python 函数操作
四、函数
定义:
#!/usr/local/env python3
'''
Author:@南非波波
Blog:http://www.cnblogs.com/songqingbo/
E-mail:[email protected]
'''
#定义函数,作用打印一个值
def num_print():
n = 456
n += 1
print(n)
使用:
#函数调用
num_print()
#将f变量指向函数num_print,然后调用f()相当于调用num_print()
f = num_print
f()参数
形参:函数中一个变量,在函数执行前无意义,在函数调用时必须指定实际参数。
实参:实际参数用户传递给所调用的函数的一个变量,其值赋值到函数中的形式参数,然后在函数中 作为变量参与函数执行
默认参数:必须放在最后
def show(a1,a2,a3 = 5):
print(a1,a2,a3)
show("wu","ha")
#返回结果:wu ha 5
指定参数:
def show(a1,a2):
print(a1,a2)
show(a2=52,a1=8)
#返回结果:8 52
动态参数:
*arg --序列:自动转换成一个元组
def show(*arg):
print(arg,type(arg))
show(23,45,67)
#返回结果:(23, 45, 67) <class 'tuple'>
#or
l = [23,45,67]
show(*l)
#返回结果:(23, 45, 67) <class 'tuple'>
**arg --字典:自动转换成一个字典
#默认字典处理
def show(**arg):
print(arg,type(arg))
show(name1='swht',name2='shen')
#返回结果:{'name1': 'swht', 'name2': 'shen'} <class 'dict'>
#or
d = {"name1"="swht","name2"="shen"}
show(**d)
#返回结果:{'name1': 'swht', 'name2': 'shen'} <class 'dict'>
*arg,**kwarges --序列和字典
def show(*args,**kwargs):
print(args,type(args),'\n',kwargs,type(kwargs))
show(23,45,67,82,name1='swht',name2='shen')
#返回结果:(23, 45, 67, 82) <class 'tuple'>
{'name2': 'shen', 'name1': 'swht'} <class 'dict'>
注意:使用*arg,**kwarges组合参数,必须是*arg在前,**kwarges在后,否则系统报错;另外实参在输入的时候也应该是按照上述顺序。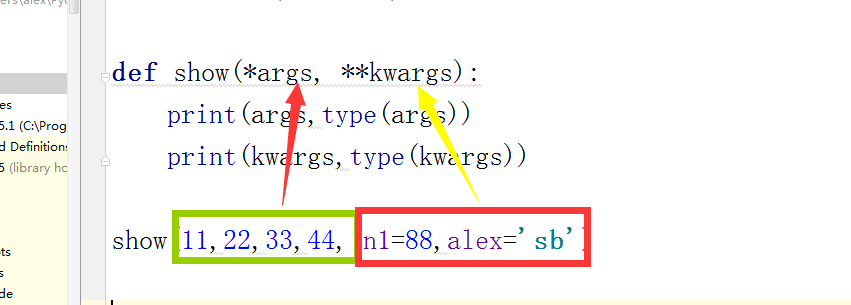
拓展:
def show(*args,**kwargs):
print(args,type(args),'\n',kwargs,type(kwargs))
l = [23,45,67,82]
d = {'name1':'swht','name2':'shen'}
show(l,d)
#返回结果:
([23, 45, 67, 82], {'name1': 'swht', 'name2': 'shen'}) <class 'tuple'>
{} <class 'dict'>
def show(*args,**kwargs):
print(args,type(args),'\n',kwargs,type(kwargs))
l = [23,45,67,82]
d = {'name1':'swht','name2':'shen'}
show(*l,**d)
#返回结果:
(23, 45, 67, 82) <class 'tuple'>
{'name2': 'shen', 'name1': 'swht'} <class 'dict'>
总结:
函数可以传递元组、列表、字典等类型的值,由于带'*'、'**'的参数允许传入多个参数,所以在调用函数的时候默认将传入的参数识别到第一个*args。为了指定将参数传给某个args,这里需要对实参进行加'*'进行标识。
#list
show = "Welcome to {0},there have too many {1}!"
