【MPI学习2】MPI并行程序设计模式:对等模式 & 主从模式
这里的内容主要是都志辉老师《高性能计算之并行编程技术——MPI并行程序设计》
书上有一些代码是FORTAN的,我在学习的过程中,将其都转换成C的代码,便于统一记录。
这章内容分为两个部分:MPI对等模式程序例子 & MPI主从模式程序例子
1. 对等模式MPI程序设计
1.1 问题背景
这部分以Jacobi迭代为具体问题,列举了三个求解Jacobi迭代问题的MPI对等模式程序。
这里需要阐明一下,书上的Jacobi迭代具体的背景可以参考这个内容:http://www.mcs.anl.gov/research/projects/mpi/tutorial/mpiexmpl/src/jacobi/C/main.html
简答说,就是矩阵每个元素都是其上下左右四个元素的平均值,矩阵四个边界的值不变。
这里学习的重点暂时放在如何完成上述矩阵的迭代的功能实现,不应该偏离过多去纠结Jacobi迭代,提高专注度。
1.2 第一版最原始的Jacobi迭代对等程序
代码如下:
1 #include "mpi.h" 2 #include <stdio.h> 3 #include <stdlib.h> 4 5 #define N 8 6 #define SIZE N/4 7 #define T 2 8 9 10 void print_myRows(int, float [][N]); 11 12 int main(int argc, char *argv[]) 13 { 14 float myRows[SIZE+2][N], myRows2[SIZE+2][N]; 15 int myid; 16 MPI_Status status; 17 18 MPI_Init(&argc, &argv); 19 MPI_Comm_rank(MPI_COMM_WORLD, &myid); 20 21 int i,j; 22 /*初始化*/ 23 for ( i = 0; i<SIZE+2; i++) 24 { 25 for ( j = 0; j<N; j++) 26 { 27 myRows[i][j] = myRows2[i][j] = 0; 28 } 29 } 30 if ( 0 == myid) { 31 for ( j = 0; j<N; j++) 32 myRows[1][j] = 8.0; 33 } 34 if (3 == myid) { 35 for ( j=0; j<N; j++) 36 myRows[SIZE][j] = 8.0; 37 } 38 for ( i = 1; i<SIZE+1; i++) 39 { 40 myRows[i][0] = 8.0; 41 myRows[i][N-1] = 8.0; 42 } 43 /*Jacobi Iteration部分*/ 44 int step; 45 for ( step = 0; step < T; step++ ) 46 { 47 // 传递数据 48 if (myid<3) { 49 // 从 下方 进程接收数据 50 MPI_Recv(&myRows[SIZE+1][0], N, MPI_FLOAT, myid+1, 0, MPI_COMM_WORLD, &status); 51 } 52 if (myid>0) { 53 // 向 上方 进程发送数据 54 MPI_Send(&myRows[1][0], N, MPI_FLOAT, myid-1, 0, MPI_COMM_WORLD); 55 } 56 if (myid<3) { 57 // 向 下方 进程发送数据 58 MPI_Send(&myRows[SIZE][0], N, MPI_FLOAT, myid+1, 0, MPI_COMM_WORLD); 59 } 60 if (myid>0) { 61 // 从 上方 进程接收数据 62 MPI_Recv(&myRows[0][0], N, MPI_FLOAT, myid-1, 0, MPI_COMM_WORLD, &status); 63 } 64 // 计算 65 int r_begin, r_end; 66 r_begin = (0==myid) ? 