Smooks结构化事件流处理
概览
Smooks是一个开源的Java框架,用于处理“数据事件流”。它常常被认为是一个转换框架并以此被用于好几个产品和项目中,包括JBoss ESB(以及其它ESB)。然而究其核心,Smooks未提及“转换”或者其它相关的词汇。它的应用远不只这一点!
Smooks的工作是将结构化/层次化的数据流转变成“事件”流,然后交与“访问者逻辑(Visitor Logic)”进行分析,生成结果(可选的)。
源 ->结构化事件流(访问者逻辑) ->结果
那么,有哪些工作是这个工具可以完成,而sax和dom等工具不能完成的呢?鉴于Smooks构建于这些技术之上,所以简单的回答是“没有”。Smooks真正的价值在于能更方便地消费SAX和DOM(Smooks现在还不支持基于StAX的过滤器)。它提供了一个访问者API,以及一个配置模型,允许你轻易地将访问者逻辑的目标设定为具体的SAX事件(如果使用的是SAX过滤器)或DOM元素(如果使用的是DOM过滤器)。Smooks同时还以一种标准方式简化了对非XML源数据格式(EDI,CSV,JSON,Java等等)的消费,即由数据源产生的标准事件流变成了所有这些不同源数据格式的事实上的规范形式。这正是Smooks工作的关键!
使用Smooks的方式有两种,你可以使用其中之一或结合使用它们:
- 模式一:你可以完全投入到Smooks中,编写你自己的定制访问者逻辑事件处理器,将其用于处理一个数据源事件流中特定事件。使用这一模式,你必须熟悉核心的API。
- 模式二:你可以重用由Smooks发行版提供的开箱即用解决方案,其数目正在不断的增长中。在这种模式下,你只需要重用别人创建的组件即可,重新配置它们来处理你的数据源,例如,通过配置一些参数就可以由EDI数据源生成Java对象模型。
在这篇文章中,我们会快速地浏览一遍Smooks v1.1发行版提供的一些开箱即用的功能,即那些你不需要编写任何代码就可加以利用的功能(即模式二)。这包括:
- 多源数据格式:“轻易”地消费诸多流行的数据格式,包括XML,EDI,CSV,JSON和Java(是的,你可以以一种声明性的方式完成java到java的转换)。
- 转换:利用诸多选项消费由数据源产生的事件流,产生其它格式的结果(即,对源进行“转换”)。这包括能在过滤源数据流时对Smooks所捕获的数据模型应用FreeMarker和XSL模板。鉴于这些模板资源能被运用于源数据事件流内部的事件,因此它们能被用来执行“基于片断的转换(fragment based transforms)”。这意味着Smooks能被用于对数据源的片断执行转换,而不仅限于将数据源作为一个整体来施行转换。
- Java绑定:以一种标准方式由所支持的数据格式(即不仅限于XML)创建和生成Java对象模型/图。由EDI数据源 生成某对象模型的配置与由XML数据源或JSON数据源生成对象模型所进行的配置几乎一模一样。唯一区别在于绑定配置的“事件选择器(event selector)”取值不同。
- 大型消息处理:Smooks支持多种处理大型消息(GBs)的方式,它是通过基于SAX的过滤器完成的。由于综合了 基于片断转换、Java绑定,以及使用节点模型混合DOM和SAX模型所带来的能力,Smooks可以使用较低的内存空间处理大型消息。这些能力允许你执 行直接的1对1转换,同时也支持对大型消息数据流执行1对多的分解、转换和路由。
- 消息修饰:使用数据库数据修饰消息。这可以按片断来完成,即你可以按片断来管理在一个片断上的修饰。与此相关的一个用例是一个包含了消费者ID列表的消息在发往另一个流程前需要从数据库提取消费者地址和概要数据来丰富。
- 基于可扩展XSD的配置模型:从Smooks v1.1开始,你可以用自己的可重用定制访问者逻辑配置模型来扩展Smooks XSD配置名字空间。创建这些定制配置扩展只是一项简单的配置工作,这个工作极大的增进了这些重用组件的可用性。所有的现有Smooks预置组件都利用了这一工具。
处理不同数据格式
Smooks的一个关键特性就是能很容易地将其配置成用标准方式处理不同数据格式。这意味着如果你为Smooks开发了一些定制的访问者逻辑,这些代码可以立即用于处理任何受支持的数据格式,就仿佛是Smooks的预置组件(Java绑定等)一样。与之相关的,如果你为某种非预置支持的数据格式(例如 YAML)开发了一个定制的阅读器实现,你立即就具备了一个能力:使用所有可获得的预置访问者逻辑(例如,Java绑定组件)来处理该类型数据产生的数据事件。使这成为可能的原因在于Smooks组件处理的是标准化的事件流(即规范形式)。
Smooks提供对处理XML、EDI、CSV、JSON和Java对象的开箱即用的支持。默认情况下,Smooks将源数据流当作XML来读取(除非另有配置)。一个例外是Java对象源,它将被自动识别。对于其它所有数据格式类型,在Smooks配置里必须配置一个“阅读器”。下面是一个CSV阅读器的配置实例:
<xml version="1.0"?>
<smooks-resource-list xmlns="http://www.milyn.org/xsd/smooks-1.1.xsd"
xmlns:csv="http://www.milyn.org/xsd/smooks/csv-1.1.xsd">
<csv:reader fields="firstname,lastname,gender,age,country" separator="|" quote="'" skipLines="1" />
<smooks-resource-list>
