9.Spark之集群搭建4
6.运行Spark
6.1使用spark-submit
spark-submit命令位于${SPARK_HOME}/bin目录下,用于提交spark程序。
![]()
我们参照spark官网上的说明运行计算圆周率的程序,使用一下spark-sunbmit。
执行命令:./spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 10
我们截取了命令执行过程中的一部分关键日志信息如下图,其中说明了10个线程运行结束和最后得到的圆周率值:
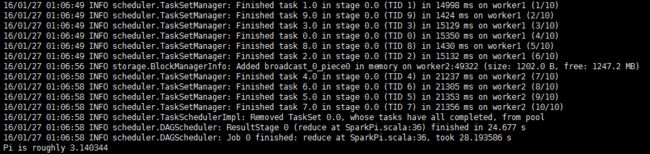
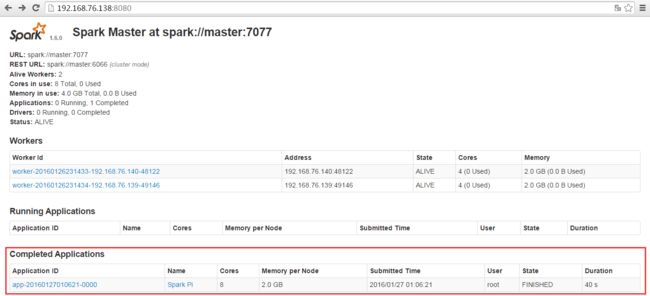
我们再次通过浏览器查看spark集群环境和运行的日志:

6.2使用spark-shell
spark-shell命令位于${SPARK_HOME}/bin目录下,用于提供交互式的命令行终端。
在${SPARK_HOME}/bin目录下执行命令:./spark-shell --master spark://master:7077

在spark-shell终端中使用exit命令来退出终端。
为了在该交互式命令行终端下测试一下,我们通过运行hadoop中常用的wordcount为例来说明。
命令:echo "Hello Spark, Hello World" >> wordcount.txt,创建一个测试文本文件;
命令:hdfs dfs -mkdir /input,在hdfs上创一个input目录;
命令:hdfs dfs -put ./wordcount.txt /input,将测试文本文件上传到hdfs的input目录下;
命令:hdfs dfs -ls /input,查看文本文件是否上传成功;
命令:hdfs dfs -cat /input/wordcount.txt,查看文本文件内容;
命令:hdfs dfs -mkdir /output,在hdfs上创一个output目录;
在spark-shell命令行终端执行命令:sc.textFile("/input/wordcount.txt").flatMap(_.split(" ")).map(word => (word, 1)).reduceByKey(_ + _).map(pair => (pair._2, pair._1)).sortByKey(false).map(pair => (pair._2, pair._1)).saveAsTextFile("/output/r1"),运行由scala语言编写的wordcount示例程序;
![]()
输入exit退出spark-shell命令行终端,执行命令:hdfs dfs -ls /output/r1

命令:hdfs dfs -cat /output/r1/part-00000、hdfs dfs -cat /output/r1/part-00001,查看运行后的结果

两个文件合并后的结果符合我们的文本文件内容。至此,我们了解了spark-shell的使用。