20135223何伟钦—家庭作业汇总
第二章家庭作业
(当时检查的时候已有同学选了这道题,重复不算,没有登记)
![]()





第三章家庭作业
(已到老师办公室检查)

3.54解析:
此题较为简单,只要对号入座,即可写出相应的C语言代码
int decode2(int x,int y,int z)
{
int r;
z-=y;
r=z;
r<<=15;
r>>=15;
return r*(z^x);
}
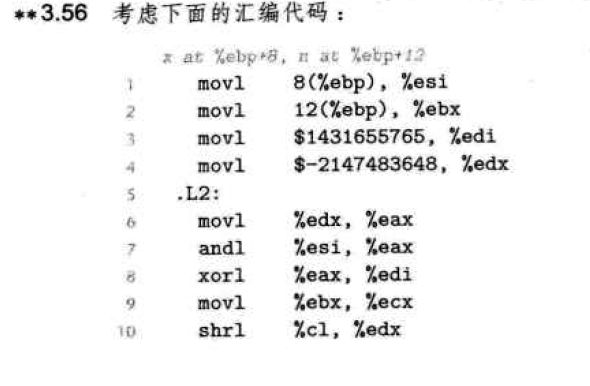


3.56解析:
(1)由C代码函数的定义可先猜测得%esi=x,%ebx=n;
由result、mask初始化以循环表达式的mask的使用可得%edi=result,%edx为mask,即是:
寄存器 变量
esi x
ebx n
edi result
edx mask
(2)
将十进制数$1431655765转化为十六进制数
result:0x55555555
将十进制数$-21474836648转化为十六进制数
mask:0x80000000
(3)
test %edx,%edx
jne .L2
可以得出循环条件表达式为
mask !=0
(4)
汇编代码第十行:(shrl %cl,%ecx)可以看出逻辑右移了n位
(5)
汇编代码第7行和第八行代码可得
result ^= (mask & x)
(6)
int loop(int x, int n)
{
int result = 0x55555555;//或者$1431655765
int mask;
for(mask = 1<<31; mask != 0; mask = ((unsigned)mask>>n)
{
result ^= (mask & x);
}
return result;
}

3.62解析:
(1)M的值:M = 76 / 4 = 19
(2)由cmpl = %edi,%ecx;
jl .L3;
意思是:比较%edi和%ecx的值,如果(%ecx-%edi)< 0 ,将继续进入L3循环;
根据题目所给代码的内循环条件表达式for(;j<i;)(即循环条件为(j-i)<0),可以确定%edi保存i,%ecx保存j.
(3)
int transpose(int M, int A[M][M])
{
int i,j;
for(i=0; i<M; ++i)
{
int *a = &A[i][0];
int *b = &A[0][i];
for(j=0; j<i; ++j)
{
int t = *a;
*a = *b;
*b = t;
++a;
b += M;
}
}
}
第六章家庭作业
(合作伙伴在博客园小组已登记)
一、家庭作业6.36(20135203&&20135223)
(由于题6.36与6.35基本题型一样,只是高速缓存的数据字节不一样,我直接把6.35题目修改后作为6.36题目)
考虑下面的矩阵转置函数:
typedef int array[4][4]; void transpose2(array dst,array src) { int i,j; for(i=0;i<4;i++) { for(j=0;j<4;j++) { dst[i][j]=src[j][i]; } } }假设这段代码运行在一台具有如下属性的机器上:
- sizeof(int)==4。
- 数组src从地址0开始,而数组dst从地址64开始(十进制)。
- 只有一个L1数据高速缓存,它是直接映射、直写、写分配的,块大小为16字节。
- 对于一个总大小为128数据字节的高速缓存,初始为空。
- 对src和dst数组的访问分别是读和写不命中的唯一来源。
对于每个row和col,指明对src[row][col]和dst[row][col]的访问是命中(h)还是不命中(m)。
分析:
(1)对于写分配的高速缓存,每次写不命中时,需要读取数据到高速缓存中。
该高速缓存只有 2 个组,src[0] src[2] 对应组 0,src[1] src[3] 对应组 1。
同理,dst[0] dst[2] 对应组 0,dst[1] dst[3] 对应组 1。
(2)缓存能完全容得下两个数组,所以只会出现冷不命中。
解答:
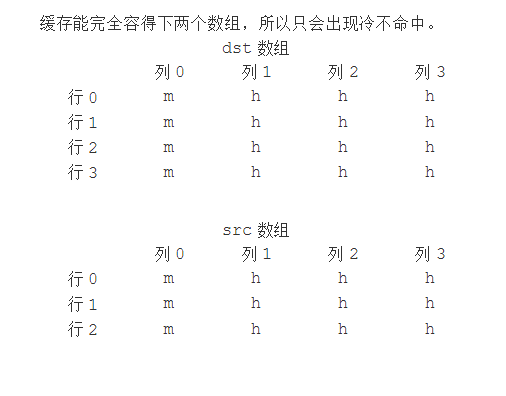
二、家庭作业6.46(20135223(2)&&20135215(2))

解答:
void transpose(int *dst,int *src,int dim)
{
int i,j;
int im,jm;
for(i=0;i<dim-3;i+=4)
{
im = i*dim;
for(j=0;j<dim-3;j+=4)
{
jm = j*dim;
dst[jm+i]=src[im+j];
dst[jm+i+1]=src[im+dim+j];
dst[jm+i+2]=src[im+2*dim+j];
dst[jm+i+3]=src[im+3*dim+j];
dst[jm+dim+i]=src[im+j+1];
dst[jm+dim+i+1]=src[im+dim+j+1];
dst[jm+dim+i+2] =src[im+2*dim+j+1];
dst[jm+dim+i+3]=src[im+3*dim+j+1];
dst[jm+2*dim+i]=src[im+j+2];
dst[jm+2*dim+i+1]=src[im+dim+j+2];
dst[jm+2*dim+i+2]=src[im+2*dim+j+2];
dst[jm+2*dim+i+3]=src[im+3*dim+j+2];
dst[jm+3*dim+i]=src[im+dim+j+3];
dst[jm+3*dim+i+1]=src[im+dim+j+3];
dst[jm+3*dim+i+2]=src[im+2*dim+j+3];
dst[jm+3*dim+i+3]=src[im+3*dim+j+3];
}
}
for(;i<dim;i++)
for(;j<dim;j++)
dst[j*dim+i]=src[i*dim+j];
}
用10000*10000的数组测试(linux下需要取消stack的大小限制才运行这么大的数组)
书上的程序平均需要 9.301s
优化后评价需要 3.830秒
第十章家庭作业
(博客园小组已登记)

分析与解答:
这里应该是表明,输入重定向到了foo.txt,然而3这个描述符是不存在的。
说明foo.txt并没有单独的描述符3。 所以Shell执行的代码应该是这样的:
代码截图:
