图解HTTP
注:本文转自http://www.cnblogs.com/xing901022/p/4309840.html
这篇文章通俗易懂的讲解了网络中的HTTP协议,文章图文并茂,作者讲解的通俗易懂,很适合想学习HTTP协议的同学来看看,所以转载过来。
文章讲述的知识比较简单,深度有所不过,向更深的学习HTTP的同学可以配合这两篇博文:博文1,博文2以及《HTTP权威指南》来深入学习。
分隔线----------------------------------------------------------------------------------------------
本篇总结关于http的相关知识,主要内容参考如下导图:
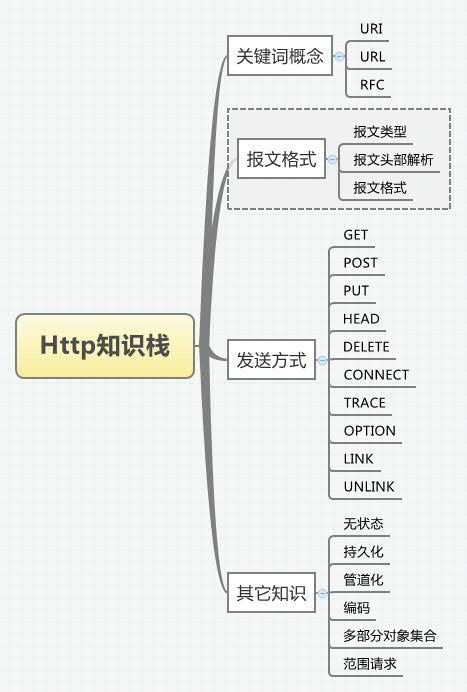
主要讲解的内容有:
1 URL与URI的区别。
2 请求报文与相应报文的内容。
3 GET与POST的区别。
4 http的cookie、持久化、管道化、多部分对象集合、范围请求等
后续会更新http其他的相关知识。
关键词概念
平时会经常接触到URL,他就是我们访问web的一个字符串地址,那么URI是什么呢?他们是什么关系呢?
先看看官方的解释:
URL:uniform resource location 统一资源定位符
URI:uniform resource identifier 统一资源标识符
这也就是说,URI是一种资源的标识;而URL也是一种URI,也是一种资源的标识,但它也指明了如何定位Locate到这个资源。
URI是一种抽象的资源标识,既可以是绝对的,也可以是相对的。但是URL是一种URI,它指明了定位的信息,必须是绝对的。
而我们平时所说的相对地址,仅仅是相对于另一个绝对地址而言。
RFC:reqeust for comments 征求修正意见书
RFC素有网络知识圣经之称,规定了网络中协议的基本内容。因此许多的不同系统的应用程序才可以互相访问。
报文格式
首先报文的格式如下:
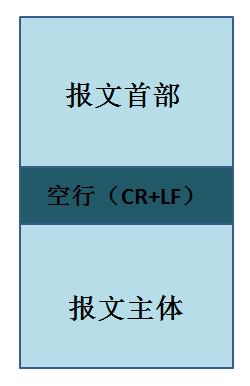
其中空行用于区分报文首部和报文主体内容,是由一个回车符和一个换行符组成。
无论是请求报文还是响应报文都需要有报文首部,当然报文主体有的请求报文是没有的。
一般来说,请求报文的格式如下:
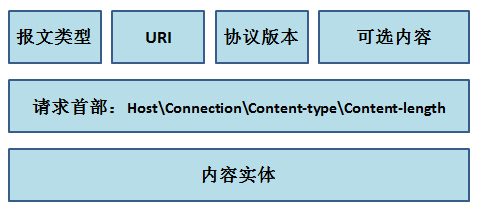
其中请求首部还包括其他的内容,不一一列举了。
响应报文格式如下:

下面我们看一下在不同的浏览器中http报文的内容:
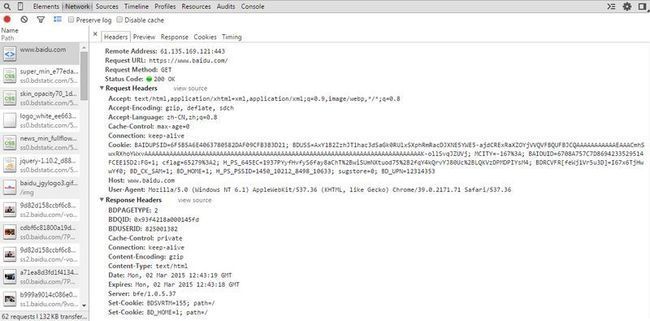
上图是chrome中http的内容,其中request headers描述了请求报文头部的内容,response headers描述了响应报文头部的内容。
其中最长使用的属性是:
1 URL, 即http访问的地址
2 request method, 报文的请求方式
3 status code, 状态码以及状态短语
4 Accept Encoding, 内容编码
5 Connection, 连接方式
6 Cookie, 添加的cookie内容
7 Host, 目标主机
8 User-Agent, 客户端浏览器的相关信息
9 Set-Cookie, 指定想要在Cookie中保存的内容
常用的属性内容就是上面这些。
在IE中捕获到的显示方式不同,但是内容都是相同的:
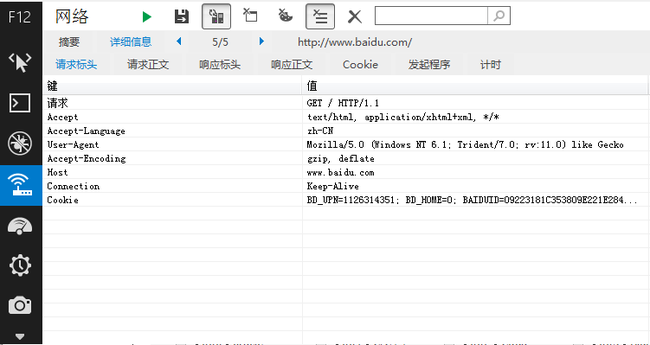
http请求方式
如何发送http有很多种方式,但是最常用的就是POST和GET。
其他的有些出于安全性的考虑一般都不建议使用。那么POST与GET有什么区别呢?
1 使用目标不同:
POST与GET都用于获取信息,但是GET方式仅仅是查询,并不对服务器上的内容产生任何作用结果;每次GET的内容都是相同的。
POST则常用于发送一定的内容进行某些修改操作。
2 大小不同:
由于不同的浏览器对URL的长度大小有一定的字符限制,因此由于GET方式放在URL的首部中,自然也跟着首先,但是具体的大小要依浏览器而定。
POST方式则是把内容放在报文内容中,因此只要报文的内容没有限制,它的大小就没有限制。(但是出于服务器压力的考虑,这个还是有所限制的,一般来说,是80kb或者100kb)。
3 安全性不同:
上面也说了GET是直接添加到URL后面的,直接就可以在URL中看到内容。
而POST是放在报文内部的,用户无法直接看到。
总的来说,GET用于获取某个内容,POST用于提交某种数据请求。
按照使用场景来说,一般用户注册的内容属于私密的,这应该使用POST方式;而针对某一内容的查询,为了快速的响应,可以使用GET方式。
无状态
由于http是一种无状态的协议,因此无论是客户端还是服务器都不记录http的相关信息。
这样设计一方面减轻了服务器端的负载,另一方面减小了http请求的开销。
但是针对某些特殊的场景,需要时刻记录用户的相关信息,这该如何处理呢?
Cookie恰好可以解决这个问题,Cookie的运行机制如下:
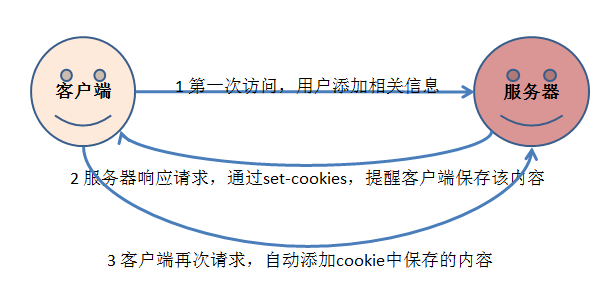
Cookie是一种由服务器端确定,并保存在客户端浏览器中的内容。这样,就不需要每次都添加用户的相关信息,请求会自动添加cookie中对应的内容。
持久化
正常在发送http时,都需要建立TCP的连接,再发送报文。

如果每次想要发送http报文都需要经过这个过程,那么时间大部分都会消耗在建立和断开连接的过程中。
因此http中使用了connection属性,用于指定连接的方式。

当设置成keep-alive,如上面所示的www.baidu.com的http头部信息所示,就会建立一条持久化的连接。
不需要每次都建立连接,再中断。
管道化
如果一个http请求,请求了大量的图片等大文件,那么其他的http请求怎么办呢?

不用怕,http可以一次发送多个http请求,然后等待响应连接。不需要排队等候,这样就加快了http的响应时间。
内容编码
由于某些报文的内容过大,因此在传输时,为了减少传输的时间,会采取一些压缩的措施。
例如上面的报文信息中,Accept-Encoding就定义了内容编码的格式:gzip
有下面几种方式:
gzip:GNU压缩格式
compress:UNIX系统的标准压缩格式
deflate:是一种同时使用了LZ77和哈弗曼编码的无损压缩格式
identity:不进行压缩
多部分对象集合
有的时候传输的内容,不仅仅是一些字符串,还有可能是一些图片,字符,音乐二进制等混杂的内容。
这就需要使用多部分对象集合,multipart,例如在使用java编写web上传文件的代码时,需要在form中指定form的编码格式。
设置form的enctype属性的值为multipart/form-data。
这是因为默认的情况下form使用的编码格式是:applicatin/x-www-form-urlencoded,这种编码格式会把所有的内容进行编码,不适合上传文件这种情况。
这两种编码格式的区别主要是:
multipart/form-data 会以控件为基准,编码form中的内容。
application/x-www-form-urlencoded 会把form中的内容编码成键值对的形式。
范围请求
有些场景下,http报文请求一些很大的图片,但是加载过程很慢。
比如我们登录一些大图片的网址,会发现有时候图片是一块一块加载的。

这就是因为设置了http请求的长度,这样就可以分块的加载资源文件。
在请求报文中使用Range属性,在响应报文中使用Content-Type属性都可以指定一定字节范围的http请求。
上一篇《图解HTTP 上》总结了HTTP的报文格式,发送方式,以及HTTP的一些使用。
本文再总结以下内容:
1 http状态码
2 http报文首部中的各字段
3 http中的身份验证
通过上篇粗略的描述,大体了解了http首部的概念。
其实请求报文与响应报文长得差不多,区别就在于请求报文与响应报文有一个各自的报文首部,和一个请求行和状态行。

可以看到,差别就在于
请求行中指定的是HTTP版本和请求的方式(GET\POST等)。
状态行中指定了HTTP版本和返回的状态码以及短语。
并且,请求首部与相应首部中拥有不同的属性,一会再说。
那么我们看看常见的状态码都有什么:
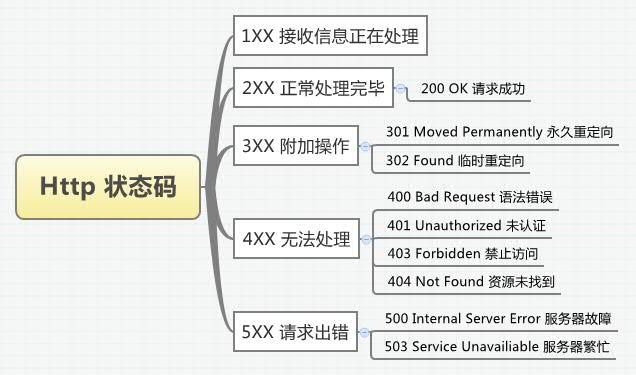
其中需要说明的是302,即临时重定向,这个比较常见。前两天我登百度的时候,突然发现前面的协议变成了https,我还纳闷,这两天在看又变回来了。原因就是当时访问www.baidu.com时默认使用Http,但是返回的302临时重定向和一个Location,我们的浏览器会自定跳转到这个返回的location:https://www.baidu.com中。由于现在改回来了,就不做截图说明了。
常见的一些状态码都在导图中列出来了,最常见的还是404:经常开发中遇到,就是因为访问的URL写错了。
再看看各首部字段中都有些什么内容吧。
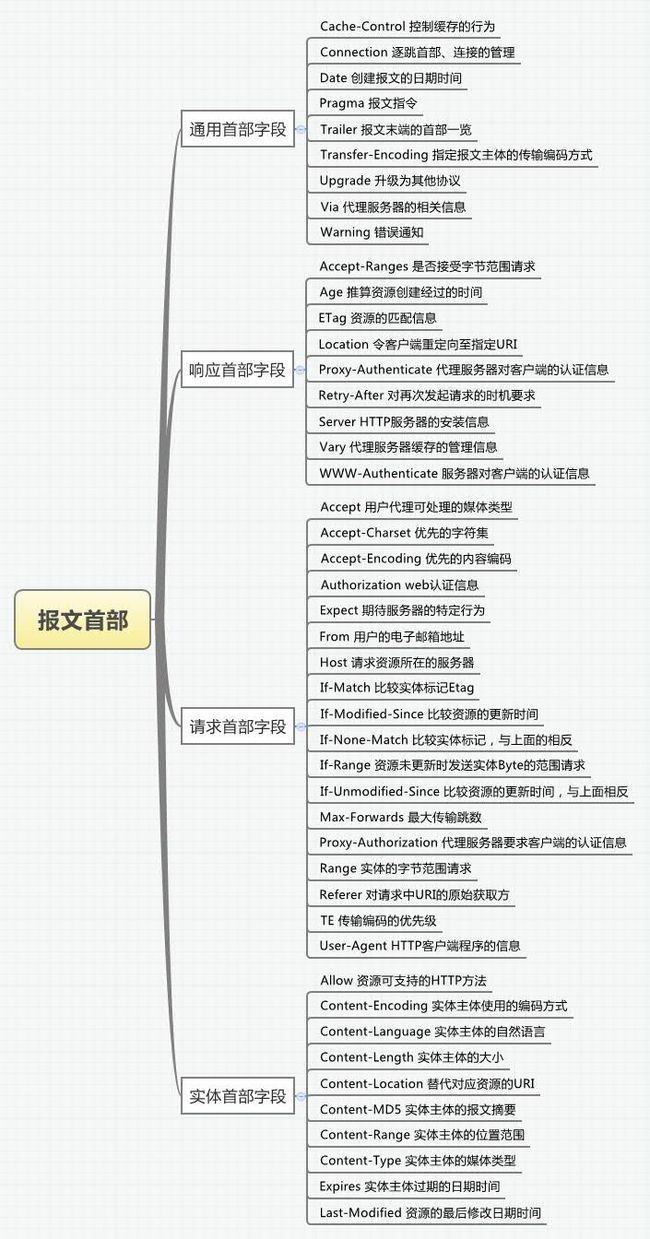
这里面学问最大的当然要是Cahce了,合理的使用Cache会让网站的访问达到登峰造极的地步,当然!我不会.....
这些属性,用到的时候再详细查看吧,这里也就不一一赘述了。
HTTP+加密+认证+完整性保护=HTTPS
为什么会出现https呢,多个s又有什么用呢!
http有几个缺点:
1 传输的时候使用明文,这显然会被不法者截取干一些见不得人的勾当。
2 没有认证机制,这样我们就可以伪造一些http访问,这显然会造成一些困扰。比如Jmeter就是典型的例子,伪造一大堆的http URL然后压力测试,这也就是DOS攻击的一种。
3 无法验证报文的完整性,比如一个http的报文已经被不法者截取并且篡改,服务器端也无法验证。
而HTTPS相当于套上SSL的HTTP,相当于穿上黄金甲的青铜圣斗士:


不仅仅是逼格的提升!
但是HTTPS也有它自身的缺点:
1 通信的速度变慢,由于需要加密,一个握手就多了好几个往返
2 对用户端的机器负载的增加。
因此,如果不是像金融支付这种需要高强度的安全性的场景,还是http比较好。
最后看一下HTTP中关于认证的概念
有一些网址或者服务需要用户的身份信息,因此需要随时知道这些消息,但是肯定不能每次都让用户输入用户密码,因此关于认证就有下面几种方式:
其中BASIC认证是最简单的认证,大致过程如下:
1 客户端访问某URL。
2 服务器端返回401状态码,提示用户输入用户名密码。
3 用户输入用户名密码,通过BASE64编码传输。
4 服务器通过认证,返回状态码200
通过上面的过程,就可以发现BASIC的问题:
1 仅仅通过BASE64编码,其实还是属于明文传输,安全性不高
2 有的浏览器不支持注销
鉴于上面BASIC的问题,DIGEST做了补充,它的过程与上面类似:
1 客户端访问
2 服务器端返回质询码
3 客户端发送响应码
这里通过随机的生成质询码来作为计算的一种方式,客户端依据这个质询码生成响应码,进行验证。
这样就弥补了明文传输用户密码的风险。
SSL客户端验证,这个比较普遍了!
像支付宝啊,邮政网银啊之类的,在登录时,都需要下载一个数字认证的东西,这个东西就属于一种SSL客户端的验证。
很显然它的缺点就是需要客户去手动的安装,这个对于一般的用户来说,代价有点高。
最后一种是应用最普遍的,通过表单记录用户的身份信息,可以使用cookie或者session的方式保存用户信息。
参考
[1] URL与URI的区别:http://www.cnblogs.com/gaojing/archive/2012/02/04/2413626.html
[2] POST与GET的区别:http://www.cnblogs.com/hyddd/archive/2009/03/31/1426026.html
[3] GET与POST的长度限制:http://blog.csdn.net/blueling51/article/details/6935901
参考
[1] wiki 302状态码:http://zh.wikipedia.org/wiki/HTTP_302
[2] http与https:http://19841026.iteye.com/blog/600615
[3] 状态码301 302:http://wlei1818.iteye.com/blog/1749456
[4] 《图解http》