快速计算表达式树
前言
.NET 3.5中新增的表达式树(Expression Tree)特性,第一次在.NET平台中引入了“逻辑即数据”的概念。也就是说,我们可以在代码里使用高级语言的形式编写一段逻辑,但是这段逻辑最终会被保存为数据。正因为如此,我们可以使用各种不同的方法对它进行处理。例如,您可以将其转化为一个SQL查询,或者外部服务调用等等,这便是LINQ to Everything在技术实现上的重要基石之一。
实事求是地说,.NET 3.5中的表达式树的能力较为有限,只能用来表示一个“表达式”,而不能表示“语句”。也就是说,我们可以用它来表示一次“方法调用”或“属性访问”,但不能用它来表示一段“逻辑”。不过,微软在.NET 4.0中增强了这一特性。在.NET 4.0中,我们可以使用表达式树构建一段带有“变量声明”,“判断”,“循环”的逻辑。当“逻辑”成为“数据”时,我们就拥有了更广阔的空间来发挥创造力。例如,我们可以将一段使用C#编写的顺序型逻辑,转化为包含异步调用的客户端JavaScript代码,以此快速构建带有复杂客户端逻辑的Web应用程序。
不过,即便是.NET 3.5中表达式树的“半吊子”特性,也已经显著加强了.NET平台的能力,甚至改变了我们对于一些事物的使用方式。
表达式树的优势
由于.NET 3.5中的语言(如C# 3.0,VB.NET 9.0)都在语法层面上集成了表达式树的构建,因此API设计者可以充分利用表达式树的优势来提供更强大易用的API。优势主要有三个方面:
- 强类型
- 语义清晰
- 简化API开发
强类型
就以.NET平台中著名的Mock框架NMock来说,以下代码将会构造一个ICalculator接口的Mock对象,并指定Sum方法的一组输入和输出:
var mocks = new Mockery(); var mockCalculator = mock.NewMock<ICalculator>(); Expect.Once.On(mockCalculator) .Method("Sum") .With(1, 2) .Will(Return.Value(3));
与此形成鲜明对比的是,作为.NET平台中Mock框架的后起之秀Moq,充分利用了C# 3.0中的Lambda表达式特性改进了API。因此,以上代码在Moq中的近似实现便是:
Mock<ICalculator> mock = new Mock<ICalculator>(); mock.Setup(c => c.Sum(1, 2)).Returns(3);
NMock使用字符串表示“方法”,使用object数组来表示参数,用object存放返回值的做法,在Moq中完全变成了强类型的“方法调用”。这样,开发人员在使用Moq使便可以获得更好的工具支持,如编辑器的智能提示(Intellisense),编译器的静态检查等等。
语义清晰
从语法上看,使用Lambda表达式构建表达式树,与高级语言中最常见的语句并无二致。由于表达式树在使用时仅仅是“构建”,而不会真正“执行”,因此API设计者可以把它作为一种天然的DSL。例如在Moq中,我们便可以灵活指定ICalculator对象的行为:
Mock<ICalculator> mock = new Mock<ICalculator>(); mock.Setup(c => c.Divide(It.IsAny<int>(), 0)).Throws(new DivideByZeroException()); mock.Setup(c => c.Divide(0, It.Is<int>(i => i != 0))).Returns(0);
简化API开发
严格说来,“清晰语义”与API设计有关,并非表达式树的专利。例如同为.NET平台下的Mock框架,RhinoMocks使用如下的语法来定义Mock对象的行为:
var mocks = new MockRepository(); var mockCalculator = mocks.CreateMock<ICalculator>(); Expect.Call(mockCalculator.Sum(1, 2)).Return(3);
