现代浏览器的工作原理【一】
序言
作为一个Web开发者,学习的浏览器操作的内部可以帮助您做出更好的决策,以及开发实践的最佳做法。 虽然这是一个相当漫长的文件,我们建议你花一些时间来挖掘研究, 我们保证你会很高兴你这样做的话。
简介
Web浏览器可能是最广泛使用的软件,在本文中,我将解释它们是如何在幕后工作的。当你在地址栏里敲入的goole.com,直到你在浏览器屏幕上看到谷歌网页,我们将看看这一过程中会发生什么。
目录
- 简介
- 我们所谈论的浏览器
- 浏览器的主要功能
- 浏览器的高层次结构
- 渲染引擎
- 渲染引擎
- 主要流程
- 主要流程实例
- 解析和DOM树建设
- 一般解析
- 文法
- 词法分析器 - 组合
- 翻译
- 解析示例
- 词汇和语法的正式定义
- 解析器的类型
- 自动生成解析器
- HTML解析器
- HTML语法定义
- 并非一个上下文无关文法
- HTML DTD
- DOM
- 解析算法
- 标记化算法
- 树构建算法
- 解析完成时的动作
- 浏览器允许误差
- CSS 解析
- WebKit的CSS解析器
- 脚本和样式表的处理顺序
- 脚本
- 投机性解析
- 样式表
- 一般解析
- 渲染树建设
- 渲染树与DOM树的关系
- 构建树的流程
- 样式的计算
- 共享样式数据
- 火狐规则树
- 结构拆分
- 使用规则树计算样式内容
- 一个简单的匹配操作规则
- 运用正确的级联秩序规则
- 样式表的级联顺序
- 特异性
- 排序规则
- 渐进的过程
- 布局
- 脏位系统
- 全局和增量布局
- 异步和同步布局
- 优化
- 布局过程
- 宽度计算
- 断行
- 绘制
- 全局和增量
- 绘制顺序
- 火狐显示列表
- Webkit的矩形存储
- 动态改变
- 渲染引擎的线程
- 事件循环
- CSS2的视觉模型
- 画布
- CSS盒模型
- 定位方案
- 盒类型
- 定位
- 相对
- 漂浮
- 绝对和固定
- 分层的代表性
- 参考资料
1.1 我们所谈论的浏览器
当今有五款主流的浏览器,分别是: Internet Explorer, Firefox, Safari, Chrome和Opera。将会给出开源浏览器的例子:Firefox, Chrome and Safari (部分开源)。根据2011年8月份的统计图表,Firefox, Safari和Chrome的总体使用份额占了将近60%,因此,时下的开源浏览器占浏览器业务的很大一部分比例。
1.2 浏览器的主要功能
浏览器的主要功能是:通过从服务器请求,并显示在浏览器窗口,以提供您选择的Web资源。资源通常是一个HTML文档,也可能是一个PDF文档、图片或者其它类型。资源的位置是由用户使用URI(统一资源标识符)指定的。
浏览器解释并显示HTML文件的方法是在HTML和CSS规范中指定的。这些规范是由W3C(万维网联盟)组织,它是为制定Web标准组织的机构。多年来的浏览器只是符合一个规范的一部分,并开发自己的扩展。这对网页的作者造成严重的兼容性问题。如今,大多数的浏览器或多或少符合规格。
浏览器的用户界面有很多共同之处。其中普通的用户界面元素是:
- 插入URI的地址栏
- 后退和前进按钮
- 书签选项
- 刷新和停止按钮,用于刷新和停止加载当前文档
- 主页按钮,可以让你到你的主页
1.3 浏览器的高层次结构
浏览器的主要组成如下:
1、用户界面----这包括地址栏,后退/前进按钮,书签菜单等,除主窗口外,在此可以看到所请求的页面浏览器中显示的每一个部分。
2、浏览器引擎----浏览器之间的界面行为和渲染引擎。
