Flume架构与源码分析-核心组件分析
首先所有核心组件都会实现org.apache.flume.lifecycle.LifecycleAware接口:
public interface LifecycleAware {
public void start(); public void stop(); public LifecycleState getLifecycleState();
}
start方法在整个Flume启动时或者初始化组件时都会调用start方法进行组件初始化,Flume组件出现异常停止时会调用stop,getLifecycleState返回组件的生命周期状态,有IDLE, START, STOP, ERROR四个状态。
如果开发的组件需要配置,如设置一些属性;可以实现org.apache.flume.conf.Configurable接口:
public interface Configurable {
public void configure(Context context);
}
Flume在启动组件之前会调用configure来初始化组件一些配置。
1、Source
Source用于采集日志数据,有两种实现方式:轮训拉取和事件驱动机制;Source接口如下:
public interface Source extends LifecycleAware, NamedComponent {
public void setChannelProcessor(ChannelProcessor channelProcessor); public ChannelProcessor getChannelProcessor();
}
Source接口首先继承了LifecycleAware接口,然后只提供了ChannelProcessor的setter和getter接口,也就是说它的的所有逻辑的实现应该在LifecycleAware接口的start和stop中实现;ChannelProcessor之前介绍过用来进行日志流的过滤和Channel的选择及调度。
而 Source 是通过 SourceFactory 工厂创建,默认提供了 DefaultSourceFactory ,其首先通过 Enum 类型 org.apache.flume.conf.source.SourceType 查找默认实现,如exec ,则找到 org.apache.flume.source.ExecSource 实现,如果找不到直接Class.forName(className) 创建。
Source 提供了两种机制: PollableSource (轮训拉取)和 EventDrivenSource (事件驱动):
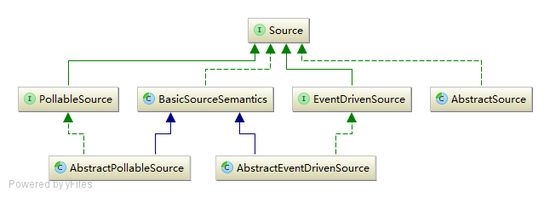
PollableSource 默认提供了如下实现:
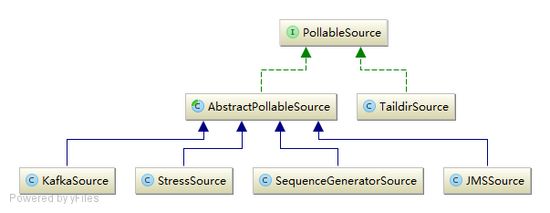
比如 JMSSource 实现使用 javax.jms.MessageConsumer.receive(pollTimeout) 主动去拉取消息。
EventDrivenSource 默认提供了如下实现:

比如 NetcatSource 、 HttpSource 就是事件驱动,即被动等待;比如 HttpSource 就是内部启动了一个内嵌的 Jetty 启动了一个 Servlet 容器,通过 FlumeHTTPServlet 去接收消息。
Flume 提供了 SourceRunner 用来启动 Source 的流转:
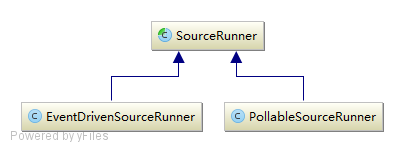
从本组件也可以看出: 1 、首先要初始化 ChannelProcessor ,其实现时初始化过滤器链; 2 、接着启动 Source 并更改本组件的状态。
public class PollableSourceRunner extends SourceRunner {
@Override
public void start() {
PollableSource source = (PollableSource) getSource();
ChannelProcessor cp = source.getChannelProcessor();
cp.initialize();
source.start();
runner = new PollingRunner();
runner.source = source;
runner.counterGroup = counterGroup;
runner.shouldStop = shouldStop;
runnerThread = new Thread(runner);
runnerThread.setName(getClass().getSimpleName() + "-" +
source.getClass().getSimpleName() + "-" + source.getName());
runnerThread.start();
lifecycleState = LifecycleState.START;
}
}
而 PollingRunner 首先初始化组件,但是又启动了一个线程 PollingRunner ,其作用就是轮训拉取数据:
@Override public void run() { while (!shouldStop.get()) { //如果没有停止,则一直在死循环运行
counterGroup.incrementAndGet("runner.polls"); try { //调用PollableSource的process方法进行轮训拉取,然后判断是否遇到了失败补偿
if (source.process().equals(PollableSource.Status.BACKOFF)) {/
counterGroup.incrementAndGet("runner.backoffs"); //失败补偿时暂停线程处理,等待超时时间之后重试
Thread.sleep(Math.min(
counterGroup.incrementAndGet("runner.backoffs.consecutive")
* source.getBackOffSleepIncrement(), source.getMaxBackOffSleepInterval()));
} else {
counterGroup.set("runner.backoffs.consecutive", 0L);
}
} catch (InterruptedException e) {
}
}
}
}
}
Flume 在启动时会判断 Source 是 PollableSource 还是 EventDrivenSource 来选择使用 PollableSourceRunner 还是 EventDrivenSourceRunner 。
比如 HttpSource 实现,其通过 FlumeHTTPServlet 接收消息然后:
List<Event> events = Collections.emptyList(); //create empty list //首先从请求中获取Event events = handler.getEvents(request); //然后交给ChannelProcessor进行处理 getChannelProcessor().processEventBatch(events);
到此基本的 Source 流程就介绍完了,其作用就是监听日志,采集,然后交给ChannelProcessor 进行处理。
2 、 Channel
Channel 用于连接 Source 和 Sink , Source 生产日志发送到 Channel , Sink 从Channel 消费日志;也就是说通过 Channel 实现了 Source 和 Sink 的解耦,可以实现多对多的关联,和 Source 、 Sink 的异步化。
之前 Source 采集到日志后会交给 ChannelProcessor 处理,那么接下来我们先从ChannelProcessor 入手,其依赖三个组件:
private final ChannelSelector selector; //Channel选择器 private final InterceptorChain interceptorChain; //拦截器链 private ExecutorService execService; //用于实现可选Channel的ExecutorService,默认是单线程实现
接下来看下其是如何处理 Event 的:
public void processEvent(Event event) { event = interceptorChain.intercept(event); //首先进行拦截器链过滤
if (event == null) { return;
}
List<Event> events = new ArrayList<Event>(1);
events.add(event); //通过Channel选择器获取必须成功处理的Channel,然后事务中执行
List<Channel> requiredChannels = selector.getRequiredChannels(event); for (Channel reqChannel : requiredChannels) {
executeChannelTransaction(reqChannel, events, false);
} //通过Channel选择器获取可选的Channel,这些Channel失败是可以忽略,不影响其他Channel的处理
List<Channel> optionalChannels = selector.getOptionalChannels(event); for (Channel optChannel : optionalChannels) {
execService.submit(new OptionalChannelTransactionRunnable(optChannel, events));
}
}
另外内部还提供了批处理实现方法 processEventBatch ;对于内部事务实现的话可以参考 executeChannelTransaction 方法,整体事务机制类似于 JDBC :
private static void executeChannelTransaction(Channel channel, List<Event> batch, boolean isOptional) { //1、获取Channel上的事务
Transaction tx = channel.getTransaction();
Preconditions.checkNotNull(tx, "Transaction object must not be null"); try { //2、开启事务
tx.begin(); //3、在Channel上执行批量put操作
for (Event event : batch) {
channel.put(event);
} //4、成功后提交事务
tx.commit();
} catch (Throwable t) { //5、异常后回滚事务
tx.rollback(); if (t instanceof Error) {
LOG.error("Error while writing to channel: " +
channel, t); throw (Error) t;
} else if(!isOptional) {//如果是可选的Channel,异常忽略
throw new ChannelException("Unable to put batch on required " + "channel: " + channel, t);
}
} finally { //最后关闭事务
tx.close();
}
}
Interceptor 用于过滤 Event ,即传入一个 Event 然后进行过滤加工,然后返回一个新的 Event ,接口如下:
public interface Interceptor {