2 : 1; 67 r_end = (3==myid) ? SIZE-1 : SIZE; 68 for ( i = r_begin; i<=r_end; i++) 69 { 70 for ( j = 1; j<N-1; j++) 71 myRows2[i][j] = 0.25*(myRows[i][j-1]+myRows[i][j+1]+myRows[i-1][j]+myRows[i+1][j]); 72 } 73 // 更新 74 for ( i = r_begin; i<=r_end; i++) 75 { 76 for (j = 1; j<N-1; j++) 77 myRows[i][j] = myRows2[i][j]; 78 } 79 } 80 // MPI_Barrier(MPI_COMM_WORLD); 81 print_myRows(myid, myRows); 82 MPI_Finalize(); 83 } 84 85 void print_myRows(int myid, float myRows[][N]) 86 { 87 int i,j; 88 int buf[1]; 89 MPI_Status status; 90 buf[0] = 1; 91 if ( myid>0 ) { 92 MPI_Recv(buf, 1, MPI_INT, myid-1, 0, MPI_COMM_WORLD, &status); 93 } 94 printf("Result in process %d:\n", myid); 95 for ( i = 0; i<SIZE+2; i++) 96 { 97 for ( j = 0; j<N; j++) 98 printf("%1.3f\t", myRows[i][j]); 99 printf("\n"); 100 } 101 if ( myid<3 ) { 102 MPI_Send(buf, 1, MPI_INT, myid+1, 0, MPI_COMM_WORLD); 103 } 104 MPI_Barrier(MPI_COMM_WORLD); 105 }
代码执行结果:
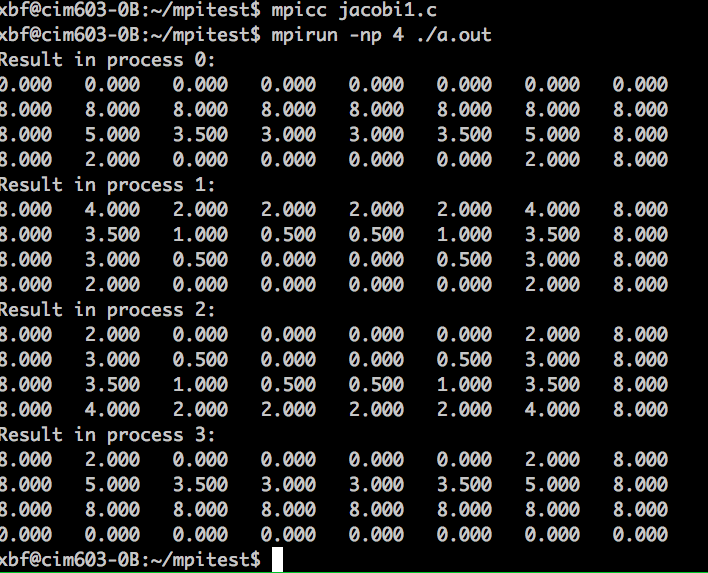
代码分析:
(1)矩阵分块方式
先说明一下,这与原书上的代码设计思路有差别:都老师的书上是把矩阵按columns划分的,我上面这份代码是将矩阵按照row分块的。
书上为什么要按照列进行矩阵分块呢?我觉得原因是FORTAN的二维数组是按照列来优先存储元素的,所以按列划分矩阵,对于后面的MPI_Send MPI_Recv操作都比较方便。
而我使用的是C语言来实现,C语言的二维数组是优先按照行来存储的,所以按照行来划分矩阵更划算,对于后面的MPI_Recv和MPI_Send操作更方便。
***关于矩阵分块的方式与矩阵乘法***
有关这个部分,我查阅了一本《高性能并行计算》的讲义:http://www.sccas.cn/yhfw/wdypx/wd/lszl/201112/W020111215333260773702.pdf
参阅了这本讲义的第3.1节内容,矩阵A×矩阵B并行计算的四种矩阵划分方式:行行、行列、列行、列列
这几种方法的核心就是:固定A或B,移动一个;或都固定,移动中间结果。
如果忘记了算法是如何移动数据的,通过画图的方式可以帮助理解:在每个时间片内,画出各个处理机有哪些数据,每个处理机内部进行了哪些运算。
另外,这些算法的效率比较主要考察“数据交换量”和“计算量”两个指标。
(2)代码设计逻辑
这个算法并不复杂,比较重要的是如何在对等模式下,各个进程要互相发送和接受数据。如何设计通信次序才能保证进程之间没有死锁出现呢?