这样的语法可谓不输于Lambda表达式所体现出来的语义。可是,使用Lambda表达式与否大大影响了实现此类API的难度。在RhinoMocks中,语句执行之时会切切实实地调用Sum方法,于是我们就必须使用动态类型等.NET高级技术来实现这样的语法。而在Moq框架中,c => c.Sum(1, 2)这样的代码会被构建为一颗表达式树,成为“数据”,并不会对Sum方法产生任何调用。而API设计者所要做的,仅仅是对这些数据进行分析,以获取API使用者所希望表现出的含义而已。
表达式树的计算
对表达式树进行计算,是处理表达式树时中最常见的工作了。几乎可以这么说,任何处理表达式树的工作都无法回避这个问题。在这里,“表达式树的计算”是指将一个复杂的表达式树转化为一个常量。例如,下图中左侧的表达式树,便可以转化为右侧的常量。
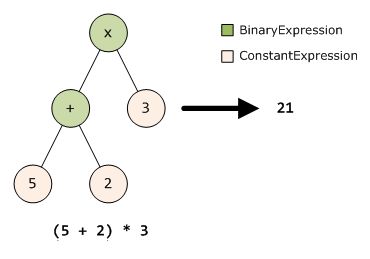
请注意,右侧的结果是一个常量,而不是一个ConstantExpression对象。当然,我们在必要的时候,也可以重新构造一个ConstantExpression对象,以便组成新的表达式树供后续分析。这个例子非常简单,而在实际的使用过程中遇到的表达式往往会复杂的多,他们可能包含“对象构造”、“下标访问”、“方法调用”、“属性读取”以及“?:”三目运算符等各种成员。它们的共同点,便是继承于Expression这一基类,并且最终都可以被计算为一个常量。
传统的表达式树的计算方式,是将其进行Compile为一个强类型的委托对象并加以执行,如下:
Expression<Func<DateTime>> expr = () => DateTime.Now.AddDays(1); Func<DateTime> tomorrow = expr.Compile(); Console.WriteLine(tomorrow());
如果是要计算一个类型不明确的表达式树,那么我们便需要要写一个通用的Eval方法,如下:
static object Eval(Expression expr) { LambdaExpression lambda = Expression.Lambda(expr); Delegate func = lambda.Compile(); return func.DynamicInvoke(null); } static void Main(string[] args) { Expression<Func<DateTime>> expr = () => DateTime.Now.AddDays(1); Console.WriteLine(Eval(expr.Body)); }
简单说来,计算表达式树的通用方法会分三步走:
- 将表达式树封装在一个LambdaExpression对象
- 调用LambdaExpression的Compile方法动态生成一个委托对象
- 使用DynamicInvoke方法调用该委托对象,获取其返回值
Compile方法在内部使用了Emit,而DynamicInvoke方法其本质与反射调用差不多,因此这种通用的表达式计算方法会带来相对较为可观的开销。尤其是在某些场景中,很容易出现大量表达式树的计算操作。例如,在开发ASP.NET MVC应用程序的视图时,“最佳实践”之一便是使用支持表达式树的辅助方法来构造链接,例如:
<h2>Article List</h2>
<% foreach (var article in Model.Articles) { %>
<div>
<%= Html.ActionLink<ArticleController>(c => c.Detail(article.ArticleID, 1), article.Title) %>
<% for (var page = 2; page <= article.MaxPage; page++) { %>
<small>
<%= Html.ActionLink<ArticleController>(c => c.Detail(article.ArticleID, page), page.ToString()) %>
</small>
<% } %> </div>
<% } %>
上述代码的作用,是在文章列表页上生成一系列指向文章详细页的链接。那么在上面的代码中,将会出现多少次表达式树的计算呢?
Html.ActionLink<ArticleController>(c => c.Detail(article.ArticleID, 1), article.Title) Html.ActionLink<ArticleController>(c => c.Detail(article.ArticleID, page), article.Title)
可以看出,每篇文章将进行(2 * MaxPage – 1)次计算,对于一个拥有数十篇文章的列表页,计算次数很可能逾百次。此外,再加上页面上的各种其它元素,如分类列表,Tag Cloud等等,每生成一张略为复杂的页面便会造成数百次的表达式树计算。从Simone Chiaretta的性能测试上来看,使用表达式树生成链接所花时间,大约为直接使用字符串的30倍。而根据我的本地测试结果,在一台P4 2.0 GHz的服务器上,单线程连续计算一万个简单的四则运算表达式便要花费超过1秒钟时间。这并非是一个可以忽略的性能开销,引入一种性能更好的表达式树计算方法势在必行。
减少Compile开销
如果您仔细比较Compile方法和DynamicInvoke方法的开销,您会发现前者占据了总耗时的90-95%。这意味着传统计算方式的性能瓶颈在于其编译过程,这也是我们首要进行优化的目标。
减少编译次数,就意味着复用编译的结果,便是缓存。如果使用键/值对的缓存方式,其“值”自然是编译的结果,即是委托对象。那么“键”呢?我们很容易得知“键”肯定是一个表达式树。不过,有个问题必须思考,什么样的表达式树适合作为“键”?例如,“(5 + 2) * 3”这样的表达式是否可以直接作为“键”来使用?
很显然,当我们再次遇上“(5 + 2) * 3”这样的表达式,我们便可直接获得之前编译所得的委托对象。如果两个表达式树“全等”自然不在话下——在这里“全等”的定义是“两个表达式树的结构完全相同,其中各个常量的值也对应相等”。但是,这一点在实际使用过程中的价值并不大,因为它至少存在以下几点问题:
- 复用性不高。例如之前举出的例子,循环内部每次使用的Article对象或page参数的值都各不相同,每次计算表达式树时还是需要重新编译。
- 常量对应相等,并不是复用编译结果的必要条件。例如还是那个例子,其实只要Article对象的ArticleID属性相等即可复用,而我们表达式中的常量是一个完整的article对象。
- 由于需要判断两个对象是否相等,这要求每个需要参与计算的常量都必须正确实现GetHashCode和Equals方法。这是个代价很高的副作用。
既然是要缓存,则必须要考虑到缓存的命中率。“全等”的最大问题还是缓存的命中率过于低下,甚至会导致“还不如不缓存”的情况发生。不过,当我们仔细分析各种情况后会发现,其实我们可以有更好的方式来复用编译结果。
在一个项目中,只要不是动态构建表达式树,那么其中可能会出现的表达式树的“结构”肯定是有限的。还是拿之前的例子来说,我们虽然有许多次循环,但是需要计算的表达式只有两种不同的结构:article.ArticleID和page——而不同的计算,只是使用不同的“值”去填充常量的位置而已。同样道理,表达式“(5 + 2) * 3”与“(4 + 6) * 7”的结构完全相同。因此,我们可以在对一棵表达式树进行计算时,可以先将其“结构化”,如下图:
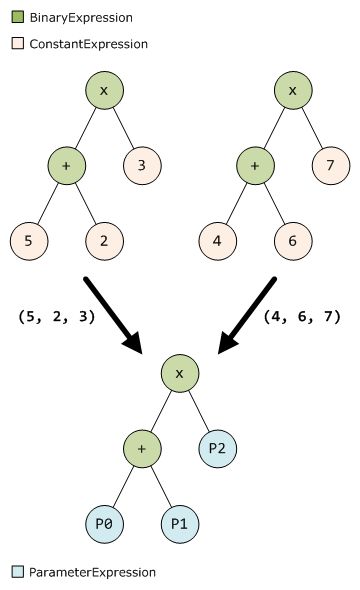
如果我们把表达式树的所有常量替换成同类型的参数(ParameterExpression)对象,那么系统中所有的表达式树都可以变为有限的几种结构。它们之间的区别,只是在替换的过程中提取到的“常量序列”不同。如果我们把包含参数的表达式树编译为委托对象,再把它缓存起来,不就可以多次复用了吗?因此,我们在计算表达式树时设法减少编译次数的解决方案可以分三步走:
- 提取表达式树中所有常量
- 从缓存中提取,或重新构造一个委托对象
- 把常量作为参数执行委托对象
第3步自不必多说,下面我们来分析前两步的做法。操作表达式树的传统手段还是使用ExpressionVisitor。首先,我们为第1步工作实现一个ConstantExtrator,如下:
public class ConstantExtractor : ExpressionVisitor
{ private List<object> m_constants; public List<object> Extract(Expression exp) { this.m_constants = new List<object>(); this.Visit(exp); return this.m_constants; } protected override Expression VisitConstant(ConstantExpression c) { this.m_constants.Add(c.Value); return c; } }
由于我们的目标仅仅是常量,因此只需要重写VisitConstant方法,并收集其Value即可。接着,我们便要将一个Expression编译为一个Delegate对象,为此我们实现一个WeakTypeDelegateGenerator,它自然也是一个ExpressionVisitor的子类:
public class WeakTypeDelegateGenerator : ExpressionVisitor
{ private List<ParameterExpression> m_parameters; public Delegate Generate(Expression exp) { this.m_parameters = new List<ParameterExpression>(); var body = this.Visit(exp); var lambda = Expression.Lambda(body, this.m_parameters.ToArray()); return lambda.Compile(); } protected override Expression VisitConstant(ConstantExpression c) { var p = Expression.Parameter(c.Type, "p" + this.m_parameters.Count); this.m_parameters.Add(p); return p; } }
WeakTypeDelegateGenerator会将所有的ConstantExpression转变成同类型的ParameterExpression,并进行收集。在访问了整个表达式树之后,将会把含有ParameterExpression的表达式使用LambdaExpression包装起来,再调用Compile方法进行编译,并将结果返回。
public class CacheEvaluator: IEvaluator
{ private static IExpressionCache<Delegate> s_cache = new HashedListCache<Delegate>(); private WeakTypeDelegateGenerator m_delegateGenerator = new WeakTypeDelegateGenerator(); private ConstantExtractor m_constantExtrator = new ConstantExtractor(); private IExpressionCache<Delegate> m_cache; private Func<Expression, Delegate> m_creatorDelegate; public CacheEvaluator() : this(s_cache) { } public CacheEvaluator(IExpressionCache<Delegate> cache) { this.m_cache = cache; this.m_creatorDelegate = (key) => this.m_delegateGenerator.Generate(key); } public object Eval(Expression exp) { if (exp.NodeType == ExpressionType.Constant) { return ((ConstantExpression)exp).Value; } var parameters = this.m_constantExtrator.Extract(exp); var func = this.m_cache.Get(exp, this.m_creatorDelegate); return func.DynamicInvoke(parameters.ToArray()); } }
IEvaluator接口中定义了Eval方法,目的是把一个Expression对象“计算”为一个常量。CacheEvaluator在实现Eval方法时利用了ConstantExtrator和WeakTypeDelegateGenerator,分别用于提取常量及构造委托对象。在得到委托对象之后,我们会使用DynamicInvoke方法,将常量作为参数进行调用。值得注意的是,这样做的必要条件之一,便是传入的常量与委托的参数顺序必须一致。由于ContstantExtrator和WeakTypeDelegateGenerator都是基于相同的ExpressionVisitor实现,因此它们对于同一表达式树的节点遍历顺序也完全相同,我们对此可以完全放心。
这里自然还离不开最重要的组件:缓存容器。把表达式树作为缓存容器的“键”并不像普通对象那么容易,为此我在博客上连载了7篇文章专门讨论了这个问题。这几篇文章提出了多种解决方案,并进行了对比和分析。最终,我们在这里选择了时间及空间上表现都比较优秀的HashedListCache。如果您有更好(或者在您的场景中表现更佳)的实现,您也可以在此替换默认的缓存容器。
下面我们来进行一个简单的试验,试验数据为运算符数量为1-3的四则运算表达式各10个,每个表达式分别计算1000次的结果。
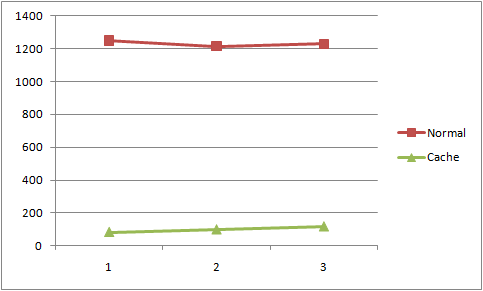
从上图中看来,传统方法对于每种长度的表达式计算耗时普遍超过了1.2秒,而启用了缓存的计算方式则将时间控制在了100毫秒左右。这无疑是一个显著的性能提升。