# reault = show.format("China","Foods")
l = ["China","Foods"]
reault = show.format(*l)
print(reault)
#返回结果:Welcome to China,there have too many Foods!
#dict
show = "{name} is a {acter}!"
# reault = show.format(name='swht',acter='teacher')
d = {'name':'swht','acter':'teacher'}
reault = show.format(**d)
print(reault)
#返回结果:swht is a teacher!lambda表达式
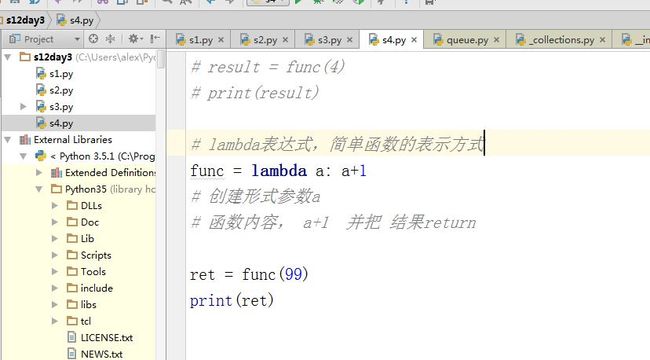
功能:简单函数的表示方式
func = lambda a:a+1
函数名 关键字 形参:函数体
创建形式参数a,函数内容为a+1,并将结果return
测试代码:
f = lambda x:x + 1
ret = f(4)
print(ret)内置函数
abs()
功能:取绝对值
>>> abs(5)
5
>>> abs(-85)
85all(iterable)
功能:iterable所有的元素都为真,返回True,否则返回False
备注:为False的元素:0、''、False或者空,其他的为True
参数:iterable为可迭代对象
all的功能可以使用下面的函数进行理解:
def all(iterable):
for element in iterable:
if not element:
return False
return True
测试代码:
all('test,hh')
返回值为:True
>>> all(['a', 'b', 'c', 'd']) #列表list,元素都不为空或0
True
>>> all(['a', 'b', '', 'd']) #列表list,存在一个为空的元素
False
>>> all([0, 1,2, 3]) #列表list,存在一个为0的元素
False
>>> all(('a', 'b', 'c', 'd')) #元组tuple,元素都不为空或0
True
>>> all(('a', 'b', '', 'd')) #元组tuple,存在一个为空的元素
False
>>> all((0, 1,2, 3)) #元组tuple,存在一个为0的元素
False
>>> all([]) # 空列表
True
>>> all(()) # 空元组
True any(iterable)
功能:iterable中元素只要有一个元素为真,则返回True,否则返回False(即iterable中所有的元素为假才会返回False)
参数:iterable为可迭代对象
any的功能可以使用下面的函数进行理解:
def any(iterable):
for element in iterable:
if element:
return False
return True
测试代码:
>>> any([0,1,2,3]) #列表中仅有一个元素0为假,返回True
True
>>> any([' ', ' ', '', 0])
True
>>> any([0]) #列表中元素只有一个元素0,返回False
False
>>> any([0,''])
False
>>> any([0,'',4])
True
>>> any(('a', 'b', 'c', 'd')) #元组tuple,元素都不为空或0
True
>>> any(('a', 'b', '', 'd')) #元组tuple,存在一个为空的元素
True
>>> any((0, '', False)) #元组tuple,元素全为0,'',false
False
>>> any([]) # 空列表
False
>>> any(()) # 空元组
False
map(iterable)
功能:对可迭代函数'iterable'中的每一个元素应用‘function’方法,将结果作为list返回
参考链接:http://segmentfault.com/a/1190000000322433
测试代码:
def add_100(num):
return num + 100
li1 = [25,26,27]
ret = list(map(add_100,li1))
print(ret)
返回结果:[125, 126, 127]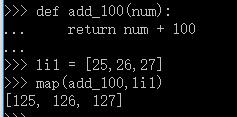
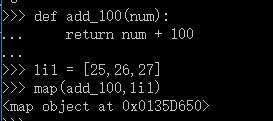
python2.7 python3.5
两个版本的对比,真是让人感到诧异,python3上执行map明明已经获取了值,但非得加个list进行展示,超乎寻常。