public void initialize(); public Event intercept(Event event); public List<Event> intercept(List<Event> events); public void close();
}
可以看到其提供了 initialize 和 close 方法用于启动和关闭; intercept 方法用于过滤或加工 Event 。比如 HostInterceptor 拦截器用于获取本机 IP 然后默认添加到 Event 的字段为 host 的 Header 中。
接下来就是 ChannelSelector 选择器了,其通过如下方式创建:
//获取ChannelSelector配置,比如agent.sources.s1.selector.type = replicatingChannelSelectorConfiguration selectorConfig = config.getSelectorConfiguration();//使用Source关联的Channel创建,比如agent.sources.s1.channels = c1 c2ChannelSelector selector = ChannelSelectorFactory.create(sourceChannels, selectorConfig);
ChannelSelector 默认提供了两种实现:复制和多路复用:
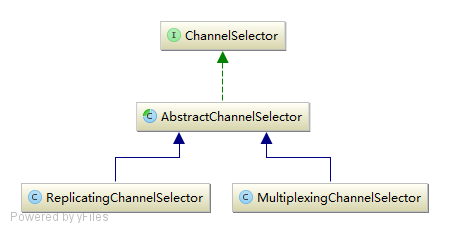
默认实现是复制选择器 ReplicatingChannelSelector ,即把接收到的消息复制到每一个 Channel ;多路复用选择器 MultiplexingChannelSelector 会根据 Event Header 中的参数进行选择,以此来选择使用哪个 Channel 。
而 Channel 是 Event 中转的地方, Source 发布 Event 到 Channel , Sink 消费Channel 的 Event ; Channel 接口提供了如下接口用来实现 Event 流转:
public interface Channel extends LifecycleAware, NamedComponent {
public void put(Event event) throws ChannelException; public Event take() throws ChannelException; public Transaction getTransaction();
}
put 用于发布 Event , take 用于消费 Event , getTransaction 用于事务支持。默认提供了如下 Channel 的实现:
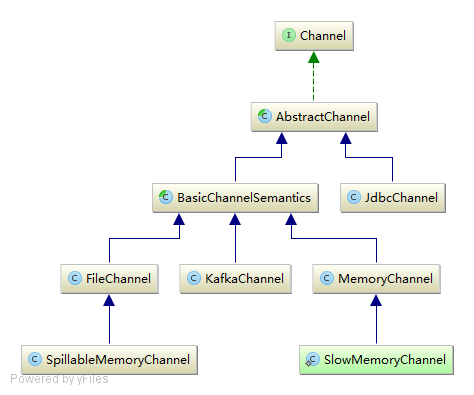
对于 Channel 的实现我们后续单独章节介绍。
3 、 Sink
Sink 从 Channel 消费 Event ,然后进行转移到收集 / 聚合层或存储层。 Sink 接口如下所示:
public interface Sink extends LifecycleAware, NamedComponent {
public void setChannel(Channel channel); public Channel getChannel(); public Status process() throws EventDeliveryException; public static enum Status {
READY, BACKOFF
}
}
类似于 Source ,其首先继承了 LifecycleAware ,然后提供了 Channel 的getter/setter 方法,并提供了 process 方法进行消费,此方法会返回消费的状态,READY 或 BACKOFF 。
Sink 也是通过 SinkFactory 工厂来创建,其也提供了 DefaultSinkFactory 默认工厂,比如传入 hdfs ,会先查找 Enum org.apache.flume.conf.sink.SinkType ,然后找到相应的默认处理类 org.apache.flume.sink.hdfs.HDFSEventSink ,如果没找到默认处理类,直接通过 Class.forName(className) 进行反射创建。
我们知道 Sink 还提供了分组功能,用于把多个 Sink 聚合为一组进行使用,内部提供了 SinkGroup 用来完成这个事情。此时问题来了,如何去调度多个 Sink ,其内部使用了 SinkProcessor 来完成这个事情,默认提供了故障转移和负载均衡两个策略。
首先 SinkGroup 就是聚合多个 Sink 为一组,然后将多个 Sink 传给SinkProcessorFactory 进行创建 SinkProcessor ,而策略是根据配置文件中配置的如agent.sinkgroups.g1.processor.type = load_balance 来选择的。
SinkProcessor 提供了如下实现:
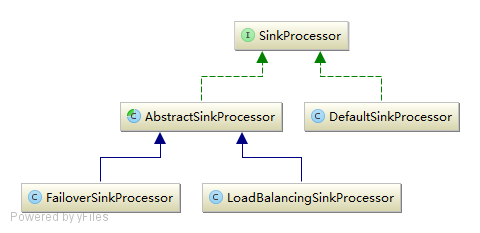
DefaultSinkProcessor :默认实现,用于单个 Sink 的场景使用。
FailoverSinkProcessor :故障转移实现:
public Status process() throws EventDeliveryException {
Long now = System.currentTimeMillis(); //1、首先检查失败队列的头部的Sink是否已经过了失败补偿等待时间了
while(!failedSinks.isEmpty() && failedSinks.peek().getRefresh() < now) { //2、如果可以使用了,则从失败Sink队列获取队列第一个Sink
FailedSink cur = failedSinks.poll();
Status s; try {
s = cur.getSink().process(); //3、使用此Sink进行处理