减少反射开销
在传统的调用方式中,编译操作占了95%的开销。而现在经过对编译操作的优化,总开销变成了原来的10%,这意味着目前编译和执行的差不多各占50%的时间。如果我们可以优化反射调用的过程,那么性能便可以得到进一步的提高。而且,目前的优化方式还有一个重要的问题,使我们不得不对其进行修改。您知道为什么在上面的示例中,只测试了最多3个运算符的四则运算表达式吗?这是因为目前的做法无法支持更多的运算符——其实是参数的数量。
在一个四则运算表达式中,常数的个数总是比操作符要多一个。也就是说,3个运算符的四则运算表达式,其中有4个常数。在目前的解决方案中,所有的常数都会被替换为参数。这就是现在的问题:LambdaExpression.Compile(ParameterExpression[])方法只支持最多4个参数。Compile方法还有一个重载允许我们指定一个新的委托类型,它要求匹配源表达式的参数个数,参数类型以及其返回值类型。如果没有指定特定的委托类型,框架便会选用以下委托对象中的一种作为编译目标:
namespace System { public delegate TResult Func<TResult>(); public delegate TResult Func<T, TResult>(T a); public delegate TResult Func<T1, T2, TResult>(T1 a1, T2 a2); public delegate TResult Func<T1, T2, T3, TResult>(T1 a1, T2 a2, T3 a3); public delegate TResult Func<T1, T2, T3, T4, TResult>(T1 a1, T2 a2, T3 a3, T4 a4); }
当参数数量超过4个的时候,Compile方法便会抛出异常(在.NET 4.0中则增加到16个)。如果要彻底解决这个问题,似乎唯一的方法便是根据需求,动态生成各种参数长度的委托类型。但是这么做大大增加了解决方案的复杂程度,对于性能优化也没有任何帮助。那么有没有什么办法,可以“统一”地处理任意签名的表达式呢?答案是肯定的,因为.NET框架中的“反射”特性给了我们一个很好的参考:
public class MethodInfo
{ public object Invoke(object instance, object[] parameters); }
- 一个List<object>对象,其中存放5,2,3三个元素。
- 一个新的表达式:(object)((int)p[0] + (int)p[1]) * (int)p[2]。其中p为List<object>类型的参数对象。
这样的“标准化”操作主要有两个好处:
- 只要是结构相同的表达式树,在“标准化”后得到的新表达式树则完全相同,这大大提高了缓存命中率。
- 无论何种表达式树,标准化后的结果永远只有一个List<object>参数,由此避免了常数过多而导致的编译失败。
我们得到了标准化之后的表达式树,便可以将其编译为相同的委托对象。这部分功能由DelegateGenerator类进行:
public class DelegateGenerator : ExpressionVisitor
{ private static readonly MethodInfo s_indexerInfo = typeof(List<object>).GetMethod("get_Item"); private int m_parameterCount; private ParameterExpression m_parametersExpression; public Func<List<object>, object> Generate(Expression exp) { this.m_parameterCount = 0; this.m_parametersExpression = Expression.Parameter(typeof(List<object>), "parameters"); var body = this.Visit(exp); // normalize
if (body.Type != typeof(object)) { body = Expression.Convert(body, typeof(object)); } var lambda = Expression.Lambda<Func<List<object>, object>>(body, this.m_parametersExpression); return lambda.Compile(); } protected override Expression VisitConstant(ConstantExpression c) { Expression exp = Expression.Call( this.m_parametersExpression, s_indexerInfo, Expression.Constant(this.m_parameterCount++)); return c.Type == typeof(object) ? exp : Expression.Convert(exp, c.Type); } }
