线程池规模调优
线程池应该配置成多大?
先前一位朋友通过Skype问我关于运行在64位机器JVM集群一些问题,该集群每天会运行几次30万+个线程的任务。30万+个线程运行时,核心模块花了太多时间管理它们,导致应用程序极其不稳定。很明显,该应用程序需要一个线程池,从而保证可以杀死客户端,而不是放任客户端把整个应用程序搞崩溃。
上面的示例是比较极端的情况,但它强调了我们使用线程池的原因。尽管我们合理使用了线程池,仍可能由于数据丢失或交易失败惹恼用户。若我们的线程池定义得过大或过小,都有可能让应用程序完全瘫痪。大小合适的线程池允许运行尽可能多的请求,只要硬件和软件支持合理。换句话说,我们不想在有能力处理时让请求在队列中等待,也不想让运行的请求超出我们的管理能力。究竟线程池应该设置为多大合适呢?
若我们遵从“测量不猜”典故的话,就需要看一下与问题相关的技术,问一下可用的度量方法和我们系统获取它们的方法。我们需要使用一些数学方法。我们认为线程池是由队列连接的一个或多个服务提供程序,这样就知道这是可以用利特尔法则(Little’s law)解释的系统。让我们深入地了解一下。
利特尔法则(Little’s law)
利特尔法则(Little’s law)是说,一个系统请求数等于请求的到达率与平均每个单独请求花费的时间之乘积。整个法则在我们日常生活中很常见,令人吃惊的是直到上世纪50年代才提出来,然后到60年代才被证明。下面有个例子,是实际生活中利特尔法则的一种形式。你是否曾经排队,然后试图计算要等多长时间?你可能考虑排队的人数,然后快速算一下服务队列前面的人需要花多长时间。此时,你可以将两个值相乘,产生你在队列时间的估算。若不看队列的长度,你记住新人加入队列的频率,然后乘以服务时间,照样可以知道在队列中或被服务的人平均数。

有很多其它相似的游戏,同样适用于利特尔法则(Little’s law),可以回答其它的问题,如“在队列中等待服务的一个人平均所花时间?”,诸如此类。

图1 利特尔法则(Little’s law)
同样,我们可以使用利特尔法则(Little’s law)来判定线程池大小。我们只需计算请求到达率和请求处理的平均时间。然后,将上述值放到利特尔法则(Little’s law)就可以算出系统平均请求数。若请求数小于我们线程池的大小,就相应地减小线程池的大小。与之相反,如果请求数大于线程池大小,事情就有点复杂了。
当遇到有更多请求待处理的情况时,我们首先需要评估系统是否有足够的能力支持更大的线程池。准确评估的前提是,我们必须评估哪些资源会限制应用程序的扩展能力。在本文中,我们将假定是CPU,而在实际中可能是其它资源。最简单的情况是,我们有足够的空间增加线程池的大小。若没有的话,你不得不考虑其它选项,如软件调优、增加硬件,或者调优并增加硬件。
工作实例
让我们通过套接字发起和执行的请求典型工作流程来解释上述逻辑。执行过程中,需要获取数据或其他资源,直到结果从客户端返回。在我们的演示中,服务器通过执行一个标准工作单元来模拟负载,该工作单元在CPU敏感任务与解析数据库或其它外部数据源的数据来回切换。演示时,让我们通过计算无理数的小数位如Pi或2的平方根来模拟CPU密集型计算。Thread.sleep常用来模拟外部数据源的调用。 线程池将用于控制服务器上的活跃请求数。
为了监控java.util.concurrent (j.u.c)中线程池的选择情况,我们需要增加仪表盘。现实中,我们可以通过使用切面、ASM或者其它二进制检测技术检测使用j.u.c.ThreadPoolExecutor 而填加仪表盘。基于示例目的,我们没有上述技术,而是使用j.u.c.ThreadPoolExecutor 人工扩展来包含必要的监控。
public class InstrumentedThreadPoolExecutor extends ThreadPoolExecutor {
// Keep track of all of the request times
private final ConcurrentHashMap<runnable long ,> timeOfRequest =
new ConcurrentHashMap<>();
private final ThreadLocal<long> startTime = new ThreadLocal<long>();
private long lastArrivalTime;
// other variables are AtomicLongs and AtomicIntegers
@Override
protected void beforeExecute(Thread worker, Runnable task) {
super.beforeExecute(worker, task);
startTime.set(System.nanoTime());
}
@Override
protected void afterExecute(Runnable task, Throwable t) {
try {
totalServiceTime.addAndGet(System.nanoTime() - startTime.get());
totalPoolTime.addAndGet(startTime.get() - timeOfRequest.remove(task));
numberOfRequestsRetired.incrementAndGet();
} finally {
super.afterExecute(task, t);
}
}
@Override
public void execute(Runnable task) {
long now = System.nanoTime();
numberOfRequests.incrementAndGet();
synchronized (this) {
if (lastArrivalTime != 0L) {
aggregateInterRequestArrivalTime.addAndGet(now - lastArrivalTime);
}
lastArrivalTime = now;
timeOfRequest.put(task, now);
}
super.execute(task);
}
}
代码清单1.检测 ThreadPoolExecutor关键代码
上述代码是仪表盘代码的重要部分,我们的服务器将用在ThreadPoolExecutor 部分。重写三个关键执行器方法:beforeExecute,execute和afterExecute,进行数据收集,然后使用MXBean发布数据。让我们看看那每一个方法的工作方式。
执行器的execute方法用于传递请求给执行器。重写该方法可以收集所有的初始时序。我们也能利用该机会跟踪请求之间的时间间隔。由于我们是共享状态,所以该活动需要串行执行。最后委托给父执行器类。
正如名称所提示的,方法executeBefore会在请求执行前得以执行。此时,请求累计的所有时间只是在线程池的等待时间。通常被称为“死亡时间”。该方法执行结束后到afterExecute执行前被称为“服务时间”, 也是能使用利特尔法则(Little’s law)的时间。我们可以使用ThreadLocal存放起始时间。afterExecute 方法用于计算“线程池中时间”,“执行请求的时间,接着注册该”请求已经处理完毕”。
我们还需要一个MXBean来报告性能,该性能数据来自于用于检测ThreadPoolExecutor的收集计数器。这是MXBean ExecutorServiceMonitor 的工作(参考代码清单2)。
public class ExecutorServiceMonitor
implements ExecutorServiceMonitorMXBean {
public double getRequestPerSecondRetirementRate() {
return (double) getNumberOfRequestsRetired() /
fromNanoToSeconds(threadPool.getAggregateInterRequestArrivalTime());
}
public double getAverageServiceTime() {
return fromNanoToSeconds(threadPool.getTotalServiceTime()) /
(double)getNumberOfRequestsRetired();
}
public double getAverageTimeWaitingInPool() {
return fromNanoToSeconds(this.threadPool.getTotalPoolTime()) /
(double) this.getNumberOfRequestsRetired();
}
public double getAverageResponseTime() {
return this.getAverageServiceTime() +
this.getAverageTimeWaitingInPool();
}
public double getEstimatedAverageNumberOfActiveRequests() {
return getRequestPerSecondRetirementRate() * (getAverageServiceTime() +
getAverageTimeWaitingInPool());
}
public double getRatioOfDeadTimeToResponseTime() {
double poolTime = (double) this.threadPool.getTotalPoolTime();
return poolTime /
(poolTime + (double)threadPool.getTotalServiceTime());
}
public double v() {
return getEstimatedAverageNumberOfActiveRequests() /
(double) Runtime.getRuntime().availableProcessors();
}
}
代码清单2. ExecutorServiceMonitor类关键代码
在代码清单2中,我们可以看到给出问题答案的关键方法,队列是如何使用的? 注意getEstimatedAverageNumberOfActiveRequests()方法是利特尔法则(Little’s law)的实现。在该方法中,在每一个请求离开系统的退出率或观测率乘以服务于请求的平均时间等于系统平均请求数。另两个重要方法是getRatioOfDeadTimeToResponseTime()和getRatioOfDeadTimeToResponseTime()。让我们运行一些实验,看看这些数字相互之间的关系,以及与CPU利用率的关联。
实验1
第一个实验只是简单的提供整个过程的流程。小实验的配置是设置“服务器线程池大小”为1,并且仅有一个客户端如上所述的重复发出请求,持续30秒。
图2 1客户端,1服务器线程的结果
图2的视图来自于VisualVM MBean视图的快照和图形化CPU使用率监控器。VisualVM (http://visualvm.java.net/)是一个开源的工程,支持性能监控及分析的工具。工具使用方法超出了本文的范围。 简单的说,MBean 视图是一个可选的插件,让你访问所有注册于PlatformMBeansServer中的JMX MBeans 。
回到小实验,线程池大小是1。考虑到客户端循环特性,我们可能期望活跃请求的平均数是一个。但是,客户端重发请求需要花时间,因此上述值会小于1,0.98是在预期内的。
下一个值RatioOfDeadTimeToResponseTime 刚超过0.1%。考虑到目前只有一个主动请求与线程池的大小相匹配,上述值预期为0。但是,由于计时器位置和计时精度的偏差,该值很可能是非零值。该值相当小以至于我们可以忽略它的大小。CPU利用率告知我们core值小于1意味着有更多容量来处理更多请求。
实验2
在第二个实验中,我们设置线程池大小为1,而发起请求的并发客户端数目调升为10。不出所料,由于同一时刻只会有一个线程工作,所以CPU利用率并没有变化。然而,由于活跃请求数是10,允许客户端相互间不必等待,有可能我们会驳回更多请求。从这一点,我们可以得出结论,只有一个请求是活跃的,我们的队列长度是9。更多说明的是死亡时间占响应时间的比例接近于90%。该数字说明客户端看到的总响应时间的90%花费在线程等待上。如果我们想降低延迟,弹性空间最大的是死亡时间,我们有大量CPU冗余,所以通过增加线程池大小让请求得以处理是安全的做法。
图示 3 一个服务线程处理10个客户端请求的的结果
实验3
因为核心数字是4,所以让我们将线程池大小调整为4,运行同样的实验,。

图示4. 4个服务器线程处理10客户端请求的结果
我们再次看到平均请求数是10。不同的是,这次包括处理的请求数跳升过了2000。CPU也有一个接近于饱和的增长,但仍没有到100%。死亡时间占总响应时间的60%,还是比较健康的,这意味着仍有改善空间。我们是否可以继续增加线程池的大小来充分利用剩余CPU处理能力呢?
实验4
在最后的实验运行期间,我们把线程池配置为8个线程。从结果来看,与预期一致,平均请求数在10以下,死亡时间占比下降到19%以下,处理的请求数跳升为3621,很健康。CPU利用率接近100%。看起来在当前负载的情况下我们已经接近改善的极限了。这说明8是理想的线程池大小。我们能做出的另一个结论是,若需要减少更多的死亡时间,唯一方式是增加更多CPU或者改善应用程序的CPU效率。
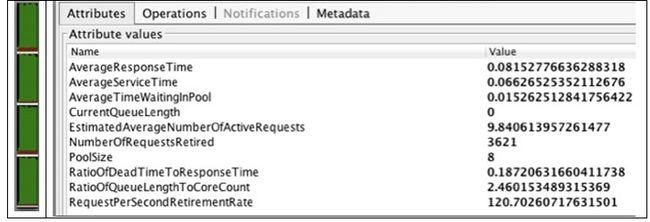
图示5. 8个服务器线程处理10个客户端请求的结果
理论与现实
上述实验可能会引起各种批评,其中之一是有些过度简化,大型应用程序不太可能只存在一个线程或者一个连接池。实际上,很多应用程序在通信技术中往往拥有多个连接池。例如,你的应用程序可能存在需Servlet处理的HTTP请求,JMS请求,以及JDBC连接池。在这种情况下,我们就需要用于servlet 引擎的线程池。也需要一个JMS和JDBC组件的连接池。 此时,需要做的一件事情是将它们全部看作独立的线程池。这意味着我们需要随着服务时间累计到达率。用利特尔法则(Little’s law)来累计分析系统,从而获得线程总数。接下来就是在不同线程组中进行总数划分。划分逻辑会使用一些策略,上述策略很可能受性能需求的影响。一种策略是基于硬件的个性化要求进行线程池大小平衡。 但是,可能给予WEB客户端的优先级高于JMS请求是重要的,因此我们需要在这个思路上平衡线程池大小。当然在重新权衡时,我们需要考虑不同硬件要求来调整每个线程池的大小。
另一个考虑是这个法则更关注于系统中的平均请求数。基于很多原因,我们可能先知道90%的队列长度。使用这个值将让我们有更大空间来处理到达率的自然波动。考虑到该数字会更复杂一些,更可行的是我们在平均值顶部增加20%的缓冲。这样做时,需要确保我们有足够容量处理大量线程。例如,在我们8个线程的实验中,CPU利用率已经到了极限,再增加更多线程很可能导致性能开始下降。最后,核心模块在管理线程时要比线程池有效的多。所以当我们猜测增加线程超过8个不一定是有效时,测算可以告诉我们确实需要为潜在可能超负荷的系统增加更多容量了。换句话说,超负荷运行(如压力测试)来看看线程数对于用户响应时间和吞吐率的影响。
结论
合适地配置线程池并不容易,但也不是超复杂的事情。背后的数学机理还是很好理解的,也很直观,因为它们一直存在于我们日常生活中。欠缺的工作是可以得到合理选择的测算(j.u.c.ExecutorService作为参考)。因为它更有点像实验化学一样精确科学,因此得到一个合适的配置还是有点繁琐,但是花点时间进行摸索,就能够降低处理超工作负荷运行而不稳定的系统的难度。
关于作者
 Kirk Pepperdine是一位独立顾问,专业从事Java性能调优工作。另外,她还为世界范围享有盛誉的性能调优研讨会发表文章。研讨会提出了性能调优方法学,该方法学已经提高了团队在Java性能疑难问题解决上的效率。作为2006年Java冠军,Kirk 已经写了为很多出版物写了关于性能的文章,也在很多会议——如Devoxx JavaONE——发表演讲。她帮助成立了Java性能调优网站,那是一个性能调优资源的知名站点。
Kirk Pepperdine是一位独立顾问,专业从事Java性能调优工作。另外,她还为世界范围享有盛誉的性能调优研讨会发表文章。研讨会提出了性能调优方法学,该方法学已经提高了团队在Java性能疑难问题解决上的效率。作为2006年Java冠军,Kirk 已经写了为很多出版物写了关于性能的文章,也在很多会议——如Devoxx JavaONE——发表演讲。她帮助成立了Java性能调优网站,那是一个性能调优资源的知名站点。
查看原文链接:Tuning the Size of Your Thread Pool