蓝的成长记——追逐DBA(8):重拾SP报告,回忆oracle的STATSPACK实验
***********************************************声明***********************************************************************
原创作品,出自 “深蓝的blog” 博客,欢迎转载,转载时请务必注明出处,否则追究版权法律责任。
深蓝的blog:http://blog.csdn.net/huangyanlong/article/details/39803995
****************************************************************************************************************************
蓝的成长记——追逐DBA(8):重拾SP报告,回忆oracle的STATSPACK实验
**************************************************简介********************************************************************
个人在oracle路上的成长记录,其中以蓝自喻,分享成长中的情感、眼界与技术的变化与成长。敏感信息均以英文形式代替,不会泄露任何企业机密,纯为技术分享。
创作灵感源于对自己的自省和记录。若能对刚刚起步的库友起到些许的帮助或共鸣,欣慰不已。
欢迎拍砖,如有关技术细节表述有错误之处,请您留言或邮件([email protected])指明,不胜感激。
***************************************************************************************************************************
今天有些慵懒,整理过往学习中的一个实验,忆起oracle的SP报告。
——深蓝
**************************************************前言********************************************************************
这是一部个人记录的成长杂记,既然步入到oracle的这片蓝海,免不了一路的奔波与不断的考验。借由此杂记与库友们分享蓝的成长历程。
不知何时起对蓝有了一种说不出来的痴迷,痴迷其广博,痴迷其深邃,痴迷于近在咫尺却又遥不可及。
而又说不清从何时起,注视于oracle的红色耀眼,照亮出眼前的一道光,未知与迷惑在自己的脚下开始初露些许人生的充实与青春的回馈。
在追逐于DBA梦想的道路上步步前行。
***************************************************************************************************************************
时间有些久了,有些淡忘了SP报告的方法了,今天就利用闲暇的时光,重新拾起熟悉又陌生的STATSPACK报告的实验。
实验计划:
1、模拟某业务环境,制定快照计划;
2、生成初始状态数据库的statspack报告,分析数据;
3、调整数据缓冲区尺寸,生成 statspack报告,分析数据;
4、创建索引,生成statspack报告,分析数据;
5、使用绑定变量,生成 statspack报告,分析数据。
******************************************************************************************
步骤一:模拟业务环境,制定快照计划
目标:
1、关闭sga自动管理,调整DB cache、sharepool大小;
2、部署statspack;
3、部署模拟现场环境;
*****************************************************************************************
1、关闭sga自动管理,调整DB cache、sharepool大小,模拟现场环境
SQL> alter system set memory_target=0 scope=spfile; --11g中关闭内存自动管理 SQL> alter system set sga_target=0; SQL> alter system set db_cache_size=30m scope=spfile; --修改DB cache大小 SQL> alter system set shared_pool_size=70m scope=spfile; --修改share pool大小 SQL> startup force; --重启数据库 SQL> select component,current_size/1024/1024 from v$sga_dynamic_components; --查询修改后的缓冲区大小 COMPONENT CURRENT_SIZE/1024/1024 ---------------------------------------- ---------------------- shared pool 72 DEFAULT buffer cache 32
2、部署statspack
SQL> create tablespace tools datafile '/u01/app/oracle/oradata/PROD/disk6/tools01.dbf' size 300m; --创建statspack专用的tools表空间 SQL> @?/rdbms/admin/spcreate.sql --以sysdba身份执行spcreate脚本,用于创建spcreate对象 输入值设置: Enter value for perfstat_password: oracle Enter value for default_tablespace: tools Enter value for temporary_tablespace:回车 $ vi /u01/app/oracle/product/11.2.0/db_1/rdbms/admin/spauto.sql --设置自动快照时间,间隔30分钟生成一次快照 编辑如下: begin select instance_number into :instno from v$instance; dbms_job.submit(:jobno, 'statspack.snap;', trunc(sysdate+1/48,'MI'), 'trunc(SYSDATE+1/48,''MI'')', TRUE, :instno); commit; end; SQL>exec statspack.modify_statspack_parameter(i_snap_level=>7); --设置快照默认级别为7 SQL> conn scott/tiger SQL>CREATE SEQUENCE emp2_empno INCREMENT BY 1 START WITH 1 MAXVALUE 100000000 CACHE 10000 NOCYCLE; --执行创建序列语句
3、部署模拟现场环境
SQL> create table emp2 as select * from emp where 1=2; --创建实验表emp2,结构同emp表
SQL> alter table emp2 modify empno number(10);
SQL> alter table emp2 modify ename varchar(30);
SQL> alter table emp2 nologging; --为加快数据插入速度,关闭日志记录
--插入2千万行数据
SQL>begin
for i in 1..20000000 loop
insert into emp2
values (emp2_empno.nextval,'cuug'||i,'SALESMAN',7698,sysdate,1600,300,30);
if mod(i,1000)=0 then
commit;
end if;
end loop;
commit;
end;
/
SQL> alter table emp2 logging; --开启日志记录
$ vi script/bin/share_pool_sql_1.sh --编写查询的业务脚本
#!/bin/bash
CNT=1
while [ $CNT -lt 20000000 ]
do
sqlplus scott/tiger <<EOF
select * from emp2 where empno=$CNT;
exit
EOF
CNT=`expr $CNT + 1`
done
$ sh script/bin/share_pool_sql_1.sh --执行脚本,模拟“查询业务”
*****************************************************************************************
步骤二:生成原始statspack报告,分析报告
目标:
1、开启自动快照;
2、生成、导出报告;
3、关闭job;
4、分析报告。
*****************************************************************************************
1、开启自动快照
<span style="font-size:12px;">SQL> conn perfstat/oracle --开启快照及查询相关业务时,需要以perfstat身份登录
SQL>@?/rdbms/admin/spauto --执行脚本,开启自动快照</span>
2、生成报告
SQL> alter session set nls_date_format='yyyy-mm-dd hh24:mi:ss'; --设置查看格式,便于查询 SQL> select snap_id,snap_time,snap_level from stats$snapshot order by snap_time; --查询快照数量,是否满足生成statspack报告条件 SQL> @?/rdbms/admin/spreport --生成statspack报告 手工设置: Enter value for begin_snap:快照起点 Enter value for end_snap: 快照终点 Enter value for report_name:默认或指定报告名称 --使用x-manager将报告拷贝到windows主机
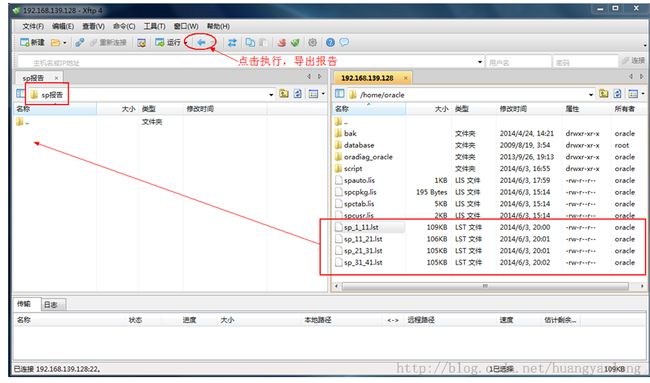
3、关闭job
SQL> select job,log_user,last_date,next_date from user_jobs; --查询需要关闭的job号
SQL> exec dbms_job.remove('21'); --将job号为21的任务删除
4、分析报告
关注点:
①buffer hit
②library hit
③Top 5 Timed Events
④造成最大物理读的sql
⑤Buffer Pool Advisory
⑥time model system stats
⑦Latch Sleep breakdown
① buffer hit、②library hit
| 时间 |
Buffer Hit(%) |
Library Hit(%) |
| 17:42:01~ 18:12:00 |
99.76 |
86.56 |
| 18:12:00 ~ 18:42:00 |
99.87 |
86.55 |
| 18:42:00~ 19:12:05 |
99.74 |
86.55 |
| 19:12:05~ 19:42:03 |
99.86 |
86.90 |
| avg |
99.81 |
86.64 |
分析: buffer hit高于95%符合数据正常性能标准。library hit低于95%,说明库缓存区命中率较低,需做相应调整。
③Top 5 Timed Events
| 时间 |
name |
waits |
Time (s) |
| 17:42:01~ 18:12:00 |
direct path read |
32,014,645 |
814 |
| db file sequential read |
1,697 |
6 |
|
| log file parallel write |
706 |
5 |
|
| 18:12:00 ~18:42:00 |
direct path read |
32,095,337 |
816 |
| log file parallel write |
898 |
5 |
|
| os thread startup |
50 |
9 |
|
| 18:42:00~ 19:12:05 |
direct path read |
32,438,303 |
816 |
| log file parallel write |
816 |
7 |
|
| control file parallel write |
493 |
1 |
|
| 19:12:05~ 19:42:03 |
direct path read |
32,255,547 |
816 |
| log file parallel write |
716 |
5 |
|
| control file parallel write |
491 |
1 |
分析:
direct path read的磁盘I/O产生量最大,db file sequential read、log file parallel write、control file parallel write也会产生部分磁盘I/O。
④查出造成物理读最大的前几个sql语句,产生执行计划
