数据结构笔记(郝斌主讲)(2015-11-26 22:12:54更新完毕)
教材-课外书籍推荐
高一凡(伪算法→真代码)
数据结构概述
定义
我们如何把现实生活中大量而复杂的问题以特定的数据类型和特定的存储结构保存到主存储器(内存)中,以及在此基础上为实现某个功能(比如查找某个元素,删除某个元素,对所有元素进行排序)而执行的相应操作,这个相应的操作也叫算法
数据结构 = 个体 + 个体的关系
算法 = 对存储数据的操作
算法
解题的方法和步骤
衡量算法的标准
1.时间复杂度
大概程序要执行的次数,而非执行的时间
2.空间复杂度
算法执行过程中大概所占用的最大内存
3.难易程度
4.健壮性
数据结构的地位
数据结构是软件中最核心的课程
程序 = 数据的存储 + 数据的操作 + 可以被计算机执行的语言
最后编辑于2015年8月18日23:10:06
预备知识
指针
指针的重要性:
指针是C语言的灵魂
定义
地址
地址就是内存单元的编号
从0开始的非负整数
范围: 0--FFFFFFFF(0——4G-1)
指针:
指针就是地址,地址就是指针
指针变量是存放内存单元地址的变量
指针的本质是一个操作受限的非负整数
分类:
1.基本类型的指针
2.指针和数组的关系
最后编辑于2015年8月19日23:06:51
结构体
为什么会出现结构体
为了表示一些复杂的数据,而普通的基本类型变量无法满足要求
什么叫结构体
结构体是用户根据实际需要自己定义的复合数据类型
如何使用结构体
两种方式
struct Student st = {1000, "zhangsan", 20};
struct Student * pst;
1.
st.sid
2.
pst->sid
pst所指向的结构体变量中的sid这个成员
注意事项
结构体变量不能加减乘除,但可以相互赋值
普通结构体变量和结构体指针变量作为函数传参的问题
跨函数使用内存---通过动态内存分配实现
一般情况下,自定义函数结束后内存释放,唯有动态分配的内存在没有遇见free函数的情况下,自定义函数结束了,但内存仍然存在。
最后编辑于2015年8月20日23:00:44
模块一:线性结构[把所有的结点用一根直线穿起来]
连续存储[数组]
1. 什么叫数组
元素类型相同,大小相同
2. 数组的优缺点
离散存储[链表]
定义:
n个结点离散分配
彼此通过指针相连
每个节点只有一个前驱节点,每个节点只有一个后续节点
首节点没有前驱结点,尾节点没有后续节点
专业术语:
首节点:
第一个有效节点
尾节点:
最后一个有效节点
头结点:
头结点是数据类型和首结点类型一样
第一个有效节点之前的那个节点
头结点并不存放有效数据
加头结点的目的主要是为了方便对链表的操作
头指针:
指向头结点的指针变量
尾指针:
指向尾节点的指针变量
如果希望通过一个函数对链表进行处理,我们至少需要接受链表的哪些信息:
只需要一个参数:头指针
因为我们通过头指针可以推算出链表的其他所有信息
分类:
单链表
双链表:
每一个节点有两个指针域
循环链表
能通过任何一个节点找到其他所有的结点
非循环链表
算法:
遍历
查找
清空
销毁
求长度
排序
删除节点
插入节点
算法:
狭义的算法是与数据的存储方式密切相关
广义的算法是与数据的存储方式无关
泛型:
利用某种技术达到的效果就是:不同的存储方式,执行的操作是一样的
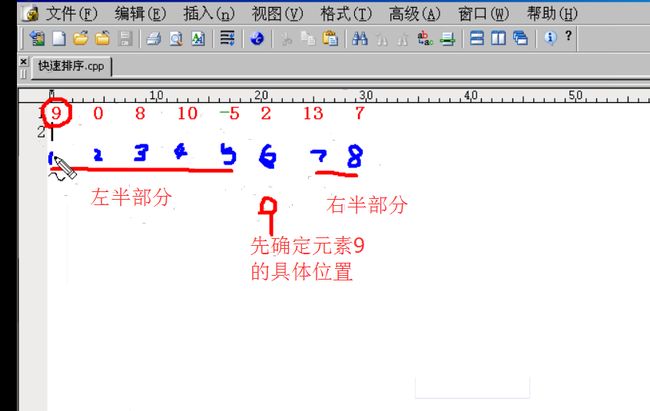
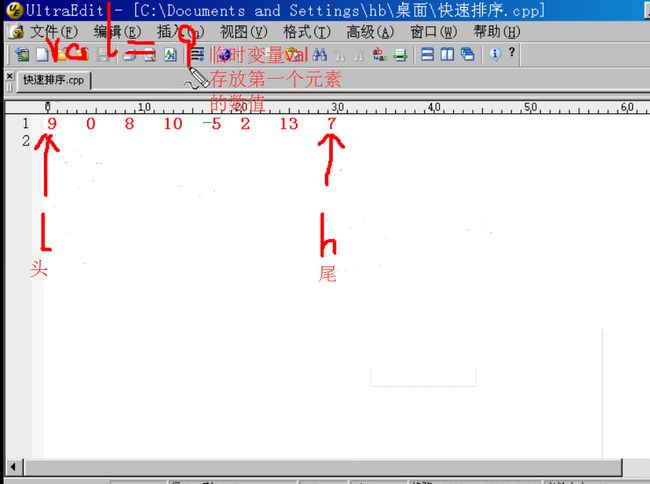
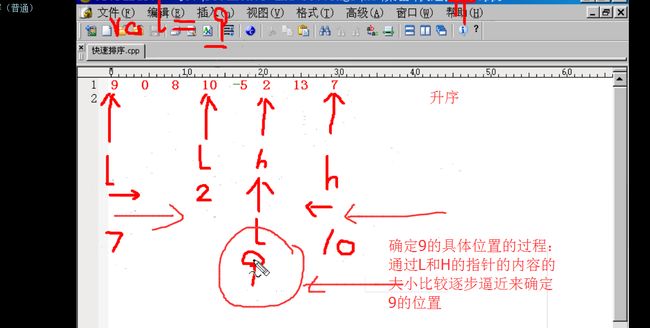
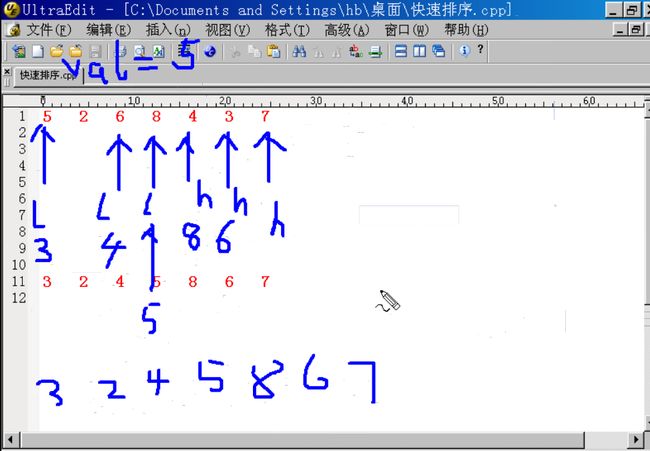
链表排序算法
1 for(i=0,p=pHead->pNext; i<len-1; ++i,p=p->pNext) 2 { 3 for(j=i+1,q=p->pNext; j<len; ++j,q=q->pNext) 4 { 5 if(p->data > q->data)//类似于数组中的 a[i] > a[j]
6 { 7 t = p->data;//类似于数组中的:t = a[i];
8 p->data = q->data;//类似于数组中的:a[i] = a[j];
9 q->data = t;//类似于数组中的 a[j] = t;
10 } 11 } 12 }


再论数据结构
狭义:
数据结构是专门研究数据存储的问题
数据的存储包含两方面:个体的存储 + 个体关系的存储
广义:
数据结构既包含数据的存储也包含数据的操作
对存储数据的操作就是算法
算法:
狭义
算法是和数据的存储方式密切相关
广义
算法和数据的存储方式无关
这就是泛型思想
数据的存储结构有几种
线性
连续存储【数组】
优点
存储速度很快
缺点
事先必须知道数组的长度
插入删除元素很慢
空间通常是有限制的
需要大块连续的内存块
插入删除的效率极低
离散存储【链表】
优点
空间没有限制
插入删除元素很快
缺点
存取速度很慢
线性结构的应用--栈
线性结构的应用--队列
非线性
树
图
链表的优缺点:
线性结构的两种常见应用之一 栈
定义
一种可以实现“先进后出”的存储结构
栈类似于箱子
分类
静态栈
动态栈
算法
出栈
压栈
应用
线性结构的两种常见应用之二 队列
定义:
一种可以实现“先进先出”的存储结构
分类:
链式队列 -- 用链表实现
静态队列 -- 用数组实现
静态队列通常都必须是循环队列
循环队列的讲解:
1.静态队列为什么必须是循环队列吧
2.循环队列需要几个参数来确定
需要2个参数来确定
front
rear
3.循环队列各个参数的含义
2个参数不同场合有不同的含义
建议初学者先记住,然后慢慢体会
1).队列初始化
font和rear的值都是零
2).队列非空
font代表的是队列的第一个元素
rear代表的是队列的有效元素的最后一个有效元素的下一个元素
3).队列空
font和rear的值相等,但不一定是零
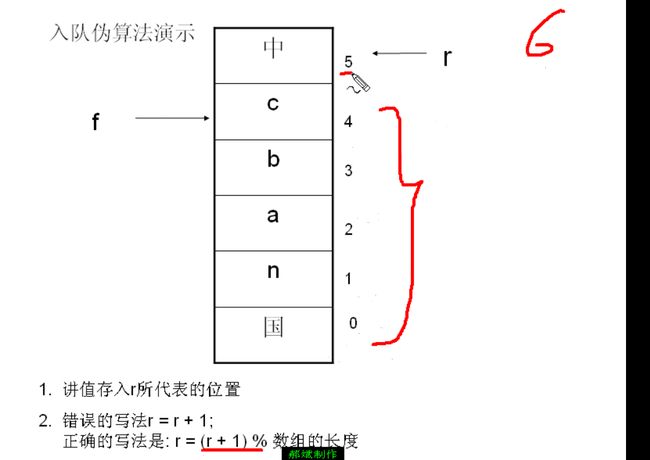
4.循环队列入队伪算法讲解
两步完成:
1.将值存入r所代表的位置
2.错误的写法rear = rear + 1;
正确的写法是:rear = (rear + 1) % 数组的长度
5.循环队列出队伪算法讲解
front = (front+1) % 数组的长度
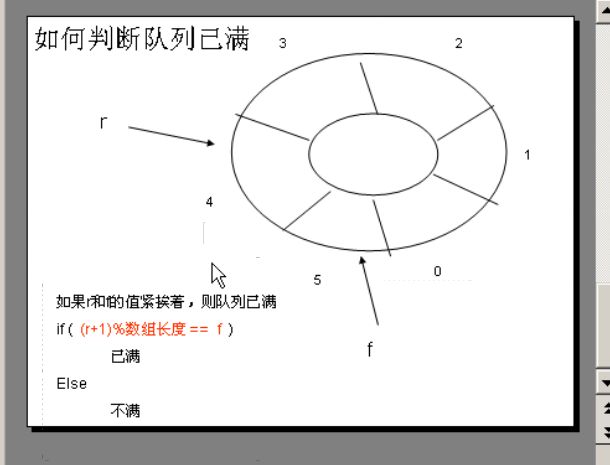
6.如何判断循环队列是否为空
如果front与rear的值相等,
则该队列就一定为空
7.如何判断循环队列是否已满
递归的应用:
树和森林就是以递归的方式定义的
树和图的很多算法都是以递归来实现的
很多数学公式就是以递归的方式定义的
斐波那契序列
1 2 3 5 8 13 21 34
逻辑结构
线性
数组
链表
栈和队列是一种特殊的线性结构
非线性
树
图
物理结构
模块二:非线性结构
树
树定义
专业定义:
1.有且只有一个称为根的节点
2.有若干个互不相交的子树,这些子树本身也是一棵树
通俗的定义:
1.树是由节点和边组成
2.每个节点只有一个父节点但可以有多个子节点
3.但有一个节点例外,该节点没有父节点,此节点称为根节点
专业术语
节点 父节点 子节点
子孙 堂兄弟
深度:
从根节点到最底层节点的层数称之为深度
根节点是第一层
叶子节点:
没有子节点的节点
非终端节点
实际就是非叶子节点
度
子节点的个数称为度
树分类
一般树
任意一个节点的子节点的个数都不受限制
二叉树
任意一个节点的子节点个数最多两个,且子节点的位置不可更改
分类:
一般二叉树
满二叉树
在不增加树的层数的前提下,无法再多添加一个节点的二叉树就是满二叉树
完全二叉树
如果只是删除了满二叉树最底层最右边的连续若干个节点,这样形成的二叉树就是完全二叉树
森林
n个互不相交的树的集合
树的存储
二叉树的存储
连续存储[完全二叉树]
优点:
查找某个节点的父节点和子节点(也包括判断有没有子节点)速度很快
缺点:
耗用内存空间过大
链式存储
一般树的存储
双亲表示法
求父节点方便
孩子表示法
求子节点方便
双亲孩子表示法
求父节点和子节点都很方便
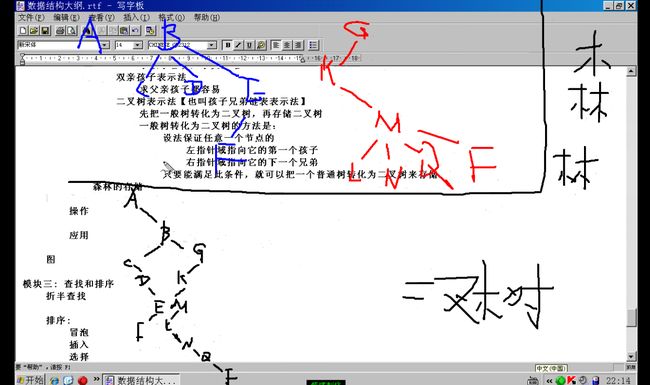
二叉树表示法
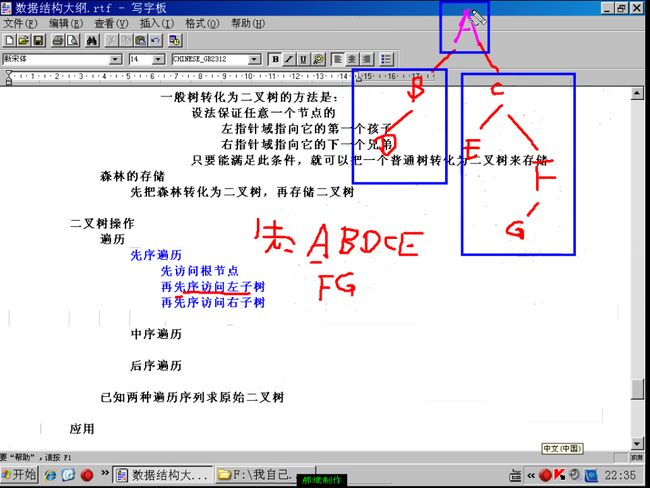
把一个普通树转化成二叉树来存储
具体转换方法:
设法保证任意一个节点的
左指针域指向它的第一个孩子
右指针域指向它的兄弟
只要能满足此条件,就可以把一个普通树转化为二叉树
一个普通树转化成的二叉树一定没有右子树
森林的存储
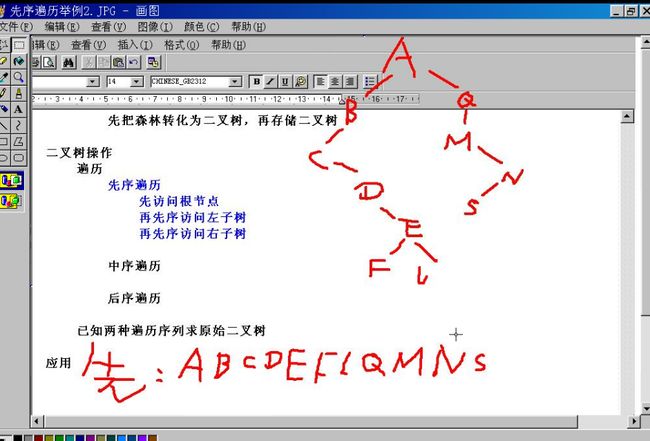
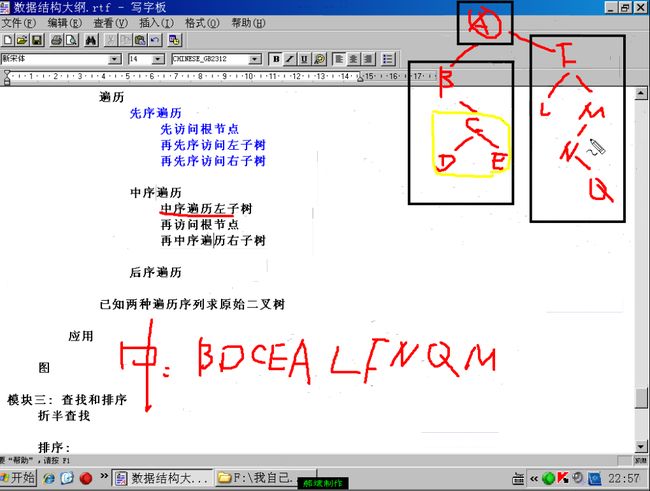
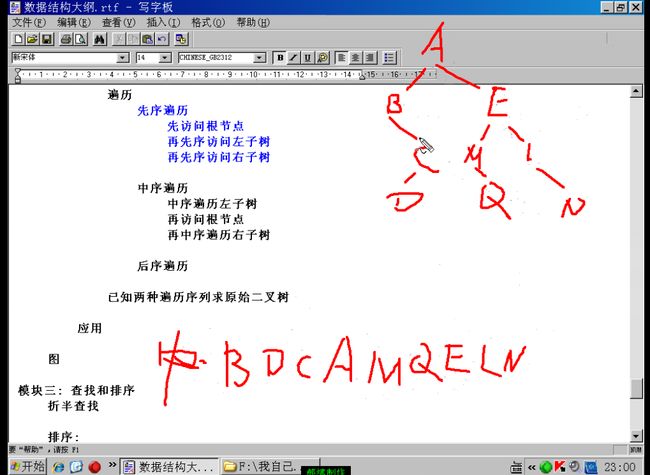
先把森林转化为二叉树,再存储二叉树


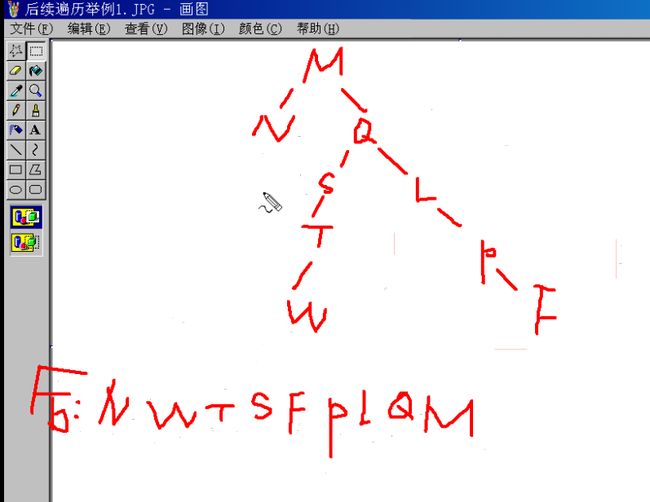
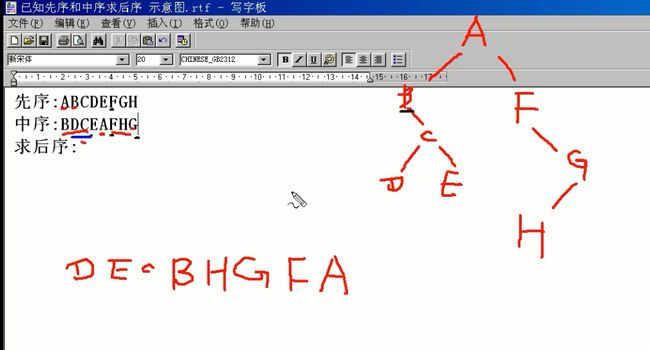
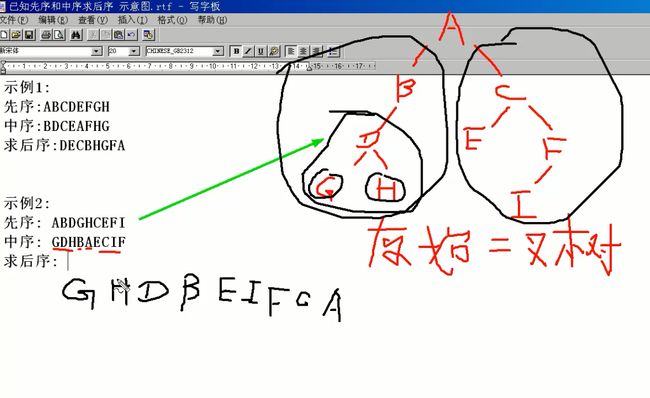
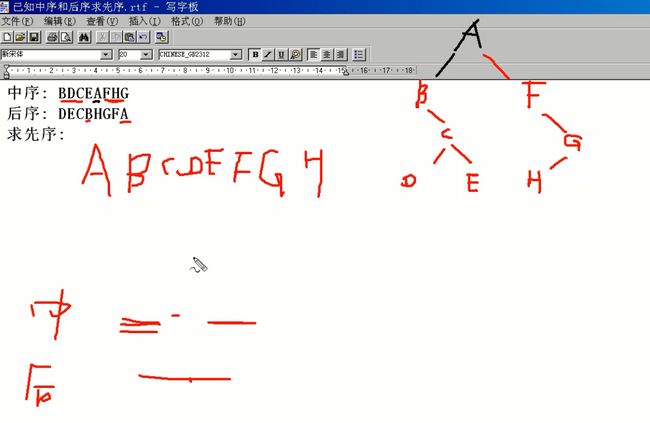
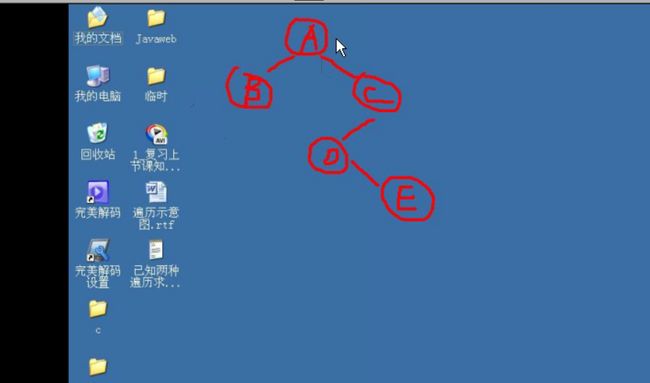
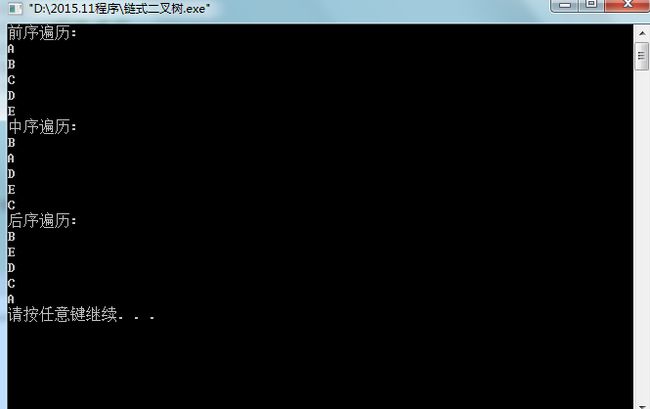
1 #include<stdio.h> 2 #include<malloc.h> 3 4 struct BTNode 5 { 6 char data; 7 struct BTNode * pLchild; //p是指针,L是左, child是孩子 8 struct BTNode *pRchild; 9 }; 10 11 struct BTNode * CreateBTree(); 12 void PreTraverseBTree(struct BTNode * pT); 13 void InTraverseBTree(struct BTNode * pT); 14 void PostTraverseBTree(struct BTNode * pT); 15 16 int main(void) 17 { 18 struct BTNode * pT = CreateBTree(); 19 20 printf("前序遍历:\n"); 21 PreTraverseBTree(pT);//前序遍历 22 printf("中序遍历:\n"); 23 InTraverseBTree(pT);//中序遍历 24 printf("后序遍历:\n"); 25 PostTraverseBTree(pT);//后序遍历 26 27 return 0; 28 } 29 30 void PostTraverseBTree(struct BTNode * pT) 31 { 32 if(pT != NULL) 33 { 34 35 if(pT->pLchild != NULL) 36 { 37 PostTraverseBTree(pT->pLchild); 38 } 39 40 if(pT->pRchild != NULL) 41 { 42 PostTraverseBTree(pT->pRchild); 43 } 44 45 printf("%c\n",pT->data); 46 47 //pT->pLchild可以代表整个左子树 48 } 49 50 51 /* 52 ·伪算法 53 先访问根节点 54 再先序访问左子树(先序即前序?); 55 再先序访问右子树 56 */ 57 } 58 59 60 void InTraverseBTree(struct BTNode * pT) 61 { 62 if(pT != NULL) 63 { 64 65 if(pT->pLchild != NULL) 66 { 67 InTraverseBTree(pT->pLchild); 68 } 69 70 printf("%c\n",pT->data); 71 72 if(pT->pRchild != NULL) 73 { 74 InTraverseBTree(pT->pRchild); 75 } 76 77 //pT->pLchild可以代表整个左子树 78 } 79 80 81 /* 82 ·伪算法 83 先访问根节点 84 再先序访问左子树(先序即前序?); 85 再先序访问右子树 86 */ 87 } 88 89 90 void PreTraverseBTree(struct BTNode * pT) 91 { 92 if(pT != NULL) 93 { 94 printf("%c\n",pT->data); 95 if(pT->pLchild != NULL) 96 { 97 PreTraverseBTree(pT->pLchild); 98 } 99 if(pT->pRchild != NULL) 100 { 101 PreTraverseBTree(pT->pRchild); 102 } 103 104 //pT->pLchild可以代表整个左子树 105 } 106 107 108 /* 109 ·伪算法 110 先访问根节点 111 再先序访问左子树(先序即前序?); 112 再先序访问右子树 113 */ 114 } 115 116 struct BTNode * CreateBTree()//功能弱,只是静态的 117 { 118 struct BTNode * pA = (struct BTNode *)malloc(sizeof(struct BTNode)); 119 struct BTNode * pB = (struct BTNode *)malloc(sizeof(struct BTNode)); 120 struct BTNode * pC = (struct BTNode *)malloc(sizeof(struct BTNode)); 121 struct BTNode * pD = (struct BTNode *)malloc(sizeof(struct BTNode)); 122 struct BTNode * pE = (struct BTNode *)malloc(sizeof(struct BTNode)); 123 124 pA->data = 'A'; 125 pB->data = 'B'; 126 pC->data = 'C'; 127 pD->data = 'D'; 128 pE->data = 'E'; 129 130 pA->pLchild = pB; 131 pA->pRchild = pC; 132 pB->pLchild = pB->pRchild = NULL; 133 pC->pLchild = pD; 134 pC->pRchild = NULL; 135 pD->pLchild = NULL; 136 pD->pRchild = pE; 137 pE->pLchild = pE->pRchild = NULL; 138 139 return pA; 140 } 141