Hadoop中的I/O与传统I/O的区别:
1、传统I/O数据是集中存储的,在一台主机上,Hadoop I/O数据分布在多台主机上。
2、传统I/O数据量比较小,大多GB级,Hadoop I/O数据量经常PB级的
7.1 I/O操作的数据检查
通过校验和方式检查数据完整性,检验和不恩那个恢复数据,只能检测数据错误。
Hadoop采用CRC-32(检验和为32位)的方式检查数据完整性。
本地文件文件I/O的检查
当Hadoop创建一个文件,同时也会创建一个“文件名.src”的隐藏文件用来保存校验和。例如创建A文件同时也会创建一个A.src的文件用来保存校验和信息。每512byte Hadoop会生成一个32为的校验和(4byte)。这个值可以在
src/core/core-default.xml
文件中进行修改每个校验和所针对的文件大小
<property> <name>io.bytes.per.checksum</name> <value>512</value> <description>The number of bytes per checksum. Must not be larger than io.file.buffer.size.</description> </property>
校验和操作类为
org.apache.hadoop.fs.ChecksumFileSystem
继承结构如下,是FileSystem的子类
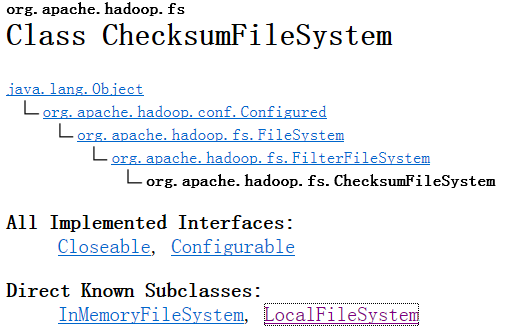
如果ChecksumFileSystem检测到错误会把源文件、校验和文件移到次级目录bad files中。
本地文件的数据完整性有客户端负责,Hadoop在存储和读取文件时进行校验和处理。
HDFS的I/O数据检查
HDFS会在三种情况下检查校验和
1)DataNode接受数据后存储数据前
DataNode一般在两种情况下接收数据:
用户从客户端上传数据
DataNode从其它DataNode上接收数据
2)客户端读取DataNode上的数据时
当客户端读取DataNode数据时,使用
org.apache.hadoop.hdfs.DFSClient
中的
/* FSInputChecker interface */
/* same interface as inputStream java.io.InputStream#read()
* used by DFSInputStream#read()
* This violates one rule when there is a checksum error:
* "Read should not modify user buffer before successful read"
* because it first reads the data to user buffer and then checks
* the checksum.
*/
@Override
public synchronized int read(byte[] buf, int off, int len)
throws IOException {
//for the first read, skip the extra bytes at the front.
if (lastChunkLen < 0 && startOffset > firstChunkOffset && len > 0) {
// Skip these bytes. But don't call this.skip()!
int toSkip = (int)(startOffset - firstChunkOffset);
if ( skipBuf == null ) {
skipBuf = new byte[bytesPerChecksum];
}
if ( super.read(skipBuf, 0, toSkip) != toSkip ) {
// should never happen
throw new IOException("Could not skip required number of bytes");
}
}
函数,现将数据读入到客户端的数据缓冲区中,然后在检查校验和。
3)DataNode后台守护进程的定期检测
DataNode的后台进程会定期的检查DataNode上的所有数据块
数据恢复策略
P123
7.2 数据的压缩
Hadoop提供的压缩格式
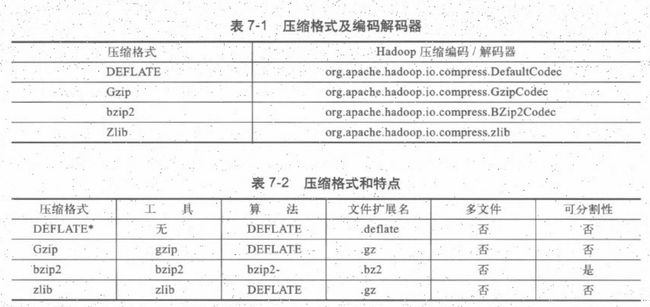
如果需要处理Gzip压缩后的5GB数据,Hadoop本应按64MB为一个数据块进行分割为80份,但Hadoop不会分割压缩后的数据。但如果是bzip2数据,因为它支持分割,所以压缩数据可以分割存储。
在MapReduce程序中使用压缩,设置Map处理后的压缩数据程序如下

7.3 数据的I/O中序列化操作
序列化:将对象转化为字节流的方式
反序列化:将字节流转换为对象的方式
Writable是Hadoop序列化的核心接口
public interface Writable {
/**
* Serialize the fields of this object to <code>out</code>.
*
* @param out <code>DataOuput</code> to serialize this object into.
* @throws IOException
*/
void write(DataOutput out) throws IOException;
/**
* Deserialize the fields of this object from <code>in</code>.
*
* <p>For efficiency, implementations should attempt to re-use storage in the
* existing object where possible.</p>
*
* @param in <code>DataInput</code> to deseriablize this object from.
* @throws IOException
*/
void readFields(DataInput in) throws IOException;
}
Hadoop的比较器
WritableComparator是WritableComparable的比较器,它是RawComparator针对WritableComparable的通用实现,RawComparator继承自Comparator。
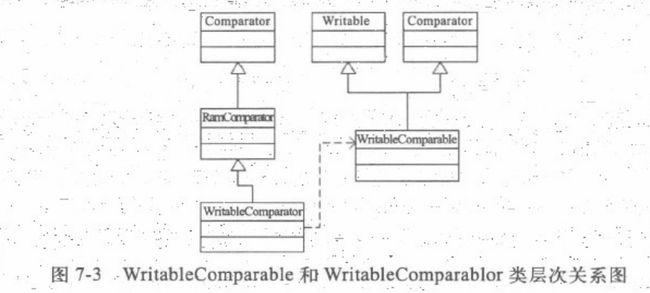
RawComparator中实现了对未反序列化数据的比较,这样可以不必创建对象,直接针对数据的字节流进行比较。
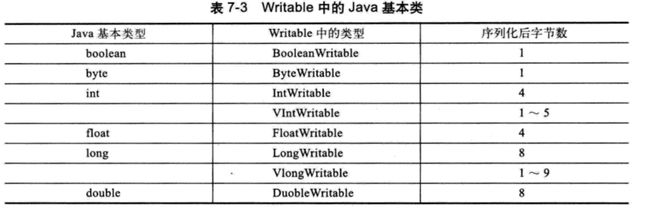
Writable类中的数据类型
7.4 对对MapReduce的文件类
P139 为完成