SQL>select sql_text from v$sql where disk_reads=(select max(disk_reads) from v$sql); --查询造成最大物理读的sql语句
……
select * from emp2 where empno=2215
select * from emp2 where empno=2270
select * from emp2 where empno=2208
……
SQL> set autotrace on;
SQL> set timing on;
SQL> select * from emp2 where empno=2208; --执行一条语句,查看执行计划,可以发现方式为全表扫描,在oracle11g下全表扫描时,库缓冲区将直接从磁盘中查询数据,磁盘I/O较大。cost值、physical read较大
<span style="font-family:SimSun;font-size:12px;"> EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
------------ --------------------- ------------------ ---------- ----------- ---------- ------------ --------------
2208 cuug2207 SALESMAN 7698 03-JUN-14 1600 300 30
</span>Elapsed: 00:00:00.94
Execution Plan
----------------------------------------------------------
Plan hash value: 2941272003
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 48 | 40046 (1)| 00:08:01 |
|* 1 | TABLE ACCESS FULL| EMP2 | 1 | 48 | 40046 (1)| 00:08:01 |
--------------------------------------------------------------------------
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
147357 consistent gets
147349 physical reads
0 redo size
869 bytes sent via SQL*Net to client
419 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
分析: 未发现造成物理读最大的sql。但发现查询语句为全表扫描,每条语句物理读都相对较大。
⑤Buffer Pool Advisory
| statistics |
||||||||
| Time |
P |
Size for Est (M) |
Size Factr |
Buffers (thousands) |
Est Phys Read Factr |
Estimated Phys Reads (thousands) |
Est Phys Read Time
|
Est % dbtime for Rds
|
| 17:42:01~ 18:12:00 |
D |
32 |
1.0 |
4 |
1.0 |
17 |
15 |
.3 |
| 18:12:00 ~18:42:00 |
D |
32 |
1.0 |
4 |
1.0 |
18 |
18 |
.2 |
| 18:42:00~ 19:12:05 |
D |
32 |
1.0 |
4 |
1.0 |
20 |
18 |
.2 |
| 19:12:05~ 19:42:03 |
D |
32 |
1.0 |
4 |
1.0 |
21 |
18 |
.1 |
| avg |
|
32 |
1.0 |
4 |
1.0 |
19 |
17.25 |
.2 |
| example |
||||||||
| Time :17:42:01~ 18:12:00 Est Phys Estimated Est Size for Size Buffers Read Phys Reads Est Phys % dbtime P Est (M) Factr (thousands) Factr (thousands) Read Time for Rds --- -------- ----- ------------ ------ -------------- ------------ -------- D 4 .1 0 1.2 21 20 .4 D 8 .3 1 1.1 19 17 .3 D 12 .4 1 1.1 18 16 .3 D 16 .5 2 1.0 18 16 .3 D 20 .6 2 1.0 18 15 .3 D 24 .8 3 1.0 17 15 .3 D 28 .9 3 1.0 17 15 .3 D 32 1.0 4 1.0 17 15 .3 D 36 1.1 4 1.0 17 15 .3 D 40 1.3 5 1.0 17 15 .3 D 44 1.4 5 1.0 17 15 .3 D 48 1.5 6 1.0 17 15 .3 D 52 1.6 6 1.0 17 15 .3 D 56 1.8 7 1.0 17 15 .3 D 60 1.9 7 1.0 17 15 .3 D 64 2.0 8 1.0 17 15 .3 |
||||||||
分析: 对比4个时间段中的最佳buffer pool建议及第一时间段下的详细趋势列表,buffer pool设置为32m并未影响到性能。
⑥time model system stats
time:17:42:01~ 18:12:00
Statistic Time (s) % DB time
----------------------------------- -------------------- ---------
sql execute elapsed time 1,772.4 99.3
DB CPU 1,747.0 97.9
parse time elapsed 62.4 3.5
hard parse elapsed time 58.0 3.3
connection management call elapsed 6.2 .3
PL/SQL execution elapsed time 6.1 .3
hard parse (sharing criteria) elaps 6.1 .3
hard parse (bind mismatch) elapsed 3.9 .2
PL/SQL compilation elapsed time 0.7 .0
repeated bind elapsed time 0.4 .0
sequence load elapsed time 0.1 .0
DB time 1,784.9
background elapsed time 26.5