关于这个问题,可以回顾一下都老师这本书上“7.7编写安全的MPI程序”。
我的理解就是:如果进程A和进程B需要互相发送和接收数据,画出进程之间交换数据的调用次序图,如果次序图中没有两个箭头是交叉的,那么就认为不会出现通信死锁。
上面这个程序,通信调用次序图如下:

可以看到,上述的通信调用次序图中,没有两个箭头是交叉的,所以是安全的。
同时,也可以看到上面的程序关于进程通信的部分跟计算部分是完全分开的:
通信部分只需要传递少量边界数据,计算部分充分利用各个处理器的并行计算优势。
1.3 捆绑发送接受的Jacobi迭代实现
代码实现:
1 #include "mpi.h" 2 #include <stdio.h> 3 #include <stdlib.h> 4 5 #define N 8 6 #define SIZE N/4 7 #define T 2 8 9 10 void print_myRows(int, float [][N]); 11 12 int main(int argc, char *argv[]) 13 { 14 float myRows[SIZE+2][N], myRows2[SIZE+2][N]; 15 int myid; 16 MPI_Status status; 17 18 MPI_Init(&argc, &argv); 19 MPI_Comm_rank(MPI_COMM_WORLD, &myid); 20 21 int i,j; 22 /*初始化*/ 23 for ( i = 0; i<SIZE+2; i++) 24 { 25 for ( j = 0; j<N; j++) 26 { 27 myRows[i][j] = myRows2[i][j] = 0; 28 } 29 } 30 if ( 0 == myid) { 31 for ( j = 0; j<N; j++) 32 myRows[1][j] = 8.0; 33 } 34 if (3 == myid) { 35 for ( j=0; j<N; j++) 36 myRows[SIZE][j] = 8.0; 37 } 38 for ( i = 1; i<SIZE+1; i++) 39 { 40 myRows[i][0] = 8.0; 41 myRows[i][N-1] = 8.0; 42 } 43 /*Jacobi Iteration部分*/ 44 int step; 45 for ( step = 0; step < T; step++ ) 46 { 47 // 从上往下平移数据 48 if ( 0 == myid) { 49 MPI_Send(&myRows[SIZE][0], N, MPI_FLOAT, myid+1, 0, MPI_COMM_WORLD); 50 } 51 else if (3 == myid) { 52 MPI_Recv(&myRows[0][0], N, MPI_FLOAT, myid-1, 0, MPI_COMM_WORLD, &status); 53 } 54 else { 55 MPI_Sendrecv(&myRows[SIZE][0], N, MPI_FLOAT, myid+1, 0, &myRows[0][0], N, MPI_FLOAT, myid-1, 0, MPI_COMM_WORLD, &status); 56 } 57 // 从下向上平移数据 58 if (3 == myid) { 59 MPI_Send(&myRows[1][0], N, MPI_FLOAT, myid-1, 0, MPI_COMM_WORLD); 60 } 61 else if (0 == myid) { 62 MPI_Recv(&myRows[SIZE+1][0], N, MPI_FLOAT, myid+1, 0, MPI_COMM_WORLD, &status); 63 } 64 else { 65 MPI_Sendrecv(&myRows[1][0], N, MPI_FLOAT, myid-1, 0, &myRows[SIZE+1][0], N, MPI_FLOAT, myid+1, 0, MPI_COMM_WORLD, &status); 66 } 67 // 计算 68 int r_begin, r_end; 69 r_begin = (0==myid) ? 2 : 1; 70 r_end = (3==myid) ? SIZE-1 : SIZE; 71 for ( i = r_begin; i<=r_end; i++) 72 { 73 for ( j = 1; j<N-1; j++) 74 myRows2[i][j] = 0.25*(myRows[i][j-1]+myRows[i][j+1]+myRows[i-1][j]+myRows[i+1][j]); 75 } 76 // 更新 77 for ( i = r_begin; i<=r_end; i++) 78 { 79 for (j = 1; j<N-1; j++) 80 myRows[i][j] = myRows2[i][j]; 81 } 82 } 83 