def abc(a,b,c):
return a*1000 + b*100 + c*10
list1 = [11,22,33]
list2 = [44,55,66]
list3 = [77,88,99]
ret = list(map(abc,list1,list2,list3))
print(ret) #返回结果 [16170, 28380, 40590]
ascii(object)
功能:该函数与python2中的repr()函数一样,返回一个可打印的对象字符串。当遇到非ascii码时,就会输出\x,\u或\U等字符来表示。例如:ascii(4) = int.__repr__(4) = repr(4)等号两边的方式是对等的。
测试代码:
>>> ascii(54)
'54'
>>> ascii('o')
"'o'"
>>> type(ascii(54))
<class 'str'>
>>> print(ascii(10), ascii(9000000), ascii('b\31'), ascii('0x\1000'))
10 9000000 'b\x19' '0x@0'bin()
功能:将整数转换为二进制字符串
>>> bin(56)
'0b111000'
>>> bin(100)
'0b1100100'
注意:如果bin()函数的实际参数不是一个整数,则该该实参(由类创建的对象)返回值必须是整数型
如:
>>> class myType:
... def __index__(self):
... return 56
...
>>> myvar = myType()
>>> bin(myvar)
'0b111000'bool()
功能:获取对象的bool值
bool(0) #False
bool(5) #True
bool('') #False
#为假的元素:0 none 空列表 空字典 空元组 空字符串bytearray()
功能:转成字符字典。Bytearray类型是一个可变的序列,并且序列中的元素的取值范围为 [0 ,255]。
>>> a = bytearray([5,8])
>>> a[0]
5
>>> a[1]
8
>>> a
bytearray(b'\x05\x08')bytes()
功能:返回一个新的数组对象,这个数组不能对数组元素进行修改,每个元素的取值范围为[0 ,255]
测试代码:
bytes(iterable_of_ints)
>>> b = bytes((5,8,6,8))
>>> print(b)
b'\x05\x08\x06\x08'
bytes(string, encoding[, errors])
>>> bytes('sdjsd',encoding='utf-8')
b'sdjsd'
bytes(bytes_or_buffer) ?
bytes(int)
>>> bytes(5)
b'\x00\x00\x00\x00\x00'
bytes()
>>> bytes()
b''
总结:(参考:http://blog.csdn.net/caimouse/article/details/40860827)
bytes函数与bytearray函数主要区别是bytes函数产生的对象的元素不能修改,而bytearray函数产生的对象的元素可以修改。因此,除了可修改的对象函数跟bytearray函数不一样之外,其它使用方法全部是相同的。最后它的参数定义方式也与bytearray函数是一样的。callable()
功能:判断函数或者对象是否可执行
>>> callable(5)
False
>>> callable(0)
False
>>> callable('')
False
>>> callable(int())
False
>>> callable(lambda x:x+1)
Truechr()
功能:参数为一个整型数字,返回值对应ASCII码的字符
>>> chr(5)
'\x05'
>>> chr(115)
's'
>>> chr(56)
'8'ord()
功能:返回一个字符的ASCII码值
>>> ord('s')
115
>>> ord('5')
53classmethod()
功能:classmethod是用来指定一个类的方法为类方法,没有此参数指定的类的方法为实例方法
>>> class C: #定义一个类
... @classmethod #声明为类方法,不经过实例化就可以直接调用
... def f(self): #定义一个函数(类的方法)
... print "This is a class method"
...
>>> C.f() #通过类调用函数
This is a class method
>>> c = C()
>>> c.f()
This is a class method
>>> class D:
... def f(self):
... print " This is not a class method "
...