3、渲染引擎 ----负责显示所请求的内容。例如,如果请求的内容是HTML,它负责解析HTML和CSS,并在屏幕上显示的解析内容。
4、网络 ---- 网络调用,如用于HTTP请求。它具有平台无关的接口,并为每个平台下面实现的。
5、UI后端 ---- 用于绘制基本部件,如组合框和Windows控件。它暴露了一个通用的接口即不特定于某一平台的。它的下面使用的操作系统的用户界面的方法。
6、JavaScript解释器----用于解析和执行的JavaScript代码。
7、数据存储----这是一个持久层,浏览器保存在硬盘上的数据,例如:cookies。新的HTML规范(HTML5)定义“网络数据库”,这是一个完整的(虽然是轻量级)在浏览器中的数据库。

图1:浏览器的主要组成部分
重要的是要注意,Chrome不像大多数的浏览器只提供一个渲染引擎,它拥有多个实例的渲染引擎,为每个标签提供。每个选项卡是一个单独的进程。
第2章
渲染引擎
渲染引擎的责任... 渲染,就是所要求的内容浏览器屏幕上显示。
默认情况下,渲染引擎可以显示HTML和XML文档和图像。通过一个插件(或浏览器扩展),它可以显示其他类型。例如,使用PDF查看器中显示PDF格式插件。然而,在这一章中,我们将重点放在主要的用例:使用CSS格式化显示HTML和图像。
2.1 渲染引擎
我们的参考浏览器 - 火狐,Chrome和Safari是建立在两个渲染引擎之上。Firefox的使用Gecko - “自制的”Mozilla的渲染引擎;Safari和Chrome使用是Webkit。WebKit是一个开源渲染引擎,开始时为Linux平台的引擎,是由苹果公司修改后,以支持Mac和Windows。点击webkit.org查看详细内容。
2.2 主要流程
渲染引擎将开始从网络层获取所要求的文件的内容,这通常是在8K的块。
之后,这是渲染引擎的基本流程:

图2:渲染引擎的基本流程
渲染引擎开始解析HTML文档,转换树中的标签到DOM节点,它被称为“内容树”。它将解析样式数据,包括外部CSS文件和样式元素。样式信息与HTML中的视觉指示信息,将被用于创建另一个树 ---- 渲染树。
渲染树中包含的视觉属性,如颜色和尺寸的矩形。矩形被正确的顺序显示在屏幕上。
建设渲染树后,它经过一个“布局”的过程。这意味着给每个节点所应该出现在屏幕上的精确坐标。下一阶段是绘制 ---- 将遍历渲染树,每个节点将使用UI后端层来绘制。
重要的是要明白,这是一个渐进的过程。为了达到更好的用户体验,渲染引擎将努力尽可能快地在屏幕上显示内容。它在所有的HTML解析完成之前就开始建设和布局渲染树。部分内容将被解析和显示,而这个过程会一直持续,其余的内容则使来自网络。
2.3 主要流程实例
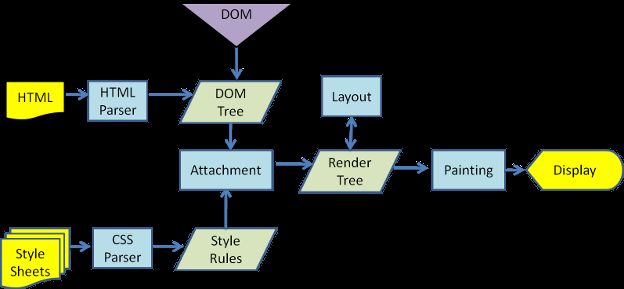
图3:Webkit主要流程
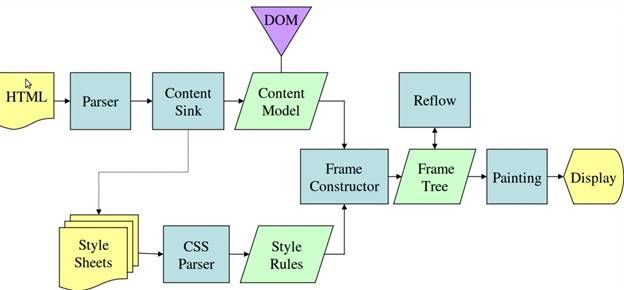
图4:Mozilla的Gecko渲染引擎的主要流程
从图3和4可以看到,尽管WebKit和Gecko的使用策略稍有不同,流程基本上是相同的的。
Gecko称视觉格式化的元素树为一个“框架树”。每个元素都是一个框架。Webkit的使用术语为“渲染树”,并且它由“渲染对象”组成。Webkit的使用术语“布局”来描述元素的放置,而Gecko称之为“回流”。“附件”是WebKit连接DOM节点和视觉信息来创建渲染树的术语。一个轻微的非语义的区别是,Gecko(Molla浏览器的排版引擎)有一个HTML和DOM树之间额外的层。这就是所谓的“内容汇”,是一个DOM元素的工厂。我们将讨论流程的每一部分。