MPI_Barrier(MPI_COMM_WORLD); 84 print_myRows(myid, myRows); 85 MPI_Finalize(); 86 } 87 88 void print_myRows(int myid, float myRows[][N]) 89 { 90 int i,j; 91 int buf[1]; 92 MPI_Status status; 93 buf[0] = 1; 94 if ( myid>0 ) { 95 MPI_Recv(buf, 1, MPI_INT, myid-1, 0, MPI_COMM_WORLD, &status); 96 } 97 printf("Result in process %d:\n", myid); 98 for ( i = 0; i<SIZE+2; i++) 99 { 100 for ( j = 0; j<N; j++) 101 printf("%1.3f\t", myRows[i][j]); 102 printf("\n"); 103 } 104 if ( myid<3 ) { 105 MPI_Send(buf, 1, MPI_INT, myid+1, 0, MPI_COMM_WORLD); 106 } 107 MPI_Barrier(MPI_COMM_WORLD); 108 }
代码分析:
如果一个进程既发送数据又接收数据,则可以使用MPI_Sendrecv函数来实现。
比如Jacobi迭代中的中间两个进程,都需要发送和接收。这样处理起来就可以用MPI_Sendrecv函数。
上述代码量并没有减少,但是设计逻辑稍微直观了一些。
1.4 引入虚拟进程的Jacobi迭代
代码实现:
1 #include "mpi.h" 2 #include <stdio.h> 3 #include <stdlib.h> 4 5 #define N 8 6 #define SIZE N/4 7 #define T 2 8 9 10 void print_myRows(int, float [][N]); 11 12 int main(int argc, char *argv[]) 13 { 14 float myRows[SIZE+2][N], myRows2[SIZE+2][N]; 15 int myid; 16 MPI_Status status; 17 18 MPI_Init(&argc, &argv); 19 MPI_Comm_rank(MPI_COMM_WORLD, &myid); 20 21 int i,j; 22 /*初始化*/ 23 for ( i = 0; i<SIZE+2; i++) 24 { 25 for ( j = 0; j<N; j++) 26 { 27 myRows[i][j] = myRows2[i][j] = 0; 28 } 29 } 30 if ( 0 == myid) { 31 for ( j = 0; j<N; j++) 32 myRows[1][j] = 8.0; 33 } 34 if (3 == myid) { 35 for ( j=0; j<N; j++) 36 myRows[SIZE][j] = 8.0; 37 } 38 for ( i = 1; i<SIZE+1; i++) 39 { 40 myRows[i][0] = 8.0; 41 myRows[i][N-1] = 8.0; 42 } 43 /*Jacobi Iteration部分*/ 44 int upid, downid; 45 upid = (0==myid) ? MPI_PROC_NULL : myid-1; 46 downid = (3==myid) ? MPI_PROC_NULL : myid+1; 47 int step; 48 for ( step = 0; step < T; step++ ) 49 { 50 /*从上向下平移数据*/ 51 MPI_Sendrecv(&myRows[SIZE][0], N, MPI_FLOAT, downid, 0, &myRows[0][0], N, MPI_FLOAT, upid, 0, MPI_COMM_WORLD, &status); 52 /*从下往上发送数据*/ 53 MPI_Sendrecv(&myRows[1][0], N, MPI_FLOAT, upid, 0, &myRows[SIZE+1][0], N, MPI_FLOAT, downid, 0, MPI_COMM_WORLD, &status); 54 // 计算 55 int r_begin, r_end; 56 r_begin = (0==myid) ? 2 : 1; 57 r_end = (3==myid) ? SIZE-1 : SIZE; 58 for ( i = r_begin; i<=r_end; i++) 59 { 60 for ( j = 1; j<N-1; j++) 61 myRows2[i][j] = 0.25*(myRows[i][j-1]+myRows[i][j+1]+myRows[i-1][j]+myRows[i+1][j]); 62 } 63 // 更新 64 for ( i = r_begin; i<=r_end; i++) 65 { 66 for (j = 1; j<N-1; j++) 67 myRows[i][j] = myRows2[i][j]; 68 } 69 } 70 MPI_Barrier(MPI_COMM_WORLD); 71 print_myRows(myid, myRows); 72 MPI_Finalize(); 73 } 74 75 void print_myRows(int myid, float myRows[][N]) 76 { 77 int i,j; 78 int buf[1]; 79 MPI_Status status; 80 buf[0] = 1; 81 if ( myid>0 ) { 82 MPI_Recv(buf, 1, MPI_INT, myid-1, 0, MPI_COMM_WORLD, &status); 83 } 84 printf("Result in process %d:\n", myid); 85 for ( i = 0; i<SIZE+2; i++) 86 { 87 for ( j = 0; j<N; j++) 88 printf("%1.3f\t", myRows[i][j]); 89 printf("\n"); 90 } 91 if ( myid<3 ) { 92 MPI_Send(buf, 1, MPI_INT, myid+1, 0, MPI_COMM_WORLD); 93 } 94 MPI_Barrier(MPI_COMM_WORLD); 95 }
代码分析:
Jacobi迭代的麻烦之处在于(按行划分矩阵):最上面的矩阵只需要与它下面的矩阵所在进程互相通信一次,最下面的矩阵只需要与它上面的矩阵所在进程互相通信一次,而中间的其余矩阵都需要与其上下相邻的矩阵所在进程通信两次。
因此,必须对最上面和最下面的矩阵特殊处理,作为一种corner case来对待,所以代码麻烦。
这里引入了MPI_PROC_NULL虚拟进程的概念,相当于给最上面的矩阵之上再来一个想象存在的进程:与这个虚拟进程通信不会真的通信,而是立刻返回。
这个虚拟进程的意义在于可以方便处理corner case,如上面的例子,无论是代码量和设计思路都简化了许多,MPI替我们完成了很多工作。
2. 主从模式MPI程序设计
2.1 矩阵A×向量B=向量C
主要通过矩阵A×向量B来讲解主从模式的程序设计,这个程序也是从FORTAN翻译成C代码的。
大体思路如下:
(1)一个master进程,负责总体调度,广播向量B到slaver进程,并把矩阵A的每一行发送到某个slaver进程
(2)slaver一开始从master的广播中获得向量B,之后每次从master获得矩阵A的某一行(具体的行号,利用MPI_TAG发送;但是为了要把0行空出来作为结束标志,所以从1开始),计算矩阵A的该行与向量B的内积后再回传给master进程
(3)master进程每次从一个slaver进程获得向量C的某个元素的值,master进程通过MPI_Recv中的status.MPI_TAG来判断该计算结果该更新到向量C的哪个位置中
(4)如果master进程从某个slaver回收计算结果后,没有新的计算任务要派送给slaver进程了,就向slaver进程发送一个MPI_TAG=0的消息;slaver收到MPI_TAG=0的消息,就结束退出
具体代码实现如下:
1 #include "mpi.h" 2 #include <stdio.h> 3 4 #define ROWS 100 5 #define COLS 100 6 #define min(x,y) ((x)>(y)?(y):(x)) 7 int main(int argc, char *argv[]) 8 { 9 int rows = 10, cols = 10; 10 int master = 0; 11 int myid, numprocs; 12 int i,j; 13 float a[ROWS][COLS], b[COLS], c[COLS]; 14 float row_result; 15 MPI_Status status; 16 17 MPI_Init(&argc, &argv); 18 MPI_Comm_rank(MPI_COMM_WORLD, &myid); 19 MPI_Comm_size(MPI_COMM_WORLD, &numprocs); 20 21 /*master进程*/ 22 if (master == myid) { 23 /*初始化矩阵a和b*/ 24 for (j=0; j<cols; j++) b[j]=1; 25 for (i=0; i<rows; i++) 26 { 27 for (j=0; j<cols; j++) 28 { 29 a[i][j] = i; 30 } 31 } 32 /*只在master进程中初始化b 其余slave进程通过被广播的形式获得向量b*/ 33 MPI_Bcast(&b[0], cols, MPI_FLOAT, master, MPI_COMM_WORLD); 