if (s == Status.READY) { //4、如果处理成功
liveSinks.put(cur.getPriority(), cur.getSink()); //4.1、放回存活Sink队列
activeSink = liveSinks.get(liveSinks.lastKey());
} else {
failedSinks.add(cur); //4.2、如果此时不是READY,即BACKOFF期间,再次放回失败队列
} return s;
} catch (Exception e) {
cur.incFails(); //5、如果遇到异常了,则增加失败次数,并放回失败队列
failedSinks.add(cur);
}
}
Status ret = null; while(activeSink != null) { //6、此时失败队列中没有Sink能处理了,那么需要使用存活Sink队列进行处理
try {
ret = activeSink.process(); return ret;
} catch (Exception e) { //7、处理失败进行转移到失败队列
activeSink = moveActiveToDeadAndGetNext();
}
} throw new EventDeliveryException("All sinks failed to process, " + "nothing left to failover to");
}
失败队列是一个优先级队列,使用 refresh 属性排序,而 refresh 是通过如下机制计算的:
refresh = System.currentTimeMillis() + Math.min(maxPenalty, (1 << sequentialFailures) * FAILURE_PENALTY);
其中 maxPenalty 是最大等待时间,默认 30s ,而 (1 << sequentialFailures) * FAILURE_PENALTY) 用于实现指数级等待时间递增, FAILURE_PENALTY 是 1s 。
LoadBalanceSinkProcessor :用于实现 Sink 的负载均衡,其通过 SinkSelector 进行实现,类似于 ChannelSelector 。 LoadBalanceSinkProcessor 在启动时会根据配置,如 agent.sinkgroups.g1.processor.selector = random 进行选择,默认提供了两种选择器:
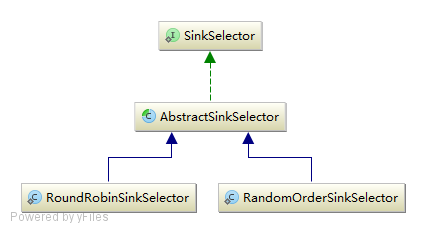
LoadBalanceSinkProcessor 使用如下机制进行负载均衡:
public Status process() throws EventDeliveryException {
Status status = null; //1、使用选择器创建相应的迭代器,也就是用来选择Sink的迭代器
Iterator<Sink> sinkIterator = selector.createSinkIterator(); while (sinkIterator.hasNext()) {
Sink sink = sinkIterator.next(); try { //2、选择器迭代Sink进行处理,如果成功直接break掉这次处理,此次负载均衡就算完成了
status = sink.process(); break;
} catch (Exception ex) { //3、失败后会通知选择器,采取相应的失败退避补偿算法进行处理
selector.informSinkFailed(sink);
LOGGER.warn("Sink failed to consume event. "
+ "Attempting next sink if available.", ex);
}
} if (status == null) { throw new EventDeliveryException("All configured sinks have failed");
} return status;
}
如上的核心就是怎么创建迭代器,如何进行失败退避补偿处理,首先我们看下RoundRobinSinkSelector 实现,其内部是通过通用的 RoundRobinOrderSelector 选择器实现:
public Iterator<T> createIterator() { //1、获取存活的Sink索引,
List<Integer> activeIndices = getIndexList(); int size = activeIndices.size(); //2、如果上次记录的下一个存活Sink的位置超过了size,那么从队列头重新开始计数
if (nextHead >= size) {
nextHead = 0;
} //3、获取本次使用的起始位置
int begin = nextHead++; if (nextHead == activeIndices.size()) {
nextHead = 0;
} //4、从该位置开始迭代,其实现类似于环形队列,比如整个队列是5,起始位置是3,则按照 3、4、0、1、2的顺序进行轮训,实现了轮训算法
int[] indexOrder = new int[size]; for (int i = 0; i < size; i++) {
indexOrder[i] = activeIndices.get((begin + i) % size);
} //indexOrder是迭代顺序,getObjects返回相关的Sinks;
return new SpecificOrderIterator<T>(indexOrder, getObjects());
}
getIndexList 实现如下:
protected List<Integer> getIndexList() {
long now = System.currentTimeMillis();
List<Integer> indexList = new ArrayList<Integer>();
int i = 0;
for (T obj : stateMap.keySet()) {
if (!isShouldBackOff() || stateMap.get(obj).restoreTime < now) { indexList.add(i);
} i++;
} return indexList;
}
isShouldBackOff() 表示是否开启退避算法支持,如果不开启,则认为每个 Sink 都是存活的,每次都会重试,通过 agent.sinkgroups.g1.processor.backoff = true 配置开启,默认 false ; restoreTime 和之前介绍的 refresh 一样,是退避补偿等待时间,算法类似,就不多介绍了。
那么什么时候调用 Sink 进行消费呢?其类似于 SourceRunner , Sink 提供了SinkRunner 进行轮训拉取处理, SinkRunner 会轮训调度 SinkProcessor 消费 Channel的消息,然后调用 Sink 进行转移。 SinkProcessor 之前介绍过,其负责消息复制 / 路由。
SinkRunner 实现如下:
public void start() {
SinkProcessor policy = getPolicy();
policy.start();
runner = new PollingRunner();
runner.policy = policy;
runner.counterGroup = counterGroup;
runner.shouldStop = new AtomicBoolean();
runnerThread = new Thread(runner);
runnerThread.setName("SinkRunner-PollingRunner-" +
policy.getClass().getSimpleName());
runnerThread.start();
lifecycleState = LifecycleState.START;}
即获取 SinkProcessor 然后启动它,接着启动轮训线程去处理。 PollingRunner 线程负责轮训消息,核心实现如下:
public void run() { while (!shouldStop.get()) { //如果没有停止
try { if (policy.process().equals(Sink.Status.BACKOFF)) {//如果处理失败了,进行退避补偿处理
counterGroup.incrementAndGet("runner.backoffs");
Thread.sleep(Math.min(
counterGroup.incrementAndGet("runner.backoffs.consecutive")
* backoffSleepIncrement, maxBackoffSleep)); //暂停退避补偿设定的超时时间
} else {
counterGroup.set("runner.backoffs.consecutive", 0L);
}
} catch (Exception e) { try {
Thread.sleep(maxBackoffSleep); //如果遇到异常则等待最大退避时间
} catch (InterruptedException ex) {
Thread.currentThread().interrupt();
}
}
}
}
整体实现类似于 PollableSourceRunner 实现,整体处理都是交给 SinkProcessor 完成的。 SinkProcessor 会轮训 Sink 的 process 方法进行处理;此处以 LoggerSink 为例:
@Overridepublic Status process() throws EventDeliveryException {
Status result = Status.READY;
Channel channel = getChannel(); //1、获取事务
Transaction transaction = channel.getTransaction();
Event event = null; try { //2、开启事务
transaction.begin(); //3、从Channel获取Event
event = channel.take(); if (event != null) { if (logger.isInfoEnabled()) {
logger.info("Event: " + EventHelper.dumpEvent(event, maxBytesToLog));
}
} else {//4、如果Channel中没有Event,则默认进入故障补偿机制,即防止死循环造成CPU负载高
result = Status.BACKOFF;
} //5、成功后提交事务
transaction.commit();
} catch (Exception ex) { //6、失败后回滚事务
transaction.rollback(); throw new EventDeliveryException("Failed to log event: " + event, ex);
} finally { //7、关闭事务
transaction.close();
} return result;
}
Sink 中一些实现是支持批处理的,比如 RollingFileSink :
//1、开启事务//2、批处理for (int i = 0; i < batchSize; i++) { event = channel.take(); if (event != null) {
sinkCounter.incrementEventDrainAttemptCount();
eventAttemptCounter++;
serializer.write(event);
}
}//3、提交/回滚事务、关闭事务
定义一个批处理大小然后在事务中执行批处理。