EDI、JSON等阅读器的配置方式类似,都是通过唯一的配置名字空间进行的,比如<edi:reader></edi:reader>、<json:reader></json:reader>等。这些名字空间式的配置通过前面所讲到的基于可扩展的XSD配置模型得以实现。
配置好的阅读器负责将源数据流翻译成结构化的数据事件流(即规范形式——目前基于SAX2)。Smooks监听这一事件流,在合适的时候触发配置好的访问者逻辑(例如模板或绑定资源)。
执行一个Smooks过滤器流程
这很简单:
private Smooks smooks = new Smooks("/smooks-configs/customer-csv.xml");
public void transCustomerCSV(Reader csvSourceReader, Writer xmlResultWriter) {
smooks.filter(new StreamSource(csvSourceReader), new StreamResult(xmlResultWriter));
}
Smooks.filter()方法消费标准的javax.xml.transform.Source和javax.xml.transform.Result类型。Smooks项目同样定义了诸多新实现。
可视化非XML的结构化数据事件流
XML是最简单的“由源数据流产生事件流”的可视化方案。所以对于一个XML源而言,不存在真正的问题。而对非XML源(如CSV),事情就不那么简单了。该源一般与XML毫无共通之处。为了解决这个问题,Smooks提供了执行报告产生器(Execution Report Generator)工具。这一工具的一大用途就是帮助你对非XML数据源产生的事件流进行可视化,格式为XML。它同样是很好的调试工具。
这一报告产生工具被注入到了Smooks的执行上下文中:
private Smooks smooks = new Smooks("/smooks-configs/customer-csv.xml");
public void transCustomerCSV(Reader csvSourceReader, Writer xmlResultWriter) {
ExecutionContext executionContext = smooks.createExecutionContext();
executionContext.setEventListener(new HtmlReportGenerator("target/report/report.html"));
smooks.filter(new StreamSource(csvSourceReader), new StreamResult(xmlResultWriter), executionContext);
}
(在Smooks v1.1中)其输出是如下的一个HTML页面:
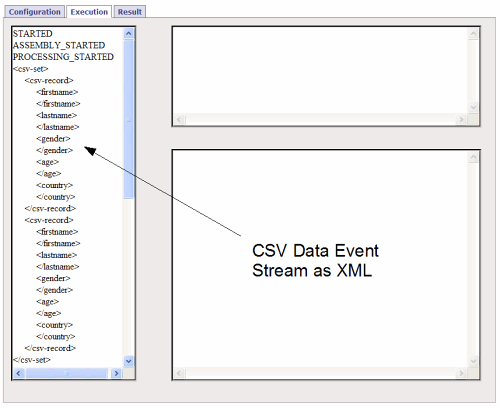
JBoss正在为Smooks开发一个Eclipse编辑器,它将作为JBoss Tools的一部分。这些工具将进一步简化可视化并操作非XML数据源事件流的过程。
拆分、转换与路由
这一用例很好地示范了如何组合几个Smooks功能来执行一个更复杂的任务。
继续CSV的例子,我们有以下的基本需求:
- CSV流可能会很大,因此我们需要使用SAX过滤器。
- 我们需要将每个CSV记录路由到一个JMS端点,格式是XML。这意味着我们需要拆分,转换和路由这些消息。
Smooks使用诸如XSL和FreeMarker这样的流行模板技术来对使用基于片断的转换提供支持。Smooks同时还提供了从源事件流(同样可能是非XML的)抓取DOM模型的能力,就算在使用SAX过滤器的情况下也能实现。有了这一功能,Smooks能够从源数据片断中构建“迷你”DOM模型并让其它Smooks资源(如FreeMarker模板和Groovy脚本资源)可以利用它们。采取这种方式,你能在保持以流式环境进行处理的同时,得到某些DOM处理模型的好处。对于此处所说的用例,我们将使用FreeMarker作为模板技术。
Smooks同样对将数据片断(由源数据片断所产生)路由到多个不同的端点类型(即JMS,文件或数据库)提供了开箱即用的支持。如同Smooks中的所有事物一样,这种能力总是可以被扩展或被其他用例重复使用,例如,可以轻而易举的插入一个定制的电子邮件访问者组件。JBoss ESB(以及其它的ESB)从运行于ESB之上的Smooks过滤流程内部提供定制的Smooks访问者组件来完成基于片断的ESB端点路由。
那么配置Smooks来完成上述用例就十分简单了:
<xml version="1.0"?>
<smooks-resource-list xmlns="http://www.milyn.org/xsd/smooks-1.1.xsd"
xmlns:csv="http://www.milyn.org/xsd/smooks/csv-1.1.xsd"
xmlns:jms="http://www.milyn.org/xsd/smooks/jms-routing-1.1.xsd"
xmlns:ftl="http://www.milyn.org/xsd/smooks/freemarker-1.1.xsd">
<params>
(1) <param name="stream.filter.type">SAXparam>
params>
(2) <csv:reader fields="firstname,lastname,gender,age,country" separator="|" quote="'" skipLines="1" />
(3) <resource-config selector="csv-record">
<resource>org.milyn.delivery.DomModelCreatorresource>
resource-config>
(4) <jms:router routeOnElement="csv-record" beanId="csv_record_as_xml" destination="xmlRecords.JMS.Queue" />
(5) <ftl:freemarker applyOnElement="csv-record">
(5.a) <ftl:template>/templates/csv_record_as_xml.ftlftl:template>
<ftl:use>
(5.b) <ftl:bindTo id="csv_record_as_xml"/>
<ftl:use>
<ftl:freemarker>
<smooks-resource-list>
- 配置(1)指示Smooks使用SAX过滤器。
- 配置(2)指示Smooks对所提供的配置使用CSV阅读器。
- 配置(3)指示Smooks为记录片断(参见上述执行报告)创建节点模型。每个记录的节点模型都将覆盖前一个片断产生的节点模型,所以任一已知时刻内存中都绝不会出现一个以上(作为一个节点模型)的CSV记录。
- 配置(4)指示Smooks在每个片断结束时将beanId“csv_record_as_xml”的内容路由到指定的JMS目的地。
- 配置(5)指示Smooks在每个片断结束时运用指定的FreeMarker模板(5.a)。该模板操作的结果绑定到beanId“csv_record_as_xml”(5.b)。
FreeMarker模板(5.a)也可以直接在Smooks配置中定义(在<ftl:template></ftl:template>元素内部),但在这个例子中我们将其定义在外部文件:
<#assign csvRecord = .vars["csv-record"]> <#-- special assignment because csv-record has a hyphen -->
<customer fname='${csvRecord.firstname}' lname='${csvRecord.lastname}' >
<gender>${csvRecord.gender}<gender>
<age>${csvRecord.age}<age>
<nationality>${csvRecord.country}<nationality>
<customer>
以上的FreeMarker模板引用了“csv-record”片断节点模型。(译注:由于原文编辑错误,导致HTML代码中虽有csv-record字样,但在展示到浏览器中却没有出现)
Java绑定
Smooks可以有效地被用来从任意所支持的源数据格式来生成Java对象模型。生成后的对象模型本身可以作为最终结果使用,也可以被用作模板操作的模型,即生成后的对象模型(存储在bean上下文里)可供模板技术(就像运用节点模型一样)使用。
再次继续我们的CSV实例。我们有一个消费者Java类,以及一个性别枚举类型(已省略getter/setter):
public class Customer {
private String firstName;
private String lastName;
private Gender gender;
private int age;
}
public enum Gender {
Male,
Female
}
从CSV流中生成一组这一消费者对象的Smooks配置会像是这样:
<xml version="1.0"?>
<smooks-resource-list xmlns="http://www.milyn.org/xsd/smooks-1.1.xsd"
xmlns:jb="http://www.milyn.org/xsd/smooks/javabean-1.1.xsd">
(1) <csv:reader fields="firstname,lastname,gender,age,country" separator="|" quote="'" skipLines="1" />
(2) <jb:bindings beanId="customerList" class="java.util.ArrayList" createOnElement="csv-set">
(2.a) <jb:wiring beanIdRef="customer" />
<jb:bindings>
(3) <jb:bindings beanId="customer" class="com.acme.Customer" createOnElement="csv-record">
<jb:value property="firstName" data="csv-record/firstName" />
<jb:value property="lastName" data="csv-record/lastName" />
<jb:value property="gender" data="csv-record/gender" decoder="Enum" >
(3.a) <jb:decodeParam name="enumType">com.acme.Genderjb:decodeParam>
<jb:value>
<jb:value property="age" data="csv-record/age" decoder="Integer" />
<jb:bindings>
<smooks-resource-list>
- 配置(1)指示Smooks对所提供的配置使用CSV阅读器。
- 配置(2)指示Smooks在遇到消息的开始时(该元素)创建一个ArrayList的实例,并将其绑定到beanId“customerList”的bean上下文中。我们想要将(2.a)实例的“customer”bean(3)装配到这一ArrayList。
- 配置(3)指示Smooks在遇到每一元素的开时时创建一个Customer类的实例。每个元素都定义了一个值绑定,从事件流中选择数据并将这一数据解码后的值绑定到当前Customer实例的指定属性中。配置(3.a)告诉Smooks对Gender属性使用Enum解码器。
当然,上述分拆、转换和路由用例的一个变体可能是将生成好的Customer对象路由到JMS队列,而不是一个FreeMarker模板所产生的XML:
<xml version="1.0"?>
<smooks-resource-list xmlns="http://www.milyn.org/xsd/smooks-1.1.xsd"
xmlns:csv="http://www.milyn.org/xsd/smooks/csv-1.1.xsd"
xmlns:jms="http://www.milyn.org/xsd/smooks/jms-routing-1.1.xsd"
xmlns:jb="http://www.milyn.org/xsd/smooks/javabean-1.1.xsd">
<params>
<param name="stream.filter.type">SAXparam>
params>
<csv:reader fields="firstname,lastname,gender,age,country" separator="|" quote="'" skipLines="1" />
<jms:router routeOnElement="csv-record" beanId="customer" destination="xmlRecords.JMS.Queue" />
<jb:bindings beanId="customer" class="com.acme.Customer" createOnElement="csv-record">
<jb:value property="firstName" data="csv-record/firstName" />
<jb:value property="lastName" data="csv-record/lastName" />
<jb:value property="gender" data="csv-record/gender" decoder="Enum" >
<jb:decodeParam name="enumType">com.acme.Genderjb:decodeParam>
jb:value>
<jb:value property="age" data="csv-record/age" decoder="Integer" />
jb:bindings>
<smooks-resource-list>
并且事情再复杂一点也没关系,可以对每个csv记录执行多路由操作,可以将Customer对象路由到JMS队列同时路由到FreeMarker产生的XML消息以归档。
性能
这一问题不可避免地一次次被提起。我们对Smooks进行了许多次的随机基准测试,以下的小节就是我们得到的普遍结果。
- Smooks核心过滤开销: Smooks内核使用SAX过滤器(使用Xerces作为XML阅读器)对XML进行处理,在没有配置访问者逻辑的情况下,较使用相同SAX解析器直接进行的SAX处理增加了大概百分之五到十的开销。
- Smooks模板开销: 在早期的Smooks版本中,为了对比“通过Smooks运用XSLT”和“单独使用XSLT”的开销,我们再次执行了一些基准测试以期对其进行确定。Smooks当时(以及现在)仅通过DOM过滤器来支持XSLT。与基于DOM的XSLT应用相比,Smooks增加了百分之五到十五的开销,准确值取决于XSL处理器。
- Smooks Java绑定开销:我们对于这一点的结果仅仅是基于跟一个主要的“XML到Java”开源绑定框架的对比。我们的发现是对于较小的消息(如小于10k),Smooks稍有些慢,但对于大一点的消息而言就快得多了。
今天,Smooks正被应用于好些个任务关键的生产环境。每当我们收到任何关于性能的询问时,其原因总是归咎于某种配置问题(比如使执行报告产生器 一直保持开启状态)。一旦将其解决,用户总会对性能非常满意。这虽然并非一个十分恰当的证据,但是它告诉了我们Smooks在性能方面不是“软蛋”。
总的来说,Smooks内核是相当高效的,较标准的基于SAX的XML处理而言只增加了相对较低的开销。在这以后,性能取决于所配置的访问者逻辑,它的目的和效率表现。
Smooks的下一步
Smooks v1.2的首要目标是提供更多处理EDI消息的工具。我们同样希望对某些更流行的EDI消息类型提供开箱即用的支持。
如前所述,Smooks开发的另一重要工作将会是继续JBoss Tools项目,构建一个Smooks的Eclipse编辑器。
总结
希望这一文章能让读者对Smooks及其核心功能有个更好的了解。我们希望人们能下载Smooks,瞧一瞧看一看,并提供些反馈。
查看英文原文:Structured Event Streaming with Smooks。