连接Oracle与Hadoop(2) 使用OLH加载Hive表到Oracle
OLH是Oracle Loader for Hadoop的缩写,Oracle的大数据连接器(BDC)的一个组件,可将多种数据格式从HDFS上加载到Oracle数据库库中。
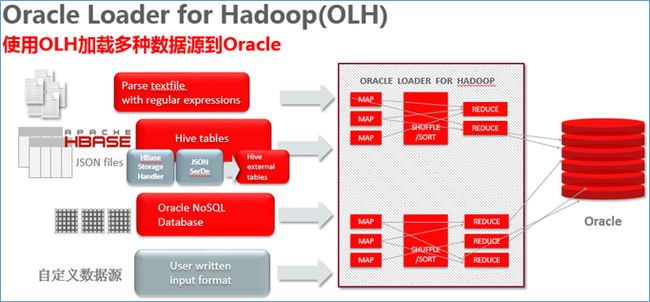
本文在同一台服务器上模拟oracle数据库与hadoop集群,实验目标:使用OLH从Hadoop端的Hive表加载数据到Oracle表中。
Oracle端:
| 服务器 |
系统用户 |
安装软件 |
软件安装路径 |
| Server1 |
oracle |
Oracle Database 12.1.0.2 |
/u01/app/oracle/product/12.1.0/dbhome_1 |
Hadoop集群端:
| 服务器 |
系统用户 |
安装软件 |
软件安装路径 |
| Server1 |
hadoop |
Hadoop 2.6.2 |
/home/hadoop/hadoop-2.6.2 |
| Hive 1.1.1 |
/home/hadoop/hive-1.1.1 |
||
| Hbase 1.1.2 |
/home/hadoop/hbase-1.1.2 |
||
| jdk1.8.0_65 |
/home/hadoop/jdk1.8.0_65 |
||
| OLH 3.5.0 |
/home/hadoop/oraloader-3.5.0-h2 |
- 部署Hadoop/Hive/Hbase/OLH软件
将Hadoop/Hive/Hbase/OLH软件解压到相应目录
-
[hadoop@server1 ~]$ tree -L 1
-
├── hadoop-2.6.2
-
├── hbase-1.1.2
-
├── hive-1.1.1
-
├── jdk1.8.0_65
-
├── oraloader-3.5.0-h2
- 配置Hadoop/Hive/Hbase/OLH环境变量
-
export JAVA_HOME=/home/hadoop/jdk1.8.0_65
-
-
export HADOOP_USER_NAME=hadoop
-
export HADOOP_YARN_USER=hadoop
-
export HADOOP_HOME=/home/hadoop/hadoop-2.6.2
-
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
-
export HADOOP_LOG_DIR=${HADOOP_HOME}/logs
-
export HADOOP_LIBEXEC_DIR=${HADOOP_HOME}/libexec
-
export HADOOP_COMMON_HOME=${HADOOP_HOME}
-
export HADOOP_HDFS_HOME=${HADOOP_HOME}
-
export HADOOP_MAPRED_HOME=${HADOOP_HOME}
-
export HADOOP_YARN_HOME=${HADOOP_HOME}
-
export HDFS_CONF_DIR=${HADOOP_HOME}/etc/hadoop
-
export YARN_CONF_DIR=${HADOOP_HOME}/etc/hadoop
-
-
export HIVE_HOME=/home/hadoop/hive-1.1.1
-
export HIVE_CONF_DIR=${HIVE_HOME}/conf
-
-
export HBASE_HOME=/home/hadoop/hbase-1.1.2
-
export HBASE_CONF_DIR=/home/hadoop/hbase-1.1.2/conf
-
-
export OLH_HOME=/home/hadoop/oraloader-3.5.0-h2
-
-
export HADOOP_CLASSPATH=/usr/share/java/mysql-connector-java.jar
-
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$HIVE_HOME/lib/*:$HIVE_CONF_DIR:$HBASE_HOME/lib/*:$HBASE_CONF_DIR
-
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$OLH_HOME/jlib/*
-
-
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$HBASE_HOME/bin:$PATH
- 配置Hadoop/Hive/Hbase软件
core-site.xml
-
<configuration>
-
<property>
-
<name>fs.defaultFS</name>
-
<value>hdfs://server1:8020</value>
-
</property>
-
<property>
-
<name>fs.checkpoint.period</name>
-
<value>3600</value>
-
</property>
-
<property>
-
<name>fs.checkpoint.size</name>
-
<value>67108864</value>
-
</property>
-
<property>
-
<name>hadoop.proxyuser.hadoop.groups</name>
-
<value>*</value>
-
</property>
-
<property>
-
<name>hadoop.proxyuser.hadoop.hosts</name>
-
<value>*</value>
-
</property>
-
</configuration>
hdfs-site.xml
-
<configuration>
-
<property>
-
<name>hadoop.tmp.dir</name>
-
<value>file:///home/hadoop</value>
-
</property>
-
<property>
-
<name>dfs.namenode.name.dir</name>
-
<value>file:///home/hadoop/dfs/nn</value>
-
</property>
-
<property>
-
<name>dfs.datanode.data.dir</name>
-
<value>file:///home/hadoop/dfs/dn</value>
-
</property>
-
<property>
-
<name>dfs.namenode.checkpoint.dir</name>
-
<value>file:///home/hadoop/dfs/sn</value>
-
</property>
-
<property>
-
<name>dfs.replication</name>
-
<value>1</value>
-
</property>
-
<property>
-
<name>dfs.permissions.superusergroup</name>
-
<value>supergroup</value>
-
</property>
-
<property>
-
<name>dfs.namenode.http-address</name>
-
<value>server1:50070</value>
-
</property>
-
<property>
-
<name>dfs.namenode.secondary.http-address</name>
-
<value>server1:50090</value>
-
</property>
-
<property>
-
<name>dfs.webhdfs.enabled</name>
-
<value>true</value>
-
</property>
-
</configuration>
yarn-site.xml
-
<configuration>
-
<property>
-
<name>yarn.resourcemanager.scheduler.address</name>
-
<value>server1:8030</value>
-
</property>
-
<property>
-
<name>yarn.resourcemanager.resource-tracker.address</name>
-
<value>server1:8031</value>
-
</property>
-
<property>
-
<name>yarn.resourcemanager.address</name>
-
<value>server1:8032</value>
-
</property>
-
<property>
-
<name>yarn.resourcemanager.admin.address</name>
-
<value>server1:8033</value>
-
</property>
-
<property>
-
<name>yarn.resourcemanager.webapp.address</name>
-
<value>server1:8088</value>
-
</property>
-
<property>
-
<name>yarn.nodemanager.local-dirs</name>
-
<value>file:///home/hadoop/yarn/local</value>
-
</property>
-
<property>
-
<name>yarn.nodemanager.log-dirs</name>
-
<value>file:///home/hadoop/yarn/logs</value>
-
</property>
-
<property>
-
<name>yarn.log-aggregation-enable</name>
-
<value>true</value>
-
</property>
-
<property>
-
<name>yarn.nodemanager.remote-app-log-dir</name>
-
<value>/yarn/apps</value>
-
</property>
-
<property>
-
<name>yarn.app.mapreduce.am.staging-dir</name>
-
<value>/user</value>
-
</property>
-
<property>
-
<name>yarn.nodemanager.aux-services</name>
-
<value>mapreduce_shuffle</value>
-
</property>
-
<property>
-
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
-
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
-
</property>
-
<property>
-
<name>yarn.log.server.url</name>
-
<value>http://server1:19888/jobhistory/logs/</value>
-
</property>
-
</configuration>
- 配置hive metastore
我们采用MySQL作为hive的metastore,创建MySQL数据库
-
mysql> create database metastore DEFAULT CHARACTER SET latin1;
-
Query OK, 1 row affected (0.00 sec)
-
-
mysql> grant all on metastore.* TO 'hive'@'server1' IDENTIFIED BY '123456';
-
Query OK, 0 rows affected (0.00 sec)
-
-
mysql> flush privileges;
-
Query OK, 0 rows affected (0.00 sec)
-
</property>
- 配置Hive
hive-site.xml
-
<configuration>
-
<property>
-
<name>javax.jdo.option.ConnectionURL</name>
-
<value>jdbc:mysql://server1:3306/metastore?createDatabaseIfNotExist=true</value>
-
</property>
-
<property>
-
<name>javax.jdo.option.ConnectionDriverName</name>
-
<value>com.mysql.jdbc.Driver</value>
-
</property>
-
<property>
-
<name>javax.jdo.option.ConnectionUserName</name>
-
<value>hive</value>
-
</property>
-
<property>
-
<name>javax.jdo.option.ConnectionPassword</name>
-
<value>123456</value>
-
</property>
-
<property>
-
<name>hbase.master</name>
-
<value>server1:16000</value>
-
</property>
-
<property>
-
<name>hive.cli.print.current.db</name>
-
<value>true</value>
-
</property>
-
</configuration>
- 创建Hive表
-
CREATE EXTERNALTABLEcatalog(CATALOGID INT,JOURNAL STRING, PUBLISHER STRING,
-
EDITION STRING,TITLE STRING,AUTHOR STRING) ROW FORMAT DELIMITED FIELDS
-
TERMINATED BY ',' LINES TERMINATED BY '\n' STORED
-
AS
-
TEXTFILE LOCATION '/catalog';
- 配置Oracle Loader的配置文件
-
<?xml version="1.0" encoding="UTF-8" ?>
-
<configuration>
-
-
<!-- Input settings -->
-
<property>
-
<name>mapreduce.inputformat.class</name>
-
<value>oracle.hadoop.loader.lib.input.HiveToAvroInputFormat</value>
-
</property>
-
<property>
-
<name>oracle.hadoop.loader.input.hive.databaseName</name>
-
<value>default</value>
-
</property>
-
<property>
-
<name>oracle.hadoop.loader.input.hive.tableName</name>
-
<value>catalog</value>
-
</property>
-
<property>
-
<name>mapred.input.dir</name>
-
<value>/user/hive/warehouse/catalog</value>
-
</property>
-
<property>
-
<name>oracle.hadoop.loader.input.fieldTerminator</name>
-
<value>\u002C</value>
-
</property>
-
-
<!-- Output settings -->
-
<property>
-
<name>mapreduce.job.outputformat.class</name>
-
<value>oracle.hadoop.loader.lib.output.JDBCOutputFormat</value>
-
</property>
-
<property>
-
<name>mapreduce.output.fileoutputformat.outputdir</name>
-
<value>oraloadout</value>
-
</property>
-
-
<!-- Table information -->
-
<property>
-
<name>oracle.hadoop.loader.loaderMap.targetTable</name>
-
<value>catalog</value>
-
</property>
-
<property>
-
<name>oracle.hadoop.loader.input.fieldNames</name>
-
<value>CATALOGID,JOURNAL,PUBLISHER,EDITION,TITLE,AUTHOR</value>
-
</property>
-
-
<!-- Connection information -->
-
<property>
-
<name>oracle.hadoop.loader.connection.url</name>
-
<value>jdbc:oracle:thin:@${HOST}:${TCPPORT}:${SID}</value>
-
</property>
-
<property>
-
<name>TCPPORT</name>
-
<value>1521</value>
-
</property>
-
<property>
-
<name>HOST</name>
-
<value>server1</value>
-
</property>
-
<property>
-
<name>SID</name>
-
<value>orcl</value>
-
</property>
-
<property>
-
<name>oracle.hadoop.loader.connection.user</name>
-
<value>baron</value>
-
</property>
-
<property>
-
<name>oracle.hadoop.loader.connection.password</name>
-
<value>baron</value>
-
</property>
-
</configuration>
- 使用Oracle Loader for Hadoop加载Hive表到Oracle数据库
这里需要注意两点:
1 必须添加Hive配置文件路径到HADOOP_CLASSPATH环境变量
2 必须命令行调用hive-exec-*.jar hive-metastore-*.jar libfb303*.jar
-
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$OLH_HOME/jlib/*:$HIVE_HOME/lib/*:$HIVE_CONF_DIR
-
hadoop jar $OLH_HOME/jlib/oraloader.jar oracle.hadoop.loader.OraLoader \
-
-conf OraLoadJobConf-hive.xml \
-
-libjars $OLH_HOME/jlib/oraloader.jar,$HIVE_HOME/lib/hive-exec-1.1.1.jar,$HIVE_HOME/lib/hive-metastore-1.1.1.jar,$HIVE_HOME/lib/libfb303-0.9.2.jar
输出结果如下:
-
Oracle Loader for Hadoop Release 3.4.0 - Production
-
Copyright (c) 2011, 2015, Oracle and/or its affiliates. All rights reserved.
-
SLF4J: Class path contains multiple SLF4J bindings.
-
SLF4J: Found binding in [jar:file:/home/hadoop/hadoop-2.6.2/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
-
SLF4J: Found binding in [jar:file:/home/hadoop/hive-1.1.1/lib/hive-jdbc-1.1.1-standalone.jar!/org/slf4j/impl/StaticLoggerBinder.class]
-
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
-
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
-
15/12/08 04:53:51 INFO loader.OraLoader: Oracle Loader for Hadoop Release 3.4.0 - Production
-
Copyright (c) 2011, 2015, Oracle and/or its affiliates. All rights reserved.
-
15/12/08 04:53:51 INFO loader.OraLoader: Built-Against: hadoop-2.2.0 hive-0.13.0 avro-1.7.3 jackson-1.8.8
-
15/12/08 04:53:51 INFO Configuration.deprecation: mapreduce.outputformat.class is deprecated. Instead, use mapreduce.job.outputformat.class
-
15/12/08 04:53:51 INFO Configuration.deprecation: mapred.output.dir is deprecated. Instead, use mapreduce.output.fileoutputformat.outputdir
-
15/12/08 04:54:23 INFO Configuration.deprecation: mapred.submit.replication is deprecated. Instead, use mapreduce.client.submit.file.replication
-
15/12/08 04:54:24 INFO loader.OraLoader: oracle.hadoop.loader.loadByPartition is disabled because table: CATALOG is not partitioned
-
15/12/08 04:54:24 INFO output.DBOutputFormat: Setting reduce tasks speculative execution to false for : oracle.hadoop.loader.lib.output.JDBCOutputFormat
-
15/12/08 04:54:24 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
-
15/12/08 04:54:26 WARN loader.OraLoader: Sampler is disabled because the number of reduce tasks is less than two. Job will continue without sampled information.
-
15/12/08 04:54:26 INFO loader.OraLoader: Submitting OraLoader job OraLoader
-
15/12/08 04:54:26 INFO client.RMProxy: Connecting to ResourceManager at server1/192.168.56.101:8032
-
15/12/08 04:54:28 INFO metastore.HiveMetaStore: 0: Opening raw store with implemenation class:org.apache.hadoop.hive.metastore.ObjectStore
-
15/12/08 04:54:28 INFO metastore.ObjectStore: ObjectStore, initialize called
-
15/12/08 04:54:29 INFO DataNucleus.Persistence: Property hive.metastore.integral.jdo.pushdown unknown - will be ignored
-
15/12/08 04:54:29 INFO DataNucleus.Persistence: Property datanucleus.cache.level2 unknown - will be ignored
-
15/12/08 04:54:31 INFO metastore.ObjectStore: Setting MetaStore object pin classes with hive.metastore.cache.pinobjtypes="Table,StorageDescriptor,SerDeInfo,Partition,Database,Type,FieldSchema,Order"
-
15/12/08 04:54:33 INFO DataNucleus.Datastore: The class "org.apache.hadoop.hive.metastore.model.MFieldSchema" is tagged as "embedded-only" so does not have its own datastore table.
-
15/12/08 04:54:33 INFO DataNucleus.Datastore: The class "org.apache.hadoop.hive.metastore.model.MOrder" is tagged as "embedded-only" so does not have its own datastore table.
-
15/12/08 04:54:34 INFO DataNucleus.Datastore: The class "org.apache.hadoop.hive.metastore.model.MFieldSchema" is tagged as "embedded-only" so does not have its own datastore table.
-
15/12/08 04:54:34 INFO DataNucleus.Datastore: The class "org.apache.hadoop.hive.metastore.model.MOrder" is tagged as "embedded-only" so does not have its own datastore table.
-
15/12/08 04:54:34 INFO DataNucleus.Query: Reading in results for query "org.datanucleus.store.rdbms.query.SQLQuery@0" since the connection used is closing
-
15/12/08 04:54:34 INFO metastore.MetaStoreDirectSql: Using direct SQL, underlying DB is MYSQL
-
15/12/08 04:54:34 INFO metastore.ObjectStore: Initialized ObjectStore
-
15/12/08 04:54:34 INFO metastore.HiveMetaStore: Added admin role in metastore
-
15/12/08 04:54:34 INFO metastore.HiveMetaStore: Added public role in metastore
-
15/12/08 04:54:35 INFO metastore.HiveMetaStore: No user is added in admin role, since config is empty
-
15/12/08 04:54:35 INFO metastore.HiveMetaStore: 0: get_table : db=default tbl=catalog
-
15/12/08 04:54:35 INFO HiveMetaStore.audit: ugi=hadoop ip=unknown-ip-addr cmd=get_table : db=default tbl=catalog
-
15/12/08 04:54:36 INFO mapred.FileInputFormat: Total input paths to process : 1
-
15/12/08 04:54:36 INFO metastore.HiveMetaStore: 0: Shutting down the object store...
-
15/12/08 04:54:36 INFO HiveMetaStore.audit: ugi=hadoop ip=unknown-ip-addr cmd=Shutting down the object store...
-
15/12/08 04:54:36 INFO metastore.HiveMetaStore: 0: Metastore shutdown complete.
-
15/12/08 04:54:36 INFO HiveMetaStore.audit: ugi=hadoop ip=unknown-ip-addr cmd=Metastore shutdown complete.
-
15/12/08 04:54:37 INFO mapreduce.JobSubmitter: number of splits:2
-
15/12/08 04:54:37 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1449544601730_0015
-
15/12/08 04:54:38 INFO impl.YarnClientImpl: Submitted application application_1449544601730_0015
-
15/12/08 04:54:38 INFO mapreduce.Job: The url to track the job: http://server1:8088/proxy/application_1449544601730_0015/
-
15/12/08 04:54:49 INFO loader.OraLoader: map 0% reduce 0%
-
15/12/08 04:55:07 INFO loader.OraLoader: map 100% reduce 0%
-
15/12/08 04:55:22 INFO loader.OraLoader: map 100% reduce 67%
-
15/12/08 04:55:47 INFO loader.OraLoader: map 100% reduce 100%
-
15/12/08 04:55:47 INFO loader.OraLoader: Job complete: OraLoader (job_1449544601730_0015)
-
15/12/08 04:55:47 INFO loader.OraLoader: Counters: 49
-
File System Counters
-
FILE: Number of bytes read=395
-
FILE: Number of bytes written=370110
-
FILE: Number of read operations=0
-
FILE: Number of large read operations=0
-
FILE: Number of write operations=0
-
HDFS: Number of bytes read=6005
-
HDFS: Number of bytes written=1861
-
HDFS: Number of read operations=9
-
HDFS: Number of large read operations=0
-
HDFS: Number of write operations=5
-
Job Counters
-
Launched map tasks=2
-
Launched reduce tasks=1
-
Data-local map tasks=2
-
Total time spent by all maps in occupied slots (ms)=29809
-
Total time spent by all reduces in occupied slots (ms)=36328
-
Total time spent by all map tasks (ms)=29809
-
Total time spent by all reduce tasks (ms)=36328
-
Total vcore-seconds taken by all map tasks=29809
-
Total vcore-seconds taken by all reduce tasks=36328
-
Total megabyte-seconds taken by all map tasks=30524416
-
Total megabyte-seconds taken by all reduce tasks=37199872
-
Map-Reduce Framework
-
Map input records=3
-
Map output records=3
-
Map output bytes=383
-
Map output materialized bytes=401
-
Input split bytes=5610
-
Combine input records=0
-
Combine output records=0
-
Reduce input groups=1
-
Reduce shuffle bytes=401
-
Reduce input records=3
-
Reduce output records=3
-
Spilled Records=6
-
Shuffled Maps =2
-
Failed Shuffles=0
-
Merged Map outputs=2
-
GC time elapsed (ms)=1245
-
CPU time spent (ms)=14220
-
Physical memory (bytes) snapshot=757501952
-
Virtual memory (bytes) snapshot=6360301568
-
Total committed heap usage (bytes)=535298048
-
Shuffle Errors
-
BAD_ID=0
-
CONNECTION=0
-
IO_ERROR=0
-
WRONG_LENGTH=0
-
WRONG_MAP=0
-
WRONG_REDUCE=0
-
File Input Format Counters
-
Bytes Read=0
-
File Output Format Counters
-
Bytes Written=1620
- 问题
Oracle Loader for Hadoop的问题是出现未加载到数据库成功的行并没有报错提示