ARRAY使用的一些实例
data missing; input x y$ z$ m; cards; . . . 1 2 . 3 . ; run; data result; set missing; array char _character_; array numr _numeric_; do over char; if char eq "" then char="null"; end; do over numr; if numr eq . then numr=0; end; run;
结果显示:
![]()
需求:
如果给定一个数据集,发现其中有很多变量确实,但是事先又不知道到底是哪些变量缺失,而且该数据集数据结构非常不稳定,这次的变量数和下次的变量数可能不一样,所以,尽管SAS有一个过程步PROC STDIZE可以完成类似的需求,但是对于这种需求是无法完成的,除非每次调用程序的时候更改PROC STDIZE的VAR变量列表,这在实际项目中时不可能的,主要原因是维护代码成本太高。
程序解读:
1)程序声明了两个数组语句,一个是所有字符变量,一个是所有数值变量。
2)DO OVER CHAR 语句是循环语句,意思是循环所有的数组CHAR对应的变量(这里当然是所有的字符变量),每循环一次,程序将执行一次IF CHAR语句,如果CHAR EQ ""条件为真,则执行CHAR="null",否则不执行。
3)循环完毕所有的字符变量后,程序继续执行下面的DO OVER NUMR语句,原理和上面类似。
4)执行完两个循环语句后,系统执行RUN语句,输出第一条观测。程序跳回至DATA步开头,再次执行第二条观测,依此类推。
data score; input id$ x y z; cards; a 75 84 65 b 54 74 71 c 51 56 52 d 50 50 60 ; run; data qualify; set score; k=0; array chengji(3) x y z; array base(3)_temporary_ (60,60,60); do i=1 to 3; if chengji(i) ge base(i) then k+1;; end; if k=3 then output qualify; run;
结果如下:
score数据集:
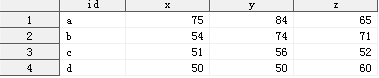
Qualify数据集:
![]()
3)对第二条到最后一条观测,系统经过类似的执行,最后满足要求的显然只有第一条观测。
data single;
input id$ q1$ q2$ q3$ @@;
cards;
01 a b c 02 a b a
03 b a c 04 a b c
;
run;
data correct(drop=i);
k=0;
set single;
array q(3);
array crt(3) $_temporary_('a','b','c');
do i=1 to 3;
if q(i)=crt(i) then k+1;
end;
run;

correct数据集:

需求如下:
对数据集single,一共有三道选择题,四个学生都给出了自己的答案,而每一题的正确答案只有一个,分别是a;b;c。试统计全部正确回答三个问题的学生。
程序解读:
参考上面的2.统计成绩及格人数
data a; input x1-x7; cards; 23 44 81 13 42 34 26 14 18 10 20 33 11 50 ; run; data final; set a; array arr(1:7) x:; array copy(1:7) cx1-cx7; do m=1 to dim(arr); copy(m)=arr(m); end; do i=1 to dim(copy); do j=i+1 to dim(copy); if copy(j) > copy(i) then do; temp=copy(j);copy(j)=copy(i);copy(i)=temp; end; end; end; run;

final数据集:
![]()
2)从第八行到倒数第二行程序执行冒泡算法,通过两个DO循环语句,在嵌套DO语句里面,通过比较相邻两个新变量的值,如果后一个变量值大于前面的变量值,借用一个中间临时变量TEMP对调两者,如此循环直到最后一个变量。
程序如下:
options symbolgen;
data missing;
input n1 n2 n3 n4 n5 n6 n7 n8 c1$ c2$ c3$ c4$;
datalines;
1 . 1 . 1 . 1 4 a . c .
1 1 . . 2 . . 5 e . g h
1 . 1 . 3 . . 6 . . k l
1 . . . . . . . a b c d
;
data _null_;
if 0 then
set missing nobs=obs;
array num_vars[*] _NUMERIC_;
array char_vars[*] _CHARACTER_;
call symputx('num_qty', dim(num_vars));
call symputx('char_qty', dim(char_vars));
call symputx('m_obs',obs);
stop;
run;
%put &num_qty &char_qty &m_obs;
data _null_;
set missing end=finished;
array num_vars[*] _NUMERIC_;
array char_vars[*] _CHARACTER_;
array num_miss [&num_qty] (&num_qty * 0);
array char_miss [&char_qty] (&char_qty * 0);
length list $ 50;
do i=1 to dim(num_vars);
if num_vars(i) eq . then num_miss(i)+1;
end;
do i=1 to dim(char_vars);
if char_vars(i) eq '' then char_miss(i)+1;
end;
if finished then do;
do i=1 to dim(num_vars);
if num_miss(i)/&m_obs. ge 0.7 then list=trim(list)||' '||trim(vname(num_vars(i)));
end;
do i=1 to dim(char_vars);
if char_miss(i)/&m_obs. ge 0.7 then list=trim(list)||' '||trim(vname(char_vars(i)));
end;
call symputx('mlist',list);
end;
run;
%put &mlist;
data notmiss;
set missing(drop=&mlist);
run;

Notmiss数据集如下:
