粒子滤波概述
粒子滤波器是贝叶斯滤波器的一种非参数执行情况,且经常用于估计一个动态系统的状态。粒子滤波器的关键思想是采用一套假设(即粒子)来表示后验概率,其中每一个假设代表了这个系统可能存在的一种潜在状态。状态假设表示为一个有 \( N \) 个加权随机样本的集合 \(S \) :
\( S=\left \{ < s^{[i]},w^{[i]} > |i=1,2,...,N \right \} \)
式中: \( s^{[i]}\)是第\( i \)个样本的状态向量;\( w^{[i]}\)是第\( i \)个样本的权重。权重为非0值,且所有权重的总和为1.该样本集合代表如下分布:
\(p\left ( x \right )=\sum_{i=1}^{N}w_{i}\cdot \delta_{s\left [ i \right ]}\left ( x \right )\)
式中:\(\delta_{s\left [ i \right ]}\)是在第\(i\)个样本的状态\( s^{[i]}\)下的狄拉克函数。样本集\(S\)可用于近似任意分布,这些样本则是从那些被近似的分布中采样而来。为了说明这种近似,下图(1)描述了两种分布及其相应的样本集。一般来说,被用的样本越多,近似越好。粒子滤波器利用一套样本集合对多模态分布模型建模的能力相比于其他系列的滤波器有优势,例如,卡尔曼滤波器近限于高斯分布。
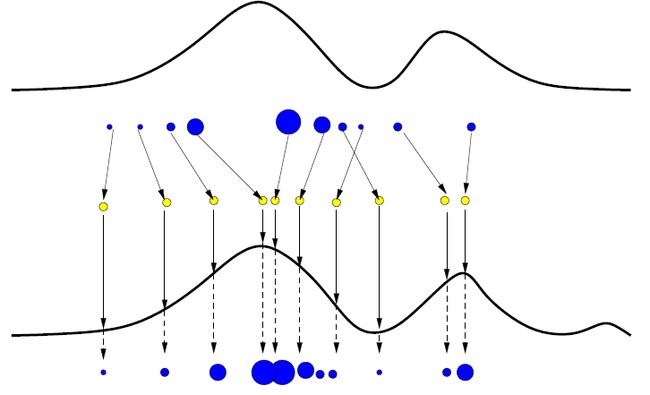
图(1)
当我们想要对一段时间内一个动态系统的状态进行估计时,可以采用粒子滤波算法。该方法就是在每个时间点采用一套样本,也称为粒子,来表示分布。粒子滤波算法使我们能够在前一段时间估计\(S_{t-1}\)的基础上递归估计出下一时刻的粒子集\(S_{t}\)。基于样本的重要性重采样(Sampling Importance Resampling,SIR)的粒子滤波器可归纳以以下三个步骤:
1、采样。在先前样本集\(S_{t}\)的基础上创建下一代粒子集\(S^{'}_{t}\)。这一步也被称作采样或从提议的分布中提取样本。
2、重要性加权。在集合\(S^{'}_{t}\)中为每个样本计算一个重要性权重。
3、重采样。从集合\(S^{'}_{t}\)中提取\(N\)个样本。其中,粒子被提取的可能性与它的权重成正比。由提取出的粒子获得新的集合\(S_{t}\)。
接下来将详细地解释这三个步骤。在第一步中,提取样本是为了获取下一个时刻的下一代粒子。一般来说,样本粒子的真实概率分布是未知的活着是一种不适合采样的形式。我们将说明从不同于我们想要近似的分布中提取样本是可能的。这种技术成为重要性采样。
我们面临计算一个期望值\(x\in A\)的问题,其中\(A\)是一个区域。一般来说一个函数\(f\)的期望\(E_{p}[f(x)]\)定义如下:
\(E_{p}[f(x)]=\int p(x)\cdot f(x)dx\)
定义一个函数\(B\):如果参数为真,则返回1,否则为0.我们可以通过以下表达式表示\(x \in A\)这个期望:
\(E_{p}[B(x \in A)]=\int p(x)\cdot B(x \in A)dx\)
\(E_{p}[B(x \in A)]=\int \frac{p(x)}{\pi(x)}\cdot \pi(x)\cdot B(x \in A)dx \)
其中\( \pi \)是一个分布,满足
\( p(x) > 0 \Rightarrow \pi(x)>0\) (1.1)
因此,可以定义权重\( w(x) \)为
\( w(x) = \frac{p(x)}{\pi(x)}\)(1.2)
权重\( w\)用于说明\( p\)和\( \pi\)之间的差异。从而推出
\(E_{p}[B(x \in A)]=\int \pi(x)\cdot w(x)\cdot B(x \in A)dx \)
\(E_{p}[B(x \in A)]= E_{\pi}[w(x) \cdot B(x \in A)] \)
让我们重新思考基于样本的表示并假设这个样本来自\( \pi \). 通过计算落入区域A的所有粒子,通过计算累加样本和来计算\( \pi \)在区间A上的积分,即
\( \int_{A}\pi(x)dx \approx \sum^{N}_{i=1}w^{[i]} \cdot B(s^{[i]} \in A)\)
可以证明,使用的样本越多近似的质量会越高。对于无限集合的样本,样本的总和收敛于这个积分:
\( \lim_{N \rightarrow \infty} \sum^{N}_{i=1}w^{[i]} \cdot B(s^{[i]} \in A)=\int_{A}\pi(x)dx\)
设\( p \)为不适合采样的概率分布,\( \pi\)为我们实际的采样分布。在重要性采样中,\( p\)通常称为目标分布,而\( \pi\)称为提议分布。
以上推导说明,我们可以通过对满足式(1.1)的任意分布\( \pi\)采样,并给每个样本按照式(1.2)分配一个重要的权重使得其近似分布\( p\)。这个必须确保从\( p\)分布中采样的某个状态在\(\pi\)分布中概率不为0。
参考资料:
[1]. Cyrill Stachniss(著), 陈白帆, 刘丽珏(译). 机器人地图创建与环境探索. 2013.5.