background cpu time 3.7
time:18:12:00 ~18:42:00
Statistic Time (s) % DB time
----------------------------------- -------------------- ---------
sql execute elapsed time 2,549.1 99.5
DB CPU 1,752.4 68.4
parse time elapsed 60.2 2.4
hard parse elapsed time 57.0 2.2
PL/SQL execution elapsed time 6.2 .2
hard parse (sharing criteria) elaps 6.2 .2
connection management call elapsed 6.1 .2
hard parse (bind mismatch) elapsed 4.0 .2
PL/SQL compilation elapsed time 0.7 .0
repeated bind elapsed time 0.4 .0
sequence load elapsed time 0.1 .0
DB time 2,561.0
background elapsed time 21.2
background cpu time 1.9
time:18:42:00~ 19:12:05
Statistic Time (s) % DB time
----------------------------------- -------------------- ---------
sql execute elapsed time 3,548.9 99.6
DB CPU 1,751.7 49.2
parse time elapsed 37.7 1.1
hard parse elapsed time 34.9 1.0
connection management call elapsed 7.3 .2
hard parse (sharing criteria) elaps 3.6 .1
PL/SQL execution elapsed time 3.2 .1
hard parse (bind mismatch) elapsed 2.1 .1
PL/SQL compilation elapsed time 0.5 .0
repeated bind elapsed time 0.4 .0
sequence load elapsed time 0.1 .0
DB time 3,563.0
background elapsed time 30.8
background cpu time 3.7
time:19:12:05~ 19:42:03
Statistic Time (s) % DB time
----------------------------------- -------------------- ---------
sql execute elapsed time 3,541.3 99.7
DB CPU 1,746.9 49.2
parse time elapsed 37.9 1.1
hard parse elapsed time 35.2 1.0
connection management call elapsed 5.3 .2
hard parse (sharing criteria) elaps 3.7 .1
PL/SQL execution elapsed time 3.2 .1
hard parse (bind mismatch) elapsed 2.0 .1
PL/SQL compilation elapsed time 0.4 .0
repeated bind elapsed time 0.3 .0
sequence load elapsed time 0.1 .0
DB time 3,552.3
background elapsed time 22.0
background cpu time 1.4
分析: 对比4个时间段的time model system stats,发现有硬解析存在。
⑦Latch Sleep breakdown
time:17:42:01~ 18:12:00
Get Spin
Latch Name Requests Misses Sleeps Gets
-------------------------- --------------- ------------ ----------- -----------
qmn task queue latch 252 11 11 0
shared pool 669,111 7 7 0
space background task latc 1,114 6 6 0
cache buffers chains 1,415,617 1 1 0
JS Sh mem access 4 1 1 0
OS process allocation 4,354 1 1 0
FOB s.o list latch 7,177 1 1 0
messages 16,597 1 1 0
In memory undo latch 60,562 1 1 0
time:18:12:00 ~18:42:00
Get Spin
Latch Name Requests Misses Sleeps Gets
-------------------------- --------------- ------------ ----------- -----------
qmn task queue latch 260 13 13 0
space background task latc 1,109 4 4 0
SQL memory manager latch 3,316 1 1 0
JS Sh mem access 5 1 1 0
FOB s.o list latch 7,103 1 1 0
shared pool 666,763 1 1 0
time:18:42:00~ 19:12:05
Get Spin
Latch Name Requests Misses Sleeps Gets
-------------------------- --------------- ------------ ----------- -----------
qmn task queue latch 256 10 10 0
space background task latc 1,125 7 7 0
JS Sh mem access 6 2 2 0
shared pool 657,424 1 1 0
time:19:12:05~ 19:42:03
Get Spin
Latch Name Requests Misses Sleeps Gets
-------------------------- --------------- ------------ ----------- -----------
qmn task queue latch 256 10 10 0
space background task latc 1,109 5 5 0
JS Sh mem access 3 1 1 0
分析: 观察Latch Sleep breakdown,在4个时间段中出现有miss、sleep的次数没有明显突显趋势,对性能没产生根本性影响。
总结:
通过以上几点分析发现,影响性能的方面有: ① library hit 平均值为86.64%低于标准值95%; ② direct path read产生磁盘I/O量最大,生成执行计划后发现,查询数据的方式是全表扫描; ③ time model system stats信息显示出,业务中存在一定量的hard parse。
*****************************************************************************************
步骤三:调整数据缓冲区尺寸,生成statspack报告,分析数据
思路:
通过初始报告分析,需提高库缓冲区的命中率及加索引以改变全表扫描的查询方式。而加入索
引后,对于数据的查询,会由目前直接从磁盘读取变为通过数据缓冲区读取,I/O性能会得到提
高。会对数据缓冲区有一定要求,目前数据缓冲区设为32m,由于查询业务是通过全表扫描方式,
未能体现出缓冲区大小是否对性能有影响,但发现由于目前可分配内存资源较多,先将其调整
为64m,观察是否会对性能有影响,为之后继续调优做准备。
目标:
1、调整缓冲区尺寸;
2、生成statspack报告;
3、分析报告
*****************************************************************************************
1、调整缓冲区尺寸
SQL> alter system set db_cache_size=64m;
2、生成statspack报告
SQL> @?/rdbms/admin/spreport --重新生成statspack分析报告
3、分析报告
关注点:
①buffer hit
②library hit
③Top 5 Timed Events
④造成最大物理读的sql
⑤Buffer Pool Advisory
⑥time model system stats
⑦Latch Sleep breakdown
① buffer hit、②library hit
| 时间 |
Buffer Hit(%) |
Library Hit(%) |
| 05:52:00 ~ 06:22:03 |
99.99 |
86.34 |
| 06:22:03 ~ 06:52:02 |
99.96 |
86.73 |
| 06:52:02 ~ 07:22:01 |
99.99 |
86.34 |
| 07:22:01 ~ 07:52:04 |
100.00 |
86.56 |
| avg |
99.99 |
86.49 |
分析:
buffer hit由之前平均99.81提升为99.99%,性能还是有一定的提升。library hit平均为86.49%与之前平均86.64%没有显著变化,依然低于95%,说明库缓存区命中率仍然较低,需做进一步调整。
③Top 5 Timed Events
| 时间 |
name |
waits |
Time (s) |
| 05:52:00 ~06:22:03 |
direct path read |
17,621,085 |
750 |
| log file parallel write |
694 |
1 |
|
| control file parallel write |
523 |
1 |
|
| 06:22:03 ~06:52:02 |
direct path read |
17,661,174 |
754 |
| log file parallel write |
422 |
1 |
|
| control file parallel write |
523 |
1 |
|
| 06:52:02 ~ 07:22:01 |
direct path read |
17,596,117 |
752 |
| log file parallel write |
534 |
1 |
|
| control file parallel write |
522 |
1 |
|
| 07:22:01 ~ 07:52:04 |
direct path read |
17,644,217 |
754 |
| log file parallel write |
440 |
1 |
|
| control file parallel write |
524 |
1 |
|
| avg |
direct path read |
17,630,648 |
|
分析:
虽然direct path read的磁盘I/O产生量仍然为最大,但是数据比较于未调整缓冲区大小之前,由平均32,438,303下降为17,630,648,仍是有显著改善的。log file parallel write、control file parallel write仍会产生部分磁盘I/O。由此,可通过全表扫描的I/O等待事件高,预判出需要在经常访问的列上加索引,以通过减少磁盘I/O产生量最大的事件的I/O来降低磁盘的I/O,进而提升性能。
④查出造成物理读最大的前几个sql语句,产生执行计划
SQL>select sql_text from v$sql where disk_reads=(select max(disk_reads) from v$sql); --查询造成最大物理读的sql语句
……
select * from emp2 where empno=4009
select * from emp2 where empno=4012
select * from emp2 where empno=4023
……
SQL> set autotrace on;
SQL> set timing on;
SQL> select * from emp2 where empno=4009; --执行一条语句,查看执行计划,可以发现方式为全表扫描,磁盘I/O较大。cost值、physical read较大
<span style="font-size:12px;"> EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
------------ --------------------- ------------------ ---------- ----------- ---------- ------------ --------------
4009 cuug4008 SALESMAN 7698 03-JUN-14 1600 300 30
</span>Elapsed: 00:00:00.94
Execution Plan
----------------------------------------------------------