与WeakTypeDelegateGenerator一样,DelegateGenerator也是拿ConstantExpression开刀。只不过后者并不是直接将其替换为新建的ParameterExpression,而是转化为对List<object>类型参数的元素下标访问(get_Item)——必要时再配合一次类型转换。Visit的过程也就是一次标准化的过程,最终得到的表达式树会被编译为一个接受List<object>作为参数,并返回object类型的委托对象。至于提取将表达式树的常量提取为List<object>类型的参数列表,已经由之前的ConstantExtractor实现了,我们直接使用即可。
将DelegateGenerator、ConstantExtractor及ExpressionCache三者加以组合,便可得出计算表达式树的新组件FastEvaluator:
public class FastEvaluator : IEvaluator
{ private static IExpressionCache<Func<List<object>, object>> s_cache = new HashedListCache<Func<List<object>, object>>(); private DelegateGenerator m_delegateGenerator = new DelegateGenerator(); private ConstantExtractor m_constantExtrator = new ConstantExtractor(); private IExpressionCache<Func<List<object>, object>> m_cache; private Func<Expression, Func<List<object>, object>> m_creatorDelegate; public FastEvaluator() : this(s_cache) { } public FastEvaluator(IExpressionCache<Func<List<object>, object>> cache) { this.m_cache = cache; this.m_creatorDelegate = (key) => this.m_delegateGenerator.Generate(key); } public object Eval(Expression exp) { if (exp.NodeType == ExpressionType.Constant) { return ((ConstantExpression)exp).Value; } var parameters = this.m_constantExtrator.Extract(exp); var func = this.m_cache.Get(exp, this.m_creatorDelegate); return func(parameters); } }
我们再进行一次简单的实验,将运算符数量为1-20的四则运算表达式各10个,分别计算1000次。三种实现耗时对比如下:
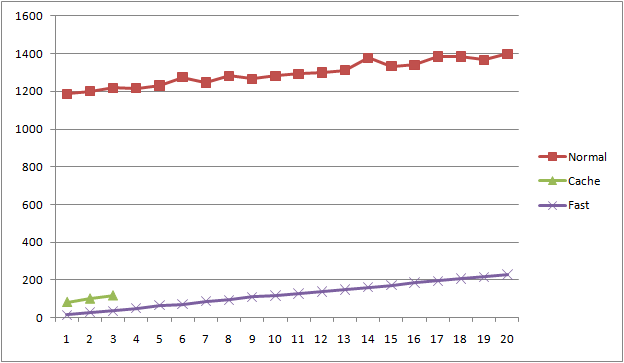
FastEvaluator的主要开销在于从ExpressionCache中提取数据,它随着表达式的长度线性增加。拥有n个运算符的四则运算表达式树,其常量节点的数量为n + 1,因此总结节点数量为2n + 1。根据我的个人经验,项目中所计算的表达式树的节点数量一般都在10个以内。如图所示,在这个数据范围内,FastEvaluator的计算耗时仅为传统方法的1/20,并且随着节点数量的减少,两者差距进一步增大。此外,由于节省了反射调用的开销,即使在CacheEvaluator可以正常工作的范围内(1-3个运算符),FastEvaluator相对前者也有明显的性能提升。
总结
表达式树拥有语义清晰,强类型等诸多优势,可以预见,越来越多的项目会采取这种方式来改进自己的API。在这种情况下,表达式树的计算对于程序性能的影响也会越来越大。本文提出了一种表达式树计算操作的优化方式,将不同表达式树“标准化”为几种有限的结构,并复用其编译结果。由于减少了编译操作和反射操作的次数,表达式计算所需开销大大降低。
本文所有代码都公布于MSDN Code Gallary中的FastLambda项目中,您可以根据需要随意修改使用。此外,FastLambda项目中还包含了可以将表达式树的多个常量部分进行简化的组件(如将5 + 2 + 3 * 4 * x简化为7 + 12 * x),这对于处理原本就包含ParameterExpression的表达式树非常有用(如编写LINQ Provider时)。如果您对此感兴趣,可以关注项目中的PartialEvaluator和FastPartialEvaluator类,它们的区别在于前者利用Evaluator,而后者利用FastEvaluator进行表达式树的局部计算。