34 /*向各个slave进程发送矩阵a的各行*/ 35 int numsent = 0; 36 for ( i=1; i<min(numprocs,rows+1); i++) 37 { 38 /* 每个slave进程计算一行×一列的结果 这里用MPI_TAG参数标示对应结果向量c的下标+1 39 * MPI_TAG在这里的开始取值范围是1 要把MPI_TAG空出来 作为结束slave进程的标志*/ 40 MPI_Send(&a[i-1][0], cols, MPI_FLOAT, i, ++numsent, MPI_COMM_WORLD); 41 } 42 /*master进程接受其他各进程的计算结果*/ 43 for ( i=0; i<rows; i++) 44 { 45 /*类似poll的方法 只要有某个slave进程算出来结果了 MPI_Recv就能返回执行一次*/ 46 MPI_Recv(&row_result, 1, MPI_FLOAT, MPI_ANY_SOURCE, MPI_ANY_TAG, MPI_COMM_WORLD, &status); 47 /*这里MPI_TAG的范围是1到rows 注意存储结果时下标减1*/ 48 c[status.MPI_TAG-1] = row_result; 49 /*发送矩阵a中没发送完的行 就用刚返回计算结果空出来的那个slave进程 通过status.MPI_SOURCE找到这个空出来的进程*/ 50 if (numsent < rows) { 51 MPI_Send(&a[numsent][0], cols, MPI_FLOAT, status.MPI_SOURCE, numsent+1, MPI_COMM_WORLD); 52 numsent = numsent + 1; 53 } 54 else { /*发送空消息 关闭slave进程*/ 55 float close = 1.0; 56 MPI_Send(&close, 1, MPI_FLOAT, status.MPI_SOURCE, 0, MPI_COMM_WORLD); 57 } 58 } 59 /*打印乘法结果*/ 60 for (j = 0; j < cols; j++ ) 61 printf("%1.3f\t", c[j]); 62 printf("\n"); 63 } 64 /*slave进程*/ 65 else { 66 MPI_Bcast(&b[0], cols, MPI_FLOAT, master, MPI_COMM_WORLD); 67 while(1) 68 { 69 row_result = 0; 70 MPI_Recv(&c[0], cols, MPI_FLOAT, master, MPI_ANY_TAG, MPI_COMM_WORLD, &status); 71 if ( 0 != status.MPI_TAG ) { 72 for ( j = 0; j < cols; j++ ) 73 { 74 row_result = row_result + b[j]*c[j]; 75 } 76 //printf("myid:%d, MPI_TAG:%d, c[0]:%f, row_result:%1.3f\n", myid, status.MPI_TAG,c[0], row_result); 77 MPI_Send(&row_result, 1, MPI_FLOAT, master, status.MPI_TAG, MPI_COMM_WORLD); 78 } 79 else { 80 break; 81 } 82 } 83 } 84 MPI_Finalize(); 85 }
代码执行结果:
这里有两个细节需要注意:
(1)关于++运算符在传递参数时的使用
代码40行一开始我写成了“MPI_Send(&a[numsent][0], cols, MPI_FLOAT, i, ++numsent, MPI_COMM_WORLD);”
显然,这个代码是错误的,问题的关键就出在了numsent这个变量上。
比如,在执行这个语句前numsent的值为1。我希望第一个参数传递的是&a[1][0],第四个参数是2,并且numsent此时的值为2。
这是一个思维陷阱,++numsent会导致numsent先加1,再作为值传递到MPI_Send实参中。所以,此时第一个参数变成了&a[2][0],并不是原先想要的。
为了避免这种思维陷阱,以后再设计传递函数的参数时,应该禁止在传递参数时使用++这个运算符;多写一个赋值语句不会怎样,反之用++运算符就容易掉进思维陷阱。
(2)关于#define带参宏定义的使用
代码中用到#define min(x,y) ((x)>(y)?(y):(x))这个宏定义,这个地方稍微吃了一点儿坑。
记住两个括号的原则:
a. 每个变量都要加括号
b. 宏定义整体要加括号
如果想看看宏定义是否替换问正确的内容了,可以cc -E选项来查看预处理后的结果。
2.2 master进程打印各个slaver进程发送来的消息
代码实现:
1 #include "mpi.h" 2 #include <stdio.h> 3 #include <string.h> 4 5 #define MSG_EXIT 1 6 #define MSG_ORDERED 2 7 #define MSG_UNORDERED 3 8 9 10 void master_io(); 11 void slaver_io(); 12 13 int main(int argc, char *argv[]) 14 { 15 int rank, size; 16 MPI_Init(&argc, &argv); 17 MPI_Comm_rank(MPI_COMM_WORLD, &rank); 18 if (0 == rank) { 19 master_io(); 20 } 21 else { 22 slaver_io(); 23 } 24 MPI_Finalize(); 25 } 26 27 void master_io() 28 { 29 int i,j,size,nslaver,firstmsg; 30 char buf[256], buf2[256]; 31 MPI_Status status; 32 MPI_Comm_size(MPI_COMM_WORLD, &size); 33 nslaver = size - 1; 34 while (nslaver>0) { 35 MPI_Recv(buf, 256, MPI_CHAR, MPI_ANY_SOURCE, MPI_ANY_TAG, MPI_COMM_WORLD, &status); 36 switch(status.MPI_TAG){ 37 case MSG_EXIT: 38 nslaver--; 39 break; 40 case MSG_UNORDERED: // 如果是乱序就直接输出 41 fputs(buf, stdout); 42 break; 43 case MSG_ORDERED: 44 firstmsg = status.MPI_SOURCE; 45 /* 这段程序设计的比较巧妙 46 * 虽然每个slaver发送两个message 不同slaver的message可能有重叠 47 * 但是每个每个slaver每次只能被接收一个message 48 * 这一轮一旦接收到message了 49 * 就不再从这个slaver接收消息了 50 * 概括说: 51 * 第一次进入MSG_ORDERED处理各个slaver第一次调用MPI_Send发送的消息 52 * 第二次进入MSG_ORDERED处理各个slaver第二次调用MPI_Send发送的消息*/ 53 for ( i=1; i<size; i++) 54 { 55 if (i==firstmsg) { 56 fputs(buf, stdout); 57 } 58 else { 59 MPI_Recv(buf2, 256, MPI_CHAR, i, MSG_ORDERED, MPI_COMM_WORLD, &status); 60 fputs(buf2, stdout); 61 } 62 } 63 break; 64 } 65 } 66 } 67 68 void slaver_io() 69 { 70 char buf[256]; 71 int rank; 72 MPI_Comm_rank(MPI_COMM_WORLD, &rank); 73 /*第一次向master进程发送有序消息*/ 74 sprintf(buf, "Hello from slaver %d, ordered print\n", rank); 75 MPI_Send(buf, strlen(buf)+1, MPI_CHAR, 0, MSG_ORDERED, MPI_COMM_WORLD); 76 /*第二次向master进程发送有序消息*/ 77 sprintf(buf, "Bye from slaver %d, ordered print\n", rank); 78 MPI_Send(buf, strlen(buf)+1, MPI_CHAR, 0, MSG_ORDERED, MPI_COMM_WORLD); 79 /*第一次向master发送无序消息*/ 80 sprintf(buf, "I'm exiting (%d), unordered print\n", rank); 81 MPI_Send(buf, strlen(buf)+1, MPI_CHAR, 0, MSG_UNORDERED, MPI_COMM_WORLD); 82 /*发送结束信息*/ 83 MPI_Send(buf, 0, MPI_CHAR, 0, MSG_EXIT, MPI_COMM_WORLD); 84 }
有一个不错的小巧的设计思路,在代码注释中具体说明了,这里不再赘述。
把这个例子看明白了,非常有利于理解master slaver的设计模式,并且知道如何花式保证每次master都能接受发送自slaver相同“批次”的消息。
小结:
看完了这章内容,对MPI程序设计稍微有些感觉了。另外,感觉前面撸了一遍APUE的帮助挺大的,虽然MPI程序接口比较简单,但是总让我想到APUE中的fork+IPC的部分。