SequoiaDB 系列之四 :架构简析
在本系列的第一篇中,简述了SequoiaDB的安装,以及一个(伪)集群的部署
第二篇和第三篇对SequoiaDB的集群,做了简单地操作。
在本篇中,将对SequoiaDB的架构进行简单的分析。
因为自身能力有限,对于架构这么高大上的主题,不敢轻言。因此本文会摘抄SequoiaDB官方的描述,加上自己的理解,达到共同学习的目的。
在解析之前,先简单叙述一下分布式系统的CAP理论:
C:代表一致性,即在某时刻,分布式系统中节点数据应该是相同的;
A:代表可用性,即有求必应,在分布式系统中某节点后,统一集群内的其它节点依然能处理远程的请求;
P:代表分区容忍性,即系统中某节点无法连接(故障)后,同属集群内的其它节点能继续提供服务。
由于某些原因,例如网络环境恶劣,灾备处理缺乏等,没有任何一个分布式产品全部实现了CAP。故目前的分布式系统,都是在C和A中做出选择。
如果考虑C,就必须对节点做多个备份,在写数据时,同步写其它备份节点,都完成才返回。大并发情况下,无法及时响应,导致不可用。
如果考虑A,就无法保证数据(真的)写入多个备份节点,而访问备节点的请求获取到的数据可能是过期的数据。
SequoiaDB中,在大规模分布式环境中提供了数据最终一致性的保障。并且提供方式,切合用户业务场景,使数据库系统既具备一定的安全性,又具备一定的可用性。
- 写操作只在某几个节点上执行后即返回,其它备节点后台定时向主节点同步,在此模式下,高可用性;
- 写操作在所有节点上执行后再返回,在此模式下,数据更安全,满足一致性。
用户可以权衡自己的应用场景,在创建Collection(集合)的时候,合理设置ReplSize的数值。
SequoiaDB的整体架构图如下:

数据库系统提供一组协调节点,供客户程序访问。可以理解成为数据库的代理。
既然是代理,因此协调节点仅保持客户端的连接,作为请求分发节点将用户请求分发至相应的数据节点,并不保存任何用户数据,。
在协调节点之后,有数据节点组和编目节点组。
编目节点保存系统的元数据信息,像该数据库有几个用户,有几个数据组,数据组中有哪些cs,又有哪些cl,以及创建cl时候的一些选项值等。协调节点通过与编目节点通讯从而了解数据在数据节点中的实际分布。一个或多个编目节点可组成复制组集群。
用户的数据保存在数据节点中。一个或多个数据节点可以构成一个数据节点组(官方称之为分区组,复制组)。数据节点组中每个数据节点都存储该复制组的一份完整数据,又称为复制组实例(或分区组实例);复制组中的数据节点之间采用最终一致性同步数据,不同的复制组中保存的数据无重复。
一个数据节点组,必须有一个主节点,来处理用户的写请求。在考虑更高可用性的场景下,用户的写操作,会先写在主节点上,然后通过同步机制,备节点可以从主节点获取到用户的操作和数据,对节点的数据进行更新和存储。而对于用户的读操作,可以从数据节点上的任何一个节点上得到处理。

其实在集群环境中,所有的读、写等请求,都是从协调(coord)节点分发下来的(当然,直连数据节点组中的节点的情况除外)。上图所描述的,是把协调节点省略掉了(不信?可以看看源码中的pmd模块和rtn模块)。
当集群中,主节点故障了,在集群节点中的通信机制发现之后,会发起选举,从备节点中选择新的主节点,继续接受和处理客户端的请求。关于选举部分,可以通过“二次选举”关键字搜索,维基百科上描述得比较详细 :)

选举是有条件的,在SequoiaDB中,选举的发起,必须是除故障节点外所有节点的数目,大于集群内所有节点数据的一半。可能我描述得不太准确,用公式说明吧。
假设一个集群内,所有节点数是 T(total),故障的节点数是D(Dump),选举的发起条件则是: true == (T-D) > T/2。当然,在正常情况下,集群中的主节点也会自发的在各个节点中进行切换,选择最佳的节点作为集群主节点。
当发现节点故障了,dba对故障进行了处理,并恢复了故障节点。这个时候,恢复的节点会在启动之后,充当从节点,从主节点中拉取数据,做到数据的备份。
图示如下:
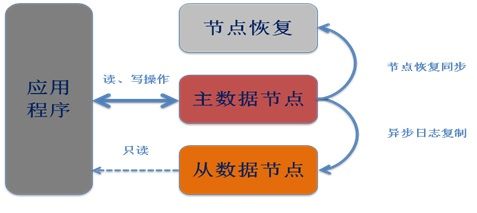
SequoiaDB整体架构基于上述机制,但是如何做到,就得慢慢分析其源码。更多简介,请去SequoiaDB官网信息中心获取。
唉,花了好久时间,感觉讲的还是不太清楚,而且只是业务上的架构,并没有涉及技术层面的架构。
在写完上一篇的高级功能之后,才发现居然没有把SequoiaDB的事务处理招牌写上去。
真是败笔啊。
我再找时间,去尝试一下SequoiaDB的事务功能是如何使用的。据说,MongoDB在目前的版本中,也没有提供事务的功能。看样子,其实国产软件,不一定输国外软件。
拙陋之处,敬请海涵。有讲述错误之处,请指出。感谢您能耐心看到这里。
下一篇,可能新写一篇关于SequoiaDB的事务功能的使用介绍,也可能是接着主题,开始分析SequoiaDB的源码部分。敬请关注。
PS:说到国产软件,不禁就会想起给自己和朋友配电脑时候,CPU,硬盘,内存,核心配件,居然都是国外的。龙芯火过一阵之后,也慢慢销匿。在软件产品方面,游戏引擎、数据库等软件,也大都出自国外。在NoSQL慢慢升温的情况下,杀出一个能和MongoDB这个行业老大竞争的SequoiaDB数据库,作为软件从业者,其实心里还是感到很自豪的。由衷希望国内会出现更多的牛逼软件产品,为我国人争光。
=====>THE END<=====