redis(2)、redis数据类型
redis技术目录
- 一、字符串(Strings)
- 二、列表(Lists)
- 三、哈希(Hashes)
- 四、集合(Sets)
- 五、有序集合(Sorted sets)
- 六、位图(bitmaps)
- 七、HyperLogLogs
- 八、地理位置(geospatial) 还在开发中
零、redis key
redis key是二进制安全的,所有的二进制序列都可以做为key值,空字符串也可以。
使用规则&建议:
(1)、key的长度不要太长,占内存,查找消耗大。
(2)、key的长度太短也不好,不利于阅读。
(3)、制定好key书写规范,约定好,利于开发,利于阅读。
(4)、key值设置要低于512MB。
一、字符串(Strings)
字符串结构是redis最简单的一种类型,Memcached缓存数据库也支持这一种(事实上Memcached是追崇极简设计哲学)。
使用SET GET 可以操作strings

tips:
a、SET 结构可以是任意值
b、不能超过512M
(1)、setnx
当前key存在时,设置不会成功,返回0
当前key不存在时,设置成功,返回1

这个命令可以构建分布式锁,而且redis官网并且给出了方案,而且方案很有借鉴性,关于基于redis setnx 构建分布式锁会单独研究。
http://www.redis.io/commands/setnx
http://redis.io/topics/distlock
(2)、当value是整数类型时,有一些专门的原子性的指令来操作这些数据

这个命令可以做一些统计性的工作,并且是原子性,多个客户端同时操作也是安全的。
incr、decr、incrby、decrby。其实这四个命令原理都一样,只不过换个样子罢了。
(3)、对key设置新的值,并且返回原先旧的值
(4)、MSET MGET 批量操作

mset key1,val1... 后面key和value对应好
mget key1,key2...参数为一个数组,返回值也是一个数组
(5)、EXISTS 是否存在某key,DEL 删除某key

初次操作是存在的,删除之后,在查询就不存在了。
(6)、TYPE 查看key对应的值的数据类型

(7)、expire TTL PERSIST
expire 生效时间,时间粒度可以单独设置
TTL 查看key剩余时间
PERSIST 把key设为永久

当我设置key之后,并且设置key5秒后失效。5秒内查看key时,是存在的,5秒后查询key,已经不存在了,已经失效了。

设置key60秒后失效,12秒过后查看key的时效。
二、列表(Lists)
redis的列表是基于链表实现的,这样添加数据和删除数据的时候速度非常迅速,但是基于下标索引查询数据的时候则会慢很多,如果有这样的需要使用sorted set。
(1)、使用LPUSH 可以在列表的左端插入数据,RPUSH可以在列表的右端插入数据, LRANGE可以从左端查询数据。
LPUSH key value [value ...] 从左端插入数据,可以同时插入多个数据
RPUSH key value [value ...] 从右端插入数据,可以同时插入多个数据
LRANGE key start stop 从左端开始插入数据,start是开始的坐标,stop是结束的坐标,都可以为负数。负数则代表反着方向。

---->[c][b][a] 从左边先进入的元素排在右端。
(2)、LPOP,RPOP,这两个指令,可以从list中取出数据,很有用处
LPOP key 从key中左端取出list的一个数据,并且返回
RPOP key 从key中右端取出list的一个数据,并且返回
可以直接理解为队列。
(3)、基于redis list push pop这几组命令,可以构建异步的生产者消费者系统。
生产者线程使用LPUSH把需要处理的数据插入队列中,消费者线程只要观察到队列中有数据,就可以取出数据就行处理。
关于基于redis list构建生产者消费者系统,也会另起篇幅进行研究。
(4)、也可以基于redis list构建分页系统。
存储数据之后,使用lrange 命令构建分页系统。
(5)、LTRIM 对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除。
LTRIM key start stop start 是开始下标 stop是结束下标
(6)、阻塞的list操作
BRPOP key [key ...] timeout 如果key对应的list中没有数据,则会一直阻塞。如果设置了超时时间,在超时时间前一直阻塞。
BLPOP 同理。
可以和push 结合着用,消费者阻塞式去数据。不建议使用。
三、哈希(Hashes)
hash顾名思义,就是键值对。
有四个最常用的命令
HSET key field value
HGET key field
HMSET key field value [field value ...]
HMGET key field [field ...]
一个key下面,有N个键值对,类似于一个hashmap,有多个key和value
hmset hmget 多个参数进行操作

strings 的一些纯粹的set get 操作,尽量转移到hash数据,内存低,效率高。
四、集合(Sets)
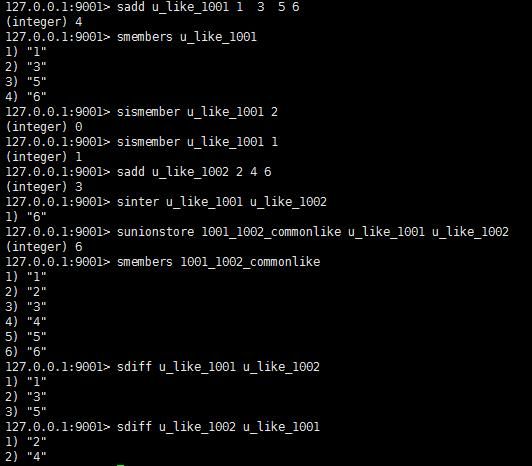
redis sets 是无序的集合,可以通过SADD 命令插入数据,主要提供了检查某个value是否存在该sets中,两个sets之间的交集,并集,差集,
基于这个特性可以用在一些关系相关的应用系统。比如微博中A和B共同关注的人等等。
(1)、SADD key member [member ...] 往key对应的sets添加元素,可以添加多个元素。
(2)、SMEMBERS key 查询key对应的sets中所有的元素
(3)、SISMEMBER key member 查询key对应的sets中是否拥有member这个元素
(4)、SPOP key [count] 随机从key对应的sets中取出一个元素,并且删除。后面[count]参数,3.0版本还不能用,以后的版本会支持。
(5)、SRANDMEMBER key [count] 随机从key对应的sets中取出一个元素,但是不删除。后面[count]参数,3.0版本还不能用,以后的版本会支持。
(6)、SINTER key [key ...] 从多个key对应的sets中取交集
(7)、SUNIONSTORE destination key [key ...] 从多个key对应的sets中取并集,并且赋予一个新的sets
(8)、SDIFF key [key ...] 取多个sets差集
五、有序集合(Sorted sets)
sorted sets 是sets 和hashs的混合,功能也比较强大。
关键在于我们在插入sorted sets集合时,可以对某个元素进行设置score,这就是为什么像hashs,就像键值对一样绑在一起。
sorted seds 是基于跳跃表和hash表,时间复杂度为O(log(N)) ,不过也是值得的,插入一个元素,就已经排好序了。这对于构建排序系统,非常有用,因为排序系统一旦排好序之后,变更频率较低,读取较多。
sorted sets 基于score的排序规则如下:
- 分数越大,排序靠前
- 分数相同,按照元素的strings的英文字母升序排列,那个元素的英文字母在前,那个元素就排在前。
(1)、ZADD key score member [score member ...] 往key对应的sorted sets 往添加元素,可以添加多个
(2)、ZRANGE key start stop [WITHSCORES] 根据下标索引,返回数据
(3)、ZREMRANGEBYSCORE key min max 从sorted sets 中删除元素根据min~max之间
(4)、ZRANK key member 返回某个元素在sorted sets中的排名
(5)、ZREVRANK key member 返回某个元素在sorted sets中的倒叙排名
六、位图(bitmaps)
效率最高的存储方式,精通之后,如有打通任督二脉。。。不扯了, http://www.cnblogs.com/riskyer/p/3228651.html
七、HyperLogLogs
http://www.cnblogs.com/ysuzhaixuefei/p/4052110.html