python学习笔记五(基础篇)
模块学习
模块,用一砣代码实现了某个功能的代码集合。
类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合。而对于一个复杂的功能来,可能需要多个函数才能完成(函数又可以在不同的.py文件中),n个 .py 文件组成的代码集合就称为模块。
模块分为三种:
- 自定义模块
- 内置标准模块(又称标准库)
- 开源模块
自定义模块:
#hello.py def hello(): print("hello world") if __name__ == "__main__": hello() import hello hello.hello()
模块导入
Python之所以应用越来越广泛,在一定程度上也依赖于其为程序员提供了大量的模块以供使用,如果想要使用模块,则需要导入。导入模块有一下几种方法:
1 import module 2 from module.xx.xx import xx 3 from module.xx.xx import xx as rename 4 from module.xx.xx import *
导入模块其实就是告诉Python解释器去解释那个py文件
- 导入一个py文件,解释器解释该py文件
- 导入一个包,解释器解释该包下的 __init__.py 文件
那么问题来了,导入模块时是根据那个路径作为基准来进行的呢?即:sys.path
import sys,pprint
pprint.pprint(sys.path)
['C:\\Users\\Administrator\\PycharmProjects\\S12\\test', 'C:\\Users\\Administrator\\PycharmProjects\\S12', 'C:\\Windows\\system32\\python34.zip', 'C:\\Python34\\DLLs', 'C:\\Python34\\lib', 'C:\\Python34', 'C:\\Python34\\lib\\site-packages']
自定义模块存放位置
可以修改python环境变量:
Unix 系统设置.bashrc
export PYTHONPATH=$PYTHONPATH:~/python
window中编辑autoexec.bat文件(在C盘的根目录下)增加一行配置:
set PYTHONPATH=%PYTHONPATH%;C:\python
还可以添加sys.path
base_dir = os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
sys.path.append(base_dir)
一、os模块
1 import os,sys 2 os.getcwd() #获取当前工作目录,即当前python脚本工作的目录路径 3 os.chdir("dirname") #改变当前脚本工作目录;相当于shell下cd 4 os.curdir #返回当前目录: ('.') 5 os.pardir #获取当前目录的父目录字符串名:('..') 6 os.makedirs('dirname1/dirname2') #可生成多层递归目录 7 os.removedirs('dirname1') #若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 8 os.mkdir('dirname') #生成单级目录;相当于shell中mkdir dirname 9 os.rmdir('dirname') #删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname 10 os.listdir('dirname') #列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 11 os.remove() #删除一个文件 12 os.rename("oldname","newname") #重命名文件/目录 13 os.stat('path/filename') #获取文件/目录信息 14 os.sep #输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/" 15 os.linesep #输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n" 16 os.pathsep #输出用于分割文件路径的字符串 17 os.name #输出字符串指示当前使用平台。win->'nt'; Linux->'posix' 18 os.system("bash command") #运行shell命令,直接显示 19 os.environ #获取系统环境变量 20 os.path.abspath(__file__) #返回path规范化的绝对路径 21 os.path.split(__file__) #将path分割成目录和文件名二元组返回 22 os.path.dirname(__file__) #返回path的目录。其实就是os.path.split(path)的第一个元素 23 os.path.basename(__file__) #返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 24 os.path.exists(__file__) #如果path存在,返回True;如果path不存在,返回False 25 os.path.isabs(__file__) #如果path是绝对路径,返回True 26 os.path.isfile(__file__) #如果path是一个存在的文件,返回True。否则返回False 27 os.path.isdir(__file__) #如果path是一个存在的目录,则返回True。否则返回False 28 #os.path.join(__file__[, path2[, ...]]) #将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 29 os.path.getatime(__file__) #返回path所指向的文件或者目录的最后存取时间 30 os.path.getmtime(__file__) #返回path所指向的文件或者目录的最后修改时间
二、sys模块
sys.argv #命令行参数List,第一个元素是程序本身路径 sys.exit("bye") #退出程序,正常退出时exit(0) sys.version #获取Python解释程序的版本信息 sys.maxint #最大的Int值 sys.path #返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform #返回操作系统平台名称 sys.stdout.write('please:') val = sys.stdin.readline()[:-1]
三、random模块
li = [23,52,12,4,7,18,33,99,25] print(random.random()) #随机小数 0.16377927048277297 print(random.uniform(1,10)) #返回随机实数n 其中1<=n<10 2.5185093102244163 print(random.randint(1,3)) #随机1-3 3 print(random.randrange(1,10)) #返回range(start,stop,step)中的随机数 9 print(random.choice(li)) #从序列seq中返回随机元素 52 random.shuffle(li) #原地指定序列seq print(li) [99, 12, 4, 52, 23, 18, 33, 7, 25] print(random.sample(li,5)) [33, 25, 99, 52, 12] #生成验证码 checkcode = '' for i in range(4): current = random.randrange(0,4) if current != i: temp = chr(random.randint(65,90)) else: temp = random.randint(0,9) checkcode += str(temp) print(checkcode)
四、time模块
时间相关的操作,时间有三种表示方式:
- 时间戳 1970年1月1日之后的秒,即:time.time()
- 格式化的字符串 2014-11-11 11:11, 即:time.strftime('%Y-%m-%d')
- 结构化时间 元组包含了:年、日、星期等... time.struct_time 即:time.localtime()
#_*_coding:utf-8_*_ import time import datetime print(time.clock()) #返回处理器时间,3.3开始已废弃 print(time.process_time()) #返回处理器时间,3.3开始已废弃
print(time.asctime()) #返回当前系统时间,将struct_time格式转为字符串格式 print(time.time()) #返回当前系统时间戳 print(time.ctime()) #输出Tue Jan 26 18:23:48 2016 ,当前系统时间 print(time.ctime(time.time()-86400)) #将时间戳转为字符串格式 print(time.gmtime(time.time()-86400)) #将时间戳转换成struct_time格式 print(time.localtime(time.time()-86400)) #将时间戳转换成struct_time格式,但返回 的本地时间 print(time.mktime(time.localtime())) #与time.localtime()功能相反,将struct_time格式转回成时间戳格式 #time.sleep(4) #sleep print(time.strftime("%Y-%m-%d %H:%M:%S",time.gmtime()) ) #将struct_time格式转成指定的字符串格式 print(time.strptime("2016-01-28","%Y-%m-%d") ) #将字符串格式转换成struct_time格式 #datetime module print(datetime.date.today()) #输出格式 2016-01-26 print(datetime.date.fromtimestamp(time.time()-864400)) #2016-01-16 将时间戳转成日期格式 current_time = datetime.datetime.now() # print(current_time) #输出2016-01-26 19:04:30.335935 print(current_time.timetuple()) #返回struct_time格式 #datetime.replace([year[, month[, day[, hour[, minute[, second[, microsecond[, tzinfo]]]]]]]]) print(current_time.replace(2014,9,12)) #输出2014-09-12 19:06:24.074900,返回当前时间,但指定的值将被替换 str_to_date = datetime.datetime.strptime("21/11/06 16:30", "%d/%m/%y %H:%M") #将字符串转换成日期格式 new_date = datetime.datetime.now() + datetime.timedelta(days=10) #比现在加10天 new_date = datetime.datetime.now() + datetime.timedelta(days=-10) #比现在减10天 new_date = datetime.datetime.now() + datetime.timedelta(hours=-10) #比现在减10小时 new_date = datetime.datetime.now() + datetime.timedelta(seconds=120) #比现在+120s print(new_date)
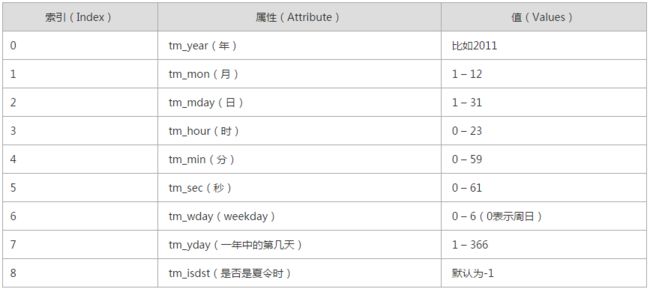
转换图如下:

re模块
匹配格式:
| 模式 |
描述 |
| ^ |
匹配字符串的开头 |
| $ |
匹配字符串的末尾。 |
| . |
匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| [...] |
用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k',所有特殊字符在字符集中都将失去原有的特殊含义,在字符集中如果要使用[,],^,-,可以在前面加上反斜杠。 |
| [^...] |
不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| * |
匹配0个或多个的表达式。 |
| + |
匹配1个或多个的表达式。 |
| ? |
匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| {n} |
精确匹配n前面表达式。 |
| {n,} |
精确匹配至少n个前面表达式。 |
| {n,m} |
匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a|b |
匹配a或b |
| (...) |
匹配括号内的表达式,也表示一个组,从表达式左边开始每遇到一个分组的左括号'(',编号+1,分组表达式作为一个整体,后面可以接数量词。表达式中的|仅在该组中有效。 |
| (?imx) |
正则表达式包含三种可选标志:i,m,或x。只影响括号中的区域。 |
| (?-imx) |
正则表达式关闭i,m,或x可选标志。只影响括号中的区域。 |
| (?:...) |
类似 (...), 但是不表示一个组用于使用“|”或后接数量词 |
| (?imx:re) |
在括号中使用i,m或x可选标志 |
| (?-imx:re) |
在括号中不使用i,m或x可选标志 |
| (?#...) |
#后的内容将被作为注释被忽略。 |
| (?<=...) |
后向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的左边。 |
| (?=...) |
前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
| (?!...) |
前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功 |
| (?>...) |
匹配的独立模式,省去回溯。 |
| \w |
匹配字母数字[a-zA-Z0-9] |
| \W |
匹配非字母数字[^A-Za-z0-9_] |
| \s |
匹配任意空白字符,等价于[\t\n\r\f]. |
| \S |
匹配任意非空字符[^ \f\n\r\t\v] |
| \d |
匹配任意数字,等价于[0-9]. |
| \D |
匹配任意非数字 |
| \A |
匹配字符串开始 |
| \Z |
匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。 |
| \z |
匹配字符串结束 |
| \G |
匹配最后匹配完成的位置。 |
| \b |
匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B |
匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \n,\t,等. |
匹配一个换行符。匹配一个制表符等 |
| \1...\9 |
匹配第n个分组的子表达式。 |
| \10 |
匹配第n个分组的子表达式,如果它经匹配。否则指的是八进制字符 码的表达式。 |
pattern = re.compile(r'hello') #创建一个'hello'的模式对象,compile也有search或者match函数 match = pattern.match('hello world') #只能匹配字符串开头 pattern = re.search('\d+','whar are you 2b?') if pattern: print(pattern.group()) pattern = re.compile(r'\d+') print(pattern.split('one1two2three3four4',maxsplit=4)) #最大分割次数 ['one', 'two', 'three', 'four', ''] print(pattern.findall('one1two2three3four4')) ['1', '2', '3', '4'] print(re.sub('\s*','','a b c d'))
'abcd'
rint(re.search('p(ython|erl)',s).group())
#可选项和重复子模式
print(re.search("([0-9]*)([a-z]*)([0-9]*)", a).group(0))
print(re.search("([0-9]*)([a-z]*)([0-9]*)", a).group(1))
print(re.search("([0-9]*)([a-z]*)([0-9]*)", a).group(2))
print(re.search("([0-9]*)([a-z]*)([0-9]*)", a).groups())
取email地址: name = '[email protected] http://gmail.com' pat = re.compile(r'[a-zA-Z0-9_.]+@[a-zA-Z0-9.]+') print(pat.search(name).group()) 手机号: ^1[3|4|5|8][0-9]\d{8}$
pickle 和 json模块
用于序列化的两个模块
- json,用于字符串 和 python数据类型间进行转换
- pickle,用于python特有的类型 和 python的数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
import json info = {'name':'koka','age':23} #json只能处理简单的字典和python数据类型 f = open('test.txt','w') json.dump(info,f) f.close() f = open('test.txt','r') account_info = json.load(f) f.close() print(account_info)
-------------
info = {
'1001':'haha','money':1200,
}
data = json.dumps(info)
f = open('log.txt','w')
f.write(data)
f.close()
f = open('log.txt','r')
account_info = json.loads(f.read())
print(account_info)
pickle模块提供了四个功能:dumps、dump、loads、load
import pickle
info = { '1001':{'haha','123',1200,1200}, '1002':{'hehe','123',1500,1500}, '1003':{'heihei','123',1800,1800}, '1004':{'hoho','123',2100,2100} } f = open('test.txt','wb') pickle.dump(info,f) f.close() f = open('test.txt','rb') account_info = pickle.load(f) f.close() print(account_info)
----------------
info = {
'1001':'haha','money':1200,
}
data = pickle.dumps(info)
f = open('log.txt','wb')
f.write(data)
f.close()
f = open('log.txt','rb')
account_info = pickle.loads(f.read())
print(account_info)