在2014年7月1日的Spark Summit上,Databricks宣布终止对Shark的开发,将重点放到Spark SQL上。Databricks表示,Spark SQL将涵盖Shark的所有特性,用户可以从Shark 0.9进行无缝的升级。现在Databricks推广的Shark相关项目一共有两个,分别是Spark SQL和新的Hive on Spark(HIVE-7292)。如下图所示: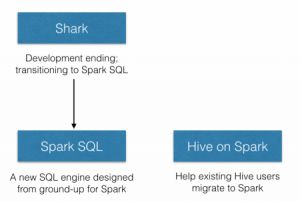
Spark SQL运行以SQL的方式来操作数据,类似Hive和Pig。其核心组件为一种新类型的RDD——JavaSchemaRDD,一个JavaSchemaRDD就好比传统关系型数据库中的一张表。JavaSchemaRDD可以从已有的RDD创建,还可以从Parquet文件、JSON数据集、HIVE、普通数据文件中创建。但现阶段(1.0.2版本)的Spark SQL还是alpha版,日后的API难免会发生变化,所以是否要使用该功能,现阶段还值得商榷。
程序示例
Bean,必须要有get方法,底层采用反射来获取各属性。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
public
static
class
Person
implements
Serializable
{
private
String
name
;
private
int
age
;
public
String
getName
(
)
{
return
name
;
}
public
int
getAge
(
)
{
return
age
;
}
public
Person
(
String
name
,
int
age
)
{
this
.
name
=
name
;
this
.
age
=
age
;
}
}
|
Spark SQL示例
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
public
static
void
main
(
String
[
]
args
)
{
SparkConf
sparkConf
=
new
SparkConf
(
)
.
setAppName
(
"JavaSparkSQL"
)
.
setMaster
(
"local[2]"
)
;
JavaSparkContext
ctx
=
new
JavaSparkContext
(
sparkConf
)
;
JavaSQLContext
sqlCtx
=
new
JavaSQLContext
(
ctx
)
;
JavaRDD
<
Person
>
people
=
ctx
.
textFile
(
"/home/yurnom/people.txt"
)
//文档内容见下文
.
map
(
line
->
{
String
[
]
parts
=
line
.
split
(
","
)
;
return
new
Person
(
parts
[
0
]
,
Integer
.
parseInt
(
parts
[
1
]
.
trim
(
)
)
)
;
//创建一个bean
}
)
;
JavaSchemaRDD
schemaPeople
=
sqlCtx
.
applySchema
(
people
,
Person
.
class
)
;
schemaPeople
.
registerAsTable
(
"people"
)
;
//注册为一张table
JavaSchemaRDD
teenagers
=
sqlCtx
.
sql
(
//执行sql语句,属性名同bean的属性名
"SELECT name FROM people WHERE age >= 13 AND age <= 19"
)
;
List
<
String
>
teenagerNames
=
teenagers
.
map
(
row
->
"Name: "
+
row
.
getString
(
0
)
)
.
collect
(
)
;
for
(
String
s
:
teenagerNames
)
{
System
.
out
.
println
(
s
)
;
}
}
|
运行结果
|
1
|
Name
:
Justin
|
people.txt文件内容
|
1
2
3
|
Michael
,
29
Andy
,
30
Justin
,
19
|
使用Parquet Files
Parquet文件允许将schema信息和数据信息固化在磁盘上,以供下一次的读取。
|
1
2
3
4
5
6
7
8
9
10
11
|
//存为Parquet文件
schemaPeople
.
saveAsParquetFile
(
"people.parquet"
)
;
//从Parquet文件中创建JavaSchemaRDD
JavaSchemaRDD
parquetFile
=
sqlCtx
.
parquetFile
(
"people.parquet"
)
;
//注册为一张table
parquetFile
.
registerAsTable
(
"parquetFile"
)
;
JavaSchemaRDD
teenagers2
=
sqlCtx
.
sql
(
"SELECT * FROM parquetFile WHERE age >= 25"
)
;
for
(
Row
r
:
teenagers2
.
collect
(
)
)
{
System
.
out
.
println
(
r
.
get
(
0
)
)
;
System
.
out
.
println
(
r
.
get
(
1
)
)
;
}
|
运行结果
|
1
2
3
4
|
29
Michael
30
Andy
|
可以看到输出属性的顺序和Bean中的不一样,此处猜测可能采用的字典序,但未经过测试证实。
JSON数据集
Spark SQL还可以采用JSON格式的文件作为输入源。people.json文件内容如下:
|
1
2
3
|
{
"name"
:
"Michael"
,
"age"
:
29
}
{
"name"
:
"Andy"
,
"age"
:
30
}
{
"name"
:
"Justin"
,
"age"
:
19
}
|
将上方程序示例中代码行8-14行替换为下方代码即可:
|
1
|
JavaSchemaRDD
schemaPeople
=
sqlCtx
.
jsonFile
(
"/home/yurnom/people.json"
)
;
|
运行结果与上文相同。此外还可以用如下方式加载JSON数据:
|
1
2
3
4
|
List
<
String
>
jsonData
=
Arrays
.
asList
(
"{\"name\":\"Yurnom\",\"age\":26}"
)
;
JavaRDD
<
String
>
anotherPeopleRDD
=
sc
.
parallelize
(
jsonData
)
;
JavaSchemaRDD
anotherPeople
=
sqlContext
.
jsonRDD
(
anotherPeopleRDD
)
;
|
连接Hive
Spark SQL运行使用SQL语句来读写Hive的数据,但由于Hive的依赖包过多,默认情况下要连接Hive需要自行添加相关的依赖包。可以使用以下命令来生成一个含有Hive依赖的Jar,而此Jar必须分发到Spark集群中的每一台机器上去。
|
1
|
SPARK_HIVE
=
true
sbt
/
sbt
assembly
/
assembly
|
最后将Hive的配置文件拷贝至conf文件夹下即可。官方Hive使用示例:
|
1
2
3
4
5
6
7
8
|
// sc is an existing JavaSparkContext.
JavaHiveContext
hiveContext
=
new
org
.
apache
.
spark
.
sql
.
hive
.
api
.
java
.
HiveContext
(
sc
)
;
hiveContext
.
hql
(
"CREATE TABLE IF NOT EXISTS src (key INT, value STRING)"
)
;
hiveContext
.
hql
(
"LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src"
)
;
// Queries are expressed in HiveQL.
Row
[
]
results
=
hiveContext
.
hql
(
"FROM src SELECT key, value"
)
.
collect
(
)
;
|
总结
Spark SQL将原本就已经封装的很好的Spark原语的使用再简化了一次,使得懂SQL语句的运维人员都可以通过Spark SQL来进行大数据分析。目前来说Spark SQL还处于alpha版本,对于开发人员的意义不大,静观后续的变化。
http://blog.selfup.cn/657.html