>>> D.f() #没有经过@classmethod 声明的类方法,必须经过实例化才能被调用
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unbound method f() must be called with D instance as first argument (got nothing instead)
>>> d = D()
>>> d.f()
This is not a class methodstaticmethod()
功能:类的静态方法,只能在类内部使用。经过静态类方法声明的类,在调用的时候不需要进行实例化
总结:对比classmethod()和staticmethod()
静态方法:@staticmethod()
class Foo(object):
str = "I'm a static method."
def bar():
print(Foo.str)
bar = staticmethod(bar)
Foo.bar()
返回结果:I'm a static method.
类方法:@classmethod()
class Foo(object):
str = "I'm a static method."
def bar(cls):
print(cls.str)
bar = classmethod(bar)
Foo.bar()
返回结果:I'm a static method.
较简单的操作代码:
静态方法:@staticmethod()
class Foo:
str = "I'm a static method."
@staticmethod
def bar():
print(Foo.str)
Foo.bar()
返回结果:I'm a static method.
类方法:@classmethod()
class Foo:
str = "I'm a static method."
@classmethod
def bar(cls):
print(cls.str )
Foo.bar()
返回结果:I'm a static method.compile()、eval()、exec()
功能:compile语句是从type类型中将str里面的语句创建成代码对象。
compile语句的目的是提供一次性的字节码编译,就不用在以后的每次调用中重新进行编译了
语法:compile( str, file, type )
eveal_code = compile('1+2','','eval')
>>>eveal_code
返回结果:<code object <module> at 0x01555D40, file "", line 1>
>>>eval(eveal_code)
返回结果:3
single_code = compile( 'print("apicloud.com")', '', 'single' )
>>> single_code
返回结果:<code object <module> at 0x01555B10, file "", line 1>
>>> exec(single_code)
返回结果:apicloud.comcomplex()
功能:创建一个值为real + imag * j的复数或者转化一个字符串或数为复数。如果第一个参数为字符串,则不需要指定第二个参数。
参数real: int, long, float或字符串;
参数imag: int, long, float
>>>complex()
0j
#数字
>>> complex(1,2)
(1+2j)
#当做字符串处理
>>> complex('1')
(1+0j)
#注意:这个地方在“+”号两边不能有空格,也就是不能写成"1 + 2j",应该是"1+2j",否则会报错
>>> complex('1+2j')
(1+2j)delattr()
参考链接:http://www.cnblogs.com/zhangjing0502/archive/2012/05/16/2503702.html
功能:删除object对象名为name的属性
语法:delattr(object,name)
参数object:对象。
参数name:属性名称字符串。
>>> class Person:
... def __init__(self, name, age):
... self.name = name
... self.age = age
...
>>> tom = Person("Tom", 35)
>>> dir(tom)
['__doc__', '__init__', '__module__', 'age', 'name']
>>> delattr(tom, "age")
>>> dir(tom)
['__doc__', '__init__', '__module__', 'name']getattr()
功能:用于返回一个对象属性,或者方法
class A:
def __init__(self):
self.name = 'zhangjing'
#self.age='24'
def method(self):
print("method print")
Instance = A()
print(getattr(Instance , 'name', 'not find')) #如果Instance 对象中有属性name则打印self.name的值,否则打印'not find'
print(getattr(Instance , 'age', 'not find')) #如果Instance 对象中有属性age则打印self.age的值,否则打印'not find'
print(getattr(a, 'method', 'default'))
#如果有方法method,否则打印其地址,否则打印default
print(getattr(a, 'method', 'default')())
#如果有方法method,运行函数并打印None否则打印default
li=["swht","shen"]
getattr(li,"pop")
返回结果:<built-in method pop of list object at 0x01AFDA80>
setattr()
功能:参数是一个对象,一个字符串和一个任意值。字符串可能会列出一个现有的属性或一个新的属性。这个函数将值赋给属性的。该对象允许它提供。
语法:setattr(object, name, value)
setattr(x,“foobar”,123)相当于x.foobar = 123hasattr()
功能:用于确定一个对象是否具有某个属性
语法:hasattr(object, name) -> bool
判断object中是否有name属性,返回一个布尔值
li=["swht","shen"]
hasattr(li,'append')
返回结果:Truedict()
功能:字典定义函数,可以创建一个字典,也可以将其他类型(列表、元组、字符串)转换成字典类型
定义:
dict1 = dict(one = 1, two = 2, a = 3)
prin(dict1)
{'one': 1, 'a': 3, 'two': 2}
类型转换:
list1 = ['name','age',]
list2 = ['swht',18]
dict(zip(list1,list2))
返回结果:{'name': 'swht', 'age': 18}
new_list= [['key1','value1'],['key2','value2'],['key3','value3']]
dict(new_list)
返回结果:{'key3': 'value3', 'key1': 'value1', 'key2': 'value2'}dir()
功能:查看函数或模块内的操作方法都有什么,输出的是方法列表。
如dir(int)可以直接获取int的所有方法,返回的类型是一个列表divmod()
功能:divmod(a,b)方法返回的是a//b(除法取整)以及a对b的余数
>>> divmod(2,5)
(0, 2)
>>> divmod(12,5)
(2, 2)enumerate()
功能:获取字典的索引值并指定开始值
li = ['swht','shen','test']
for i,k in enumerate(li,3): #遍历列表,索引值从3开始
print(i,k)
#返回结果
3 swht
4 shen
5 testfilter()
参考链接:http://www.cnblogs.com/fangshenghui/p/3445469.html
功能:filter(function, sequence)对于队列中的item依次被function处理
def fun(item):
if item != 4:
return item
list1 = [5,4,8]
print(list(filter(fun,list1)))
返回结果:[4, 8]
总结:相当于一个过滤函数frozenset()
参考:http://blog.csdn.net/caimouse/article/details/42042051
功能:本函数是返回一个冻结的集合
l = [1, 2, 3, 4, 5, 6, 6, 7, 8, 8, 9]
print(len(l), l)
set = frozenset(l)
print(len(set), set)
返回结果:11 [1, 2, 3, 4, 5, 6, 6, 7, 8, 8, 9]
9 frozenset({1, 2, 3, 4, 5, 6, 7, 8, 9})
总结:所谓冻结就是这个集合不能再添加或删除任何集合里的元素。因此与集合set的区别,就是set是可以添加或删除元素,而frozenset不行。frozenset的主要作用就是速度快,它是使用hash算法实现。参数iterable是表示可迭代的对象,比如列表、字典、元组等等locals()、globals()
功能:基于字典的访问局部和全局变量的方式
locals 是只读的,globals 不是
关于名字空间的相关说明请移步参考:http://blog.csdn.net/scelong/article/details/6977867hash()
功能:输出对象的hash值
>>> hash(8)
8
>>> hash('sd')
-584109415
>>> hash('99')
-1356598271
>>> hash('asds')
-1179125483help()
功能:查看函数或模块用途的详细说明
使用方法:help(object)类型转换
int(x [,base ]) 将x转换为一个整数
long(x [,base ]) 将x转换为一个长整数
float(x ) 将x转换到一个浮点数
complex(real [,imag ]) 创建一个复数
str(x ) 将对象 x 转换为字符串
repr(x ) 将对象 x 转换为表达式字符串
eval(str ) 用来计算在字符串中的有效Python表达式,并返回一个对象
tuple(s ) 将序列 s 转换为一个元组
list(s ) 将序列 s 转换为一个列表
chr(x ) 将一个整数转换为一个字符
unichr(x ) 将一个整数转换为Unicode字符
ord(x ) 将一个字符转换为它的整数值
hex(x ) 将一个整数转换为一个十六进制字符串
oct(x ) 将一个整数转换为一个八进制字符串id()
功能:获取对象的内存地址
id(object)input()
功能:获取用户的输入信息
input("请输入你的名字:")
>>>请输入你的名字:swht
swhtisinstance()
功能:判断对象类型
isinstance(5,int)
返回结果:Trueissubclass()
功能:本函数用来判断类参数class是否是类型参数classinfo的子类
class Line:
pass
class RedLine(Line):
pass
class Rect:
pass
print(issubclass(RedLine, Line)) #返回True Redline是Line的子类
print(issubclass(Rect, Line)) #返回False
iter()
功能:创建一个迭代器
for i in iter((1,2,4,5,6,7,)):
print(i)
返回结果:1 2 4 5 6 7 #循环遍历元组len()
功能:获取字符串的长度
len(str)max()
功能:返回所有整数中最大的一个数
max(5,6,8,7)
返回结果:8memoryview()
功能:本函数是返回对象obj的内存查看对象
>>> v = memoryview(b'abc123')
>>> print(v[1])
98
>>> print(v[0])
97
>>> print(v[2])
import struct
buf = struct.pack("i"*12, *list(range(12)))
x = memoryview(buf)
y = x.cast('i', shape=[2,2,3])
print(y.tolist())
返回结果:[[[0, 1, 2], [3, 4, 5]], [[6, 7, 8], [9, 10, 11]]]
总结:所谓内存查看对象,就是对象符合缓冲区协议的对象,为了给别的代码使用缓冲区里的数据,而不必拷贝,就可以直接使用。参考链接:http://blog.csdn.net/caimouse/article/details/43083627sorted()
功能:排序
sorted([5, 2, 3, 1, 4])
[1, 2, 3, 4, 5]sum()
功能:返回整数数字的和
sum([1,5,8]) #参数是一个list
返回结果:14super()
功能:用来解决多重继承问题type()
功能:获取对象的类型
type(object)vars()
功能:本函数是实现返回对象object的属性和属性值的字典对象
>>> class Foo:
... a = 1
...
>>> print(vars(Foo))
{'a': 1, '__dict__': <attribute '__dict__' of 'Foo' objects>, '__doc__': None, '__weakref__': <attribute '__weakref__' of 'Foo' objects>, '__module__': '__main__'}
总结:如果默认不输入参数,就打印当前调用位置的属性和属性值,相当于locals()的功能。如果有参数输入,就只打印这个参数相应的属性和属性值。参考:http://blog.csdn.net/caimouse/article/details/46489079zip()
功能:zip函数接受任意多个(包括0个和1个)序列作为参数,返回一个tuple列表
>>> x = [1,2,3,]
>>> y = [4,5,6,]
>>> z = [7,8,9,]
>>> xyz = zip(x,y,z)
>>> print(xyz)
<zip object at 0x00FBD968>
>>> print(list(xyz))
[(1, 4, 7), (2, 5, 8), (3, 6, 9)]random
功能:产生随机数
import random
random.randint(1,99) #从1-99中产生随机数import()
功能:查看模块所在的位置
__import__('random') #参数为一个字符串
<module 'random' from 'D:\\Program Files\\Python\\Python35\\python35.zip\\random.pyc'>open()函数
博客参考:http://www.cnblogs.com/songqingbo/p/5102618.html
read()
功能:读取文件中的所有内容,返回的类型是字节readline()
功能:读取文件中的一行数据。返回的类型是字节readlines()
功能:读取文件中的所有内容,返回的类型是listtell()
功能:查看当前指针位置,返回值类型为整数seek()
功能:指定当前指针位置
files = open('test.txt','r',encoding='utf-8')
files.seek(5)
print(files.read()) #读取指为直接切割针5后面的所有字符
files.truncate() #获取指针5之前的所有字符然后写到原来的文件(或者可以理解)
files.close()扩展
读二进制文件:
input = open('data','rb')
读取所有内容:
f = open('test.txt','r')
try:
all_txt_view = f.read()
finally:
f.close()
读取固定字节:
f = open('test.txt','rb')
try:
while True:
chunk = f.read(100)
if not chunk:
break
pass
finally:
f.close()
读每行:
list_of_all_the_lines = f.readlines()
如果文件是文本文件,还可以直接遍历文件对象获取每行:
for line in f:
print(line)
写文件写文本文件
output = open('data','w')
写入多行:
f.writeline(list_of_text_string)