一、任务执行及通信的单元
Storm中关于任务执行及通信的三个概念:Worker(进程)、Executor(线程)和Task(Spout、Bolt)
1、 一个worker进程执行的是一个Topology的子集(不会出现一个worker进程为多个Topology服务),一个worker进程会启动一个或多个executor线程来执行一个topology的component(Spout或Bolt),因此,一个运行中的topology就是由集群中多台物理机上的多个worker进程组成的;
2、 Executor是一个被Worker进程启动的单独线程,每个executor只会运行一个topology的一个component(spout或bolt)的task(task可以是一个或多个,Storm默认是一个component只生成一个task,executor线程会在每次循环里顺序调用所有task实例);
3、 Task是最终运行spout或bolt中代码的单元(一个task即为spout或bolt的一个实例,executor线程在执行期间会调用该task的nextTuple或execute方法)topology启动后,一个component(spout或bolt)的task数目是固定不变的,但该component使用的executor线程可以动态调整(例如:一个executor线程可以执行该component的一个或多个task实例)这意味着,对于一个component存在这样的条件,threads<=tasks(即,线程数小于task数目)。默认情况下task的数目等于executor线程数目,即一个executor线程只运行一个task。
二、Storm内部通信机制简单介绍
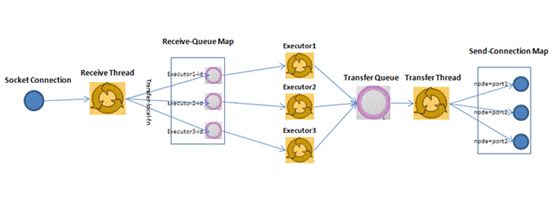
1、 同一worker间消息的发送使用的是LMAX Disruptor,它负责同一节点(同一进程内)上线程间的通信;
A、Disruptor使用了一个RingBuffer替代队列,用生产者消费者指针替代锁。
B、生产者消费者指针使用CPU支持的整数自增,无需加锁并且速度很快。Java的实现在Unsafe package中。
2、 不同worker间通信使用ZeroMQ(0.8)或Netty(0.9.0);
3、 不同topologey之间的通信,Storm不负责,我们需要自己想办法实现,例如使用kafka等;
Worker进程内部的结构图如下所示:
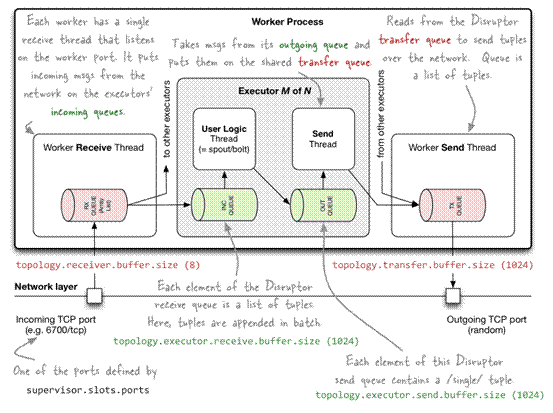
每一个worker进程都有一个单独的线程来监听该worker的端口号,并接收发送到该端口的数据,它将通过网络发送过来的数据放到worker的接收队列里面。
它监听的端口号是通过supervisor.slots.ports定义的。
接收队列的大小是通过topology.receiver.buffer.size定义的,默认值为8.
Disruptor在Storm中的应用如下图所示:
三、与通信相关的几个配置项介绍:
1、 supervisor.slots.ports:worker进程的接收线程的监听端口;
2、 topology.receiver.buffer.size:worker接收线程缓存消息的大小,它将该缓存消息发送给executor线程;需要为2的倍数
3、 topology.transfer.buffer.size:worker进程中向外发送消息的缓存大小;
4、 topology.executor.receive.buffer.size:executor线程的接收队列大小;需要为2的倍数
5、 topology.executor.send.buffer.size:executor线程的发送队列大小;需要为2的倍数
http://www.michael-noll.com/blog/2013/06/21/understanding-storm-internal-message-buffers/文章中作者给出的初始建议配置如下:
Try the following settings as a first start and see whether it improves the performance of your Storm topology
conf.put(Config.TOPOLOGY_RECEIVER_BUFFER_SIZE, 8);
conf.put(Config.TOPOLOGY_TRANSFER_BUFFER_SIZE, 32);
conf.put(Config.TOPOLOGY_EXECUTOR_RECEIVE_BUFFER_SIZE, 16384);
conf.put(Config.TOPOLOGY_EXECUTOR_SEND_BUFFER_SIZE, 16384);
转自:http://support.huawei.com/ecommunity/bbs/10242723.html