OCR开发心得
介绍
几周前,我在空闲时间使用泰比公司(ABBYY)的FlexiCapture Engine试用版创建了一些简单的OCR应用。FlexiCapture Engine 是一款用于创建数据捕捉应用的SDK,能够打开图像、PDF文件及扫描文件,对有价值的数据及字段进行分类及提取。提取的数据可导出至Excel、XML、CSV、PDF 格式文件,也可以导出至外部数据库、DMS及ECM系统。
开始创建
在已经装有开发工具(如MS Visual Studio)的电脑上安装SDK,之后SDK会出现10多种示例应用程序,包括C++、C#、VB.NET、VB、Delphi、Java及数种脚本语言(JavaScript、Perl及 VBScript)的示例。如需快速着手开发,你可以使用代码开发库。代码开发库会对SDK编程的方方面面进行介绍。每一代码开发库组包含一个或多个代码片段,并附有完成任务的逐步描述。
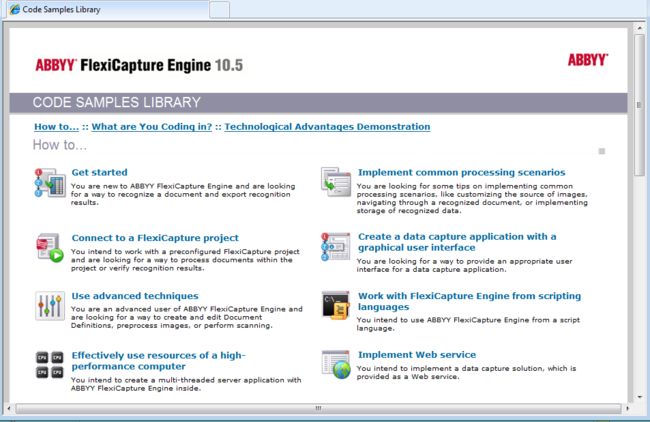
选择需要处理的任务,然后阅读完成任务的步骤介绍,查看已备好样本的源代码或运行准备执行。
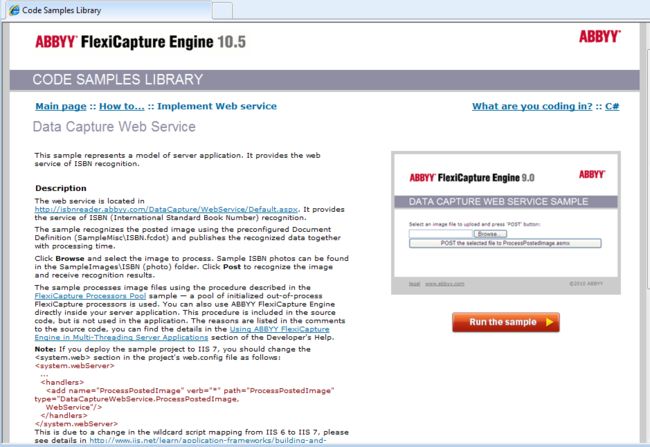
我想单独介绍的其中一个样本是FlexiCapture Engine代码片段,该样本提供了一个简短代码片段集,显示了快速进入应用程序界面(API)并开始开发应用程序不可缺少的典型应用范围及编程任务。
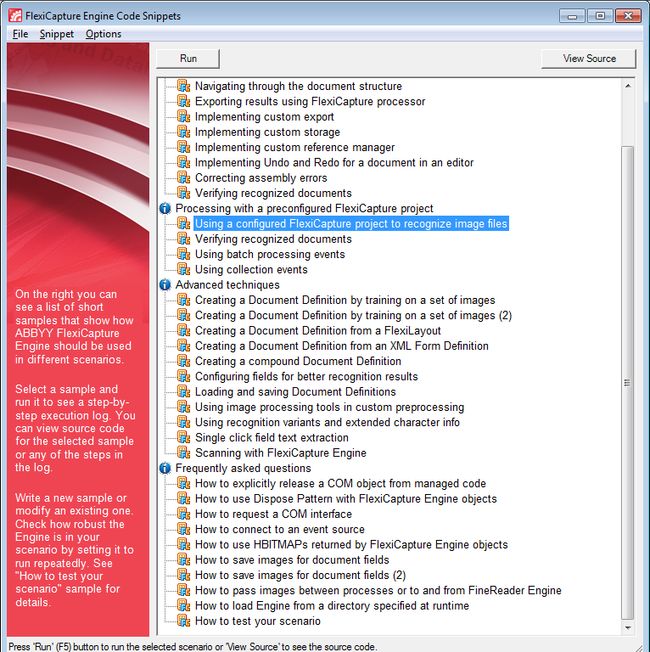
现在,让我们看看使用FlexiCapture Engine识别文件及导出结果的基本方法。
利用ABBYY FlexiCapture预配置项目进行处理
ABBYY FlexiCapture Engine能够处理ABBYY FlexiCapture项目内的固定格式表格及灵活格式文件。要使用此功能,必须利用ABBYY FlexiCapture先创建一个项目,然后在ABBYY FlexiCapture Engine中使用该项目。ABBYY FlexiCapture Engine工具包及样本库中已包含了一个备好的FlexiCapture样本项目。
一个FlexiCapture项目是一个将文档集和处理这些文档所需设置统一起来的单一环境。这些需要处理的文档集称作批量文件。项目结构(包括批量文件及零散文件)将在FlexiCapture Engine对象中重现。项目最关键的部分是一套针对固定格式及灵活格式页面布局的【文件定义】,该【文件定义】用于数据提取,将决定所得数据的质量。
为了处理文件,我在项目中将图像添加至一批量处理中。在识别过程中,程序选择适合文件页面的【文件定义】,应用该【文件定义】,然后利用选定的【文件定义】提取文件相关区域的数据。处理后的数据随后被转至外部文件夹。
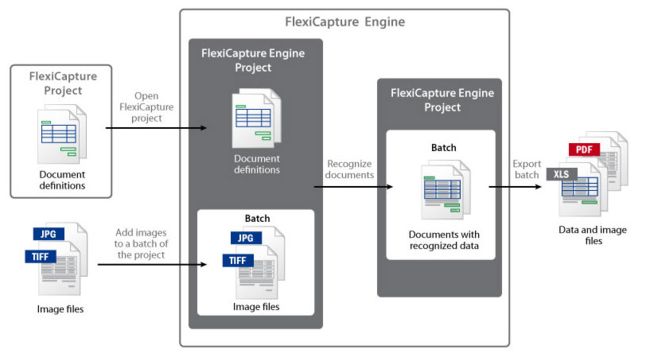
在单一预配置项目中识别文件并导出其结果,需要采取以下基本步骤:
步骤1:加载FlexiCapture Engine
在利用ABBYY FlexiCapture Engine开始处理任务之前,需要创建引擎对象。引擎对象是ABBYY FlexiCapture Engine对象层级结构中的顶级对象,是ABBYY FlexiCapture Engine唯一可在外部创建的对象。
要创建引擎对象,需要使用InitializeEngine (InitializeEngineEx)导出功能。以下是ABBYY FlexiCapture Engine在C#中加载和初始化过程中的样本代码:
private IEngine loadEngine()
{
IEngine engine;
int hResult = InitializeEngine( FceConfig.GetDeveloperSN(), null, null, out engine );
Marshal.ThrowExceptionForHR( hResult );
return engine;
}
导出的引擎对象为单体形态,因此在使用ABBYY FlexiCapture Engine的单一实例应用中,仅可以创建一个此类对象。创建引擎对象的重复性尝试将回归同一对象。需要重点注意的是创建引擎对象的过程比较久,因为不仅需要加载FCEngine.dll,还需要加载一整套其它DLLs。
在创建引擎对象之后,就能够在我的应用中使用ABBYY FlexiCapture Engine对象。然后可以根据选定的处理方法打开一个FlexiCapture项目或创建FlexiCapture处理程序。我会考虑使用第一种方法——通过配置好的FlexiCapture项目进行处理。
步骤2:打开项目
要准备预配置ABBYY FlexiCapture项目处理文件所需的程序,需要打开在ABBYY FlexiCapture中创建的项目。一个项目含有处理某一类型文件所需的所有设置:图像导入参数、文件定义及批量文件处理。该项目文件夹必须含有该项目文件(.fcproj file)以及一个带有【文件定义】的文件夹。
在ABBYY FlexiCapture Engine中,该项目由项目对象表示。要打开一个现有项目,可以使用引擎对象的OpenProject方法,并将完整路径加入该项目文件作为第一个参数。这是用C#打开项目时的代码示例:
//打开该项目示例
IProject project = engine.OpenProject("D:\\TestProject\\TestProject.fcproj\\Invoices_eng.fcproj" );
步骤3:添加图像
项目打开后,就可以将新图像添加至该项目中进行处理。图像添加后,这些图像被分组成文件,而这些文件会被添加至批处理。向批处理分配文件的原则由用户自定义:可以在单个批处理中处理所有文件,或将同一日期添加的文件或单一批次扫描的批量文件生成批处理。
FlexiCapture Engine提供一组复制了项目逻辑结构的对象。批量处理与项目对象分别对应一个批处理及一个项目。项目对象含有一个批量处理对象集,由批量处理对象代表。这个对象集可以通过项目对象的批量处理属性获得。每一个批处理含有一套文件,可以通过项目对象的批量处理属性获得。文件由文件对象表示,一份文件由文件对象表示。
以下是添加图像的C#代码格式:
//添加一个新的批量处理
IBatch batch = project.Batches.AddNew( "TestBatch" );
//打开批量处理
batch.Open();
//添加图像到批量处理
batch.AddImage("D:\\SampleImages\\Invoices_1.tif" );
batch.AddImage("D:\\SampleImages\\Invoices_2.tif" );
batch.AddImage("D:\\SampleImages\\Invoices_3.tif" );
步骤4:识别文件
在文件处理过程中,程序选择适合文件页面的【文件定义】,应用该【文件定义】,然后利用选定的【文件定义】提取文件相关区域的数据。ABBYY FlexiCapture Engine允许通过使用一种方法完成所有这些文件的处理步骤。一种识别文件的简单途径是使用批量处理对象的识别方法。你可以指定处理文件、识别方式以及适用的【文件定义】。
//在批量处理中识别所有图像
batch.Recognize( null, RecognitionModeEnum.RM_ReRecognizeMinimal, null );
步骤5:导出结果
文件被识别后,需要保存识别的数据。首先,可以将提取的数据保存至XLS、DBF、TXT、CSV或XML格式的文件中,然后将文件的电子文档保存为需要的格式,如PDF或PDF/A格式。这里可以使用项目或批量处理对象的导出方法。前者允许你从多个批处理中将结果导出,而后者用于将批处理中的多个文件导出。在导出时,可以通过ExportParams对象改变导出参数。例如,可以指定是否将字段坐标导入XML,或为图像文件设定压缩比等等。在默认模式下,【文件定义】中指定的参数将被使用。
//导出结果
batch.Export( null, null );
如果由于某些原因ABBYY FlexiCapture Engine提供的导出方法不合适我的任务,那么可以使用我自己的导出程序。例如,我可以转化一份文件的所有字段,并将他们的数值导出至自定义格式文件。样本代码可以在我之前提到的代码片段样本中获得。
完成批处理工作后,我调出对应批量处理对象的【关闭】方法关闭批量处理,并释放一些资源(打开的批量处理不能被关闭)。该方法同样适用于项目——我需要调出【项目】目标的【关闭】方法释放一些资源(打开的项目不能被关闭)。
//关闭和删除批处理
} finally {
batch.Close(); // Before the batch could be deleted, it has to be closed
project.Batches.DeleteAll();
}
最后步骤:卸载FlexiCapture Engine
使用ABBYY FlexiCapture Engine完成工作后,我需要使用DeinitializeEngine功能卸载引擎对象。
private void unloadEngine( ref IEngine engine )
{
engine = null;
int hResult = DeinitializeEngine();
Marshal.ThrowExceptionForHR( hResult );
}
在此,我分享一个非常有用的心得:你可以使用引擎对象的StartLogging方法让错误、警告及方法调用记录进入日志文件,同时它也可以帮助追踪未被删除及正确释放的对象。
结论
如果你正在开发用于处理诸如发票、医疗表格、投保单、问卷调查表、测试表及身份证等的数据捕捉解决方案,开发人员可以考虑使用ABBYY FlexiCapture Engine SDK。它还可以针对各种不同的扫描设备和终端创建自定义数据捕捉解决方案。除了通过预配置FlexiCapture项目处理任务之外,FlexiCapture Engine还有其它方法实施数据捕捉应用——FlexiCapture Engine提供就绪的应用程序界面(API)用于创建简单的【文件定义】,而无需使用FlexiCapture项目。这又是另一个完整的主题,我会尽快在另一篇心得中分享。
关于下载
我是在ABBYY官网提交申请下载的免费试用版本,试用申请页面请点击。