【sphinx】sphinx4学习笔记
- sphinx-core工程是个java工程,内带多个例子,其中涵多个功能,例如录音,对齐等。(还未挨个实验)
- spinx-test中两个demo,一个是helloworld,另一个是hellongram,就是语音识别。可以用到的参数文件有hellongram0.xml,hellongram9.xml,hellongram1.xml.其中helloworld.xml中没有用到语言模型,而是用JSFG来定义句子的语言规则,貌似是用正则表达式规定了待识别的句子只有如下可能:(hello)(jim|kate|tom)等。
- hellongram0.xml是用于ngram语言模型的例子,xml文件中定义了声学模型,语言模型,词典的存放路径。
- recognize开始,先load所有可用的模型,到如下阶段,load模型定义文件mdef,然后分别根据均值,方差,转换矩阵分配池子和大小。然后对每一个声元(senone)建立一个池子(distFloor:最低分数值,看起来是识别最低阈值,varianceFloor:最低方差值)
variancePool = loadDensityFile(dataLocation + "variances", varianceFloor); mixtureWeightsPool = loadMixtureWeights(dataLocation + "mixture_weights", mixtureWeightFloor); transitionsPool = loadTransitionMatrices(dataLocation + "transition_matrices"); transformMatrix = loadTransformMatrix(dataLocation + "feature_transform"); senonePool = createSenonePool(distFloor, varianceFloor);
- 目前问题:试用demo自带的wsj模型目录时候,加载成功可以运行。而读取我训练的模型时候,加载错误。debug问题发现两个模型之间有如下不同
================ wsg-0.xml模型格式: ------------------------------- senone:4147 numGausePerSenone:8 means:33176=4147*8 variances:33176 streams:1 ================= male_result(my)模型格式: ----------------------------------- senone:186 GaussianPerSenone:256 means:1024 varians:1024 streams:4
分析原因,是否针对sphinx4加载的模型,有些参数是固定的,比如streams的个数,以及Gauss个数
【解决】
修改sphinx-config训练参数文件中,将semi改为cont,应该注意到其后的备注,使用pocketsphinx时候,是用semi格式,用sphinx3时候有cont格式,则对应的stream是1,gause数目是8.以此,得到cont模型,加载到sphinx4环境中,编译,ok!运行顺利,使用自己的模型,然后用自己的声音测试,结果如下:
Start speaking. Press Ctrl-C to quit. resultList.size=1 bestFinalToken=0050 -6.8291255E06 0.0000000E00 -1.0008177E04 lt-WordNode </s>(*SIL ) p 0.0 -10008.177{[长城][</s>]} 50 </s> -10008.177 0.0 50 长城 68886.47 0.0 4 <sil> 0.0 0.0 0 <s> 0.0 0.0 0result=<s> <sil> 长城 </s> resultList.size=1 bestFinalToken=0050 -6.8291255E06 0.0000000E00 -1.0008177E04 lt-WordNode </s>(*SIL ) p 0.0 -10008.177{[长城][</s>]} 50 </s> -10008.177 0.0 50 长城 68886.47 0.0 4 <sil> 0.0 0.0 0 <s> 0.0 0.0 resultList.size=2 bestFinalToken=0077 -7.2286605E06 0.0000000E00 -1.0008177E04 lt-WordNode </s>(*SIL ) p 0.0 -10008.177{[长城][</s>]} 77 </s> -10008.177 0.0 59 长城 68886.47 0.0 4 <sil> 0.0 0.0 0 <s> 0.0 0.0 1result=<s> <sil> 长城 </s> resultList.size=2 bestFinalToken=0077 -7.2286605E06 0.0000000E00 -1.0008177E04 lt-WordNode </s>(*SIL ) p 0.0 -10008.177{[长城][</s>]} best token=0077 -7.2286605E06 0.0000000E00 -1.0008177E04 lt-WordNode </s>(*SIL ) p 0.0 -10008.177{[长城][</s>]} 77 </s> -10008.177 0.0 59 长城 68886.47 0.0 4 <sil> 0.0 0.0 0 <s> 0.0 0.0 You said: [长城] Start speaking. Press Ctrl-C to quit.
sphinx4代码解析
- @override,表示下面的方法是重写父类的方法
- @component 注解,是spring特有的,可以避免xml配置文件置入代码。加这个标签,可以由spring初始化时候自动扫描这些下面的类嵌入xml配置中,减少配置文件代码。提高效率。
- java处理语音的包 javax.sound.sampled介绍
javax.sound.sampled 提供用于捕获、处理和回放取样的音频数据的接口和类。 变量: protected AudioFormat AudioInputStream.format 流中包含的音频数据的格式。 方法: AudioFormat AudioFileFormat.getFormat() 获得音频文件中包含的音频数据的格式。 AudioFormat AudioInputStream.getFormat() 获得此音频输入流中声音数据的音频格式。 AudioFormat DataLine.getFormat() 获得数据行的音频数据的当前格式(编码、样本频率、信道数,等等)。 AudioFormat[] DataLine.Info.getFormats() 获得数据行支持的音频格式的集合。 static AudioFormat[] AudioSystem.getTargetFormats(AudioFormat.Encoding targetEncoding, AudioFormat sourceFormat) 使用已安装的格式转换器,获得具有特定编码的格式,以及系统可以从指定格式的流中获得的格式。
参考链接:
类 javax.sound.sampled.AudioFormat
的使用 http://www.766.com/doc/javax/sound/sampled/class-use/AudioFormat.html
利用纯java捕获和播放 音频 http://www.cnblogs.com/haore147/p/3662536.html
javax sound介绍 http://blog.csdn.net/kangojian/article/details/4449956
sphinx4-demo解析
- helloword
- hellongram
- transcriber
- sphinx4模型训练解析
一 模型训练需求点
1 Must train any kind (refers to tying) of model ---必须要能训练任何类型的模型 2 Variable number of states per model---每个模型要有多种状态数目 3 Mixtures with different numbers of Gaussians--多个数目的混合高斯 4 Different kinds of densities at different states--不同的状态要有不同的密度 5 Any kind of context ---- 任何上下文都能支持 6 Simultaneous training of multiple feature streams or models能同时训练多种特征类型的语音或者多种类型的模型
二 语言模型训练的关注点
【语言模型步骤】 Create a generic NGram language model interface--建立一个基本的nram模型界面 Create ARPA LM loader that can load language models in the ARPA format. This loader will not be optimized for efficiency, but for simplicity.-- Create a language model for the alphabet---建立一个导入arpa格式模型的模型导入接口,能保证方便导入 Incorporate use of the language model into the Linguist/Search---将语言模型和语言学部分,搜索部分结合 Test the natural spell with the LM to see what kind of improvement we get.---测试自然发音看看是否有提高 Create a more efficient version of the LM loader that can load very large language models--创建一个能加载更大模型的接口
三 声学模型格式
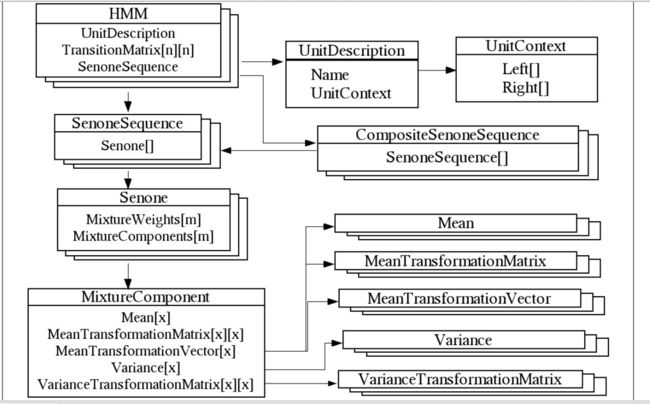
三 解码部分
(1)搜索方法:breadth first(横向优先搜索), viterbi decoding(维特比搜索),depth-first(深度优先),a* decoding
四 sphinx4使用向导
- sphinx4-5prealpha目录中,自带pom.xml文件,代表这个工程是一个maven工程。ecplise中加载:exist maven program。然后编译
- sphinx4自带三种识别方式:
-
LiveSpeechRecognizer 在线识别,工程中麦克分中获取语音,识别结果
-
StreamSpeechRecognizer 流文件识别,将识别语音从入口参数带入,识别出来结果
-
SpeechAligner 语音对齐,将语音和给出的文字做对应
- 以上三种,无论哪种模式,相同的需求是:声学模型,语言模型或者语法,词典,以及入口语音文件
-
- sphinx4自带一个基础工程接口,是transcriber,可以将语音中的内容识别成文字。称为转录。
public class TranscriberDemo { public static void main(String[] args) throws Exception { Configuration configuration = new Configuration(); configuration 设定声学模型,语言模型,词典的路径 .setAcousticModelPath("resource:/edu/cmu/sphinx/models/en-us/en-us"); configuration .setDictionaryPath("resource:/edu/cmu/sphinx/models/en-us/cmudict-en-us.dict"); configuration .setLanguageModelPath("resource:/edu/cmu/sphinx/models/en-us/en-us.lm.bin"); StreamSpeechRecognizer recognizer = new StreamSpeechRecognizer( configuration); InputStream stream = new FileInputStream(new File("test.wav"))) 识别参数中文件的内容 recognizer.startRecognition(stream); 开始识别 SpeechResult result; while ((result = recognizer.getResult()) != null) {得到结果 getResult System.out.format("Hypothesis: %s\n", result.getHypothesis()); } recognizer.stopRecognition();识别停止 } }
- 在线识别,是用在线识别类生成一个对象,然后获取麦克风中的语音
LiveSpeechRecognizer recognizer = new LiveSpeechRecognizer(configuration);
3. 流文件识别,是从流文件中读取对象做识别
StreamSpeechRecognizer recognizer = new StreamSpeechRecognizer(configuration);
注意读入的语音流的格式只能是
RIFF (little-endian) data, WAVE audio, Microsoft PCM, 16 bit, mono 16000 Hz 或者 RIFF (little-endian) data, WAVE audio, Microsoft PCM, 16 bit, mono 8000 Hz 如果是后者,还需要特意设置采样率 configuration.setSampleRate(8000);
4.sphinx4-api带四个demo,分别如下
Transcriber - demonstrates how to transcribe a file----转录语音,也就是语音识别为文字 Dialog - demonstrates how to lead dialog with a user对话系统 SpeakerID - speaker identification 说话人识别(who is he? Aligner - demonstration of audio to transcription timestamping 声音与文本对齐
5.
【参考】
一些影响性能的因素总结 http://www.codes51.com/article/detail_159118.html
cmu sphinx中一些问题的搜索讨论 http://sourceforge.net/p/cmusphinx/discussion/sphinx4/