <property>
- <name>yarn.resourcemanager.resource-tracker.address</name>
- <value>master:8035</value>
- </property>
- <property>
- <name>yarn.resourcemanager.admin.address</name>
- <value>master:8033</value>
- </property>
- <property>
- <name>yarn.resourcemanager.webapp.address</name>
- <value>master:8088</value>
- </property>
- </configuration>
同步配置到两个salve
- supermap@master:~/hadoop-2.6.3/etc$ scp -r hadoop supermap@slave1:/home/supermap/hadoop-2.6.3/etc

添加 slave1,slave2 到集群
编辑slaves 文件
- supermap@master:~/hadoop-2.6.3/etc/hadoop$ cat slaves
- master
- slave1
- slave2
启动hadoop 集群
格式化一个新的分布式文件系统:
$ bin/hadoop namenode -format
启动HDFS
$ sbin/start-dfs.sh
sbin/start-dfs.sh脚本会参照 slaves文件的内容,在所有列出的slave上启动DataNode守护进程
- supermap@master:~/hadoop-2.6.3$ ./sbin/start-dfs.sh
- Starting namenodes on [master]
- master: starting namenode, logging to /home/supermap/hadoop-2.6.3/logs/hadoop-supermap-namenode-master.out
- slave1: starting datanode, logging to /home/supermap/hadoop-2.6.3/logs/hadoop-supermap-datanode-slave1.out
- slave2: starting datanode, logging to /home/supermap/hadoop-2.6.3/logs/hadoop-supermap-datanode-slave2.out
- master: starting datanode, logging to /home/supermap/hadoop-2.6.3/logs/hadoop-supermap-datanode-master.out
- Starting secondary namenodes [master]
- master: starting secondarynamenode, logging to /home/supermap/hadoop-2.6.3/logs/hadoop-supermap-secondarynamenode-master.out
启动yarn
- supermap@master:~/hadoop-2.6.3$ ./sbin/start-yarn.sh
- starting yarn daemons
- starting resourcemanager, logging to /home/supermap/hadoop-2.6.3/logs/yarn-supermap-resourcemanager-master.out
- master: starting nodemanager, logging to /home/supermap/hadoop-2.6.3/logs/yarn-supermap-nodemanager-master.out
- slave2: starting nodemanager, logging to /home/supermap/hadoop-2.6.3/logs/yarn-supermap-nodemanager-slave2.out
- slave1: starting nodemanager, logging to /home/supermap/hadoop-2.6.3/logs/yarn-supermap-nodemanager-slave1.out
检查集群状态
- supermap@master:~/hadoop-2.6.3$ ./bin/hdfs dfsadmin -report
- Configured Capacity: 58405412864 (54.39 GB)
- Present Capacity: 51191595008 (47.68 GB)
- DFS Remaining: 51191545856 (47.68 GB)
- DFS Used: 49152 (48 KB)
- DFS Used%: 0.00%
- Under replicated blocks: 0
- Blocks with corrupt replicas: 0
- Missing blocks: 0
- -------------------------------------------------
- Live datanodes (2):
- Name: 192.168.12.132:50010 (slave1)
- Hostname: slave1
- Decommission Status : Normal
- Configured Capacity: 29202706432 (27.20 GB)
- DFS Used: 24576 (24 KB)
- Non DFS Used: 3606908928 (3.36 GB)
- DFS Remaining: 25595772928 (23.84 GB)
- DFS Used%: 0.00%
- DFS Remaining%: 87.65%
- Configured Cache Capacity: 0 (0 B)
- Cache Used: 0 (0 B)
- Cache Remaining: 0 (0 B)
- Cache Used%: 100.00%
- Cache Remaining%: 0.00%
- Xceivers: 1
- Last contact: Fri Jan 08 16:51:01 CST 2016
- Name: 192.168.12.133:50010 (slave2)
- Hostname: slave2
- Decommission Status : Normal
- Configured Capacity: 29202706432 (27.20 GB)
- DFS Used: 24576 (24 KB)
- Non DFS Used: 3606908928 (3.36 GB)
- DFS Remaining: 25595772928 (23.84 GB)
- DFS Used%: 0.00%
- DFS Remaining%: 87.65%
- Configured Cache Capacity: 0 (0 B)
- Cache Used: 0 (0 B)
- Cache Remaining: 0 (0 B)
- Cache Used%: 100.00%
- Cache Remaining%: 0.00%
- Xceivers: 1
- Last contact: Fri Jan 08 16:51:01 CST 2016
查看集群
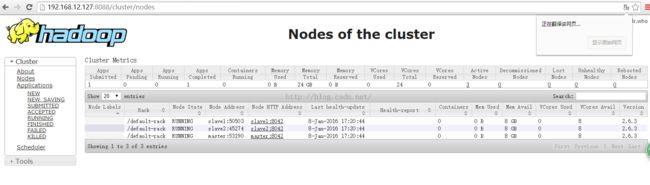
测试集群
使用hadoop自带的实例进行测试
首先在hdfs中创建一个文件夹
bin/hdfs dfs -mkdir /input
导入一个文件到hdfs中
bin/hdfs dfs -copyFromLocal LICENSE.txt /input
进入share/hadoop/mapreduce目录下执行
../../../bin/hadoop jar hadoop-mapreduce-examples-2.6.3.jar wordcount /input /output
- supermap@master:~/hadoop-2.6.3/share/hadoop/mapreduce$ ../../../bin/hadoop jar hadoop-mapreduce-examples-2.6.3.jar wordcount /input /output
- 16/01/08 16:56:52 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.12.127:8032
- 16/01/08 16:56:53 INFO input.FileInputFormat: Total input paths to process : 0
- 16/01/08 16:56:53 INFO mapreduce.JobSubmitter: number of splits:0
- 16/01/08 16:56:54 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1452243042219_0002
- 16/01/08 16:56:55 INFO impl.YarnClientImpl: Submitted application application_1452243042219_0002
- 16/01/08 16:56:55 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1452243042219_0002/
- 16/01/08 16:56:55 INFO mapreduce.Job: Running job: job_1452243042219_0002
- 16/01/08 16:57:03 INFO mapreduce.Job: Job job_1452243042219_0002 running in uber mode : false
- 16/01/08 16:57:03 INFO mapreduce.Job: map 0% reduce 0%
- 16/01/08 16:57:10 INFO mapreduce.Job: map 0% reduce 100%
- 16/01/08 16:57:11 INFO mapreduce.Job: Job job_1452243042219_0002 completed successfully
- 16/01/08 16:57:11 INFO mapreduce.Job: Counters: 38
- File System Counters
- FILE: Number of bytes read=0
- FILE: Number of bytes written=106221
- FILE: Number of read operations=0
- FILE: Number of large read operations=0
- FILE: Number of write operations=0
- HDFS: Number of bytes read=0
- HDFS: Number of bytes written=0
- HDFS: Number of read operations=3
- HDFS: Number of large read operations=0
- HDFS: Number of write operations=2
- Job Counters
- Launched reduce tasks=1
- Total time spent by all maps in occupied slots (ms)=0
- Total time spent by all reduces in occupied slots (ms)=3848
- Total time spent by all reduce tasks (ms)=3848
- Total vcore-milliseconds taken by all reduce tasks=3848
- Total megabyte-milliseconds taken by all reduce tasks=3940352
- Map-Reduce Framework
- Combine input records=0
- Combine output records=0
- Reduce input groups=0
- Reduce shuffle bytes=0
- Reduce input records=0
- Reduce output records=0
- Spilled Records=0
- Shuffled Maps =0
- Failed Shuffles=0
- Merged Map outputs=0
- GC time elapsed (ms)=24
- CPU time spent (ms)=400
- Physical memory (bytes) snapshot=167751680
- Virtual memory (bytes) snapshot=843304960
- Total committed heap usage (bytes)=110624768
- Shuffle Errors
- BAD_ID=0
- CONNECTION=0
- IO_ERROR=0
- WRONG_LENGTH=0
- WRONG_MAP=0
- WRONG_REDUCE=0
- File Output Format Counters
- Bytes Written=0
查看结果
bin/hadoop fs -cat /output/*
执行结束后可以通过 http://master:8088 查看任务

转载自:http://blog.csdn.net/chinagissoft/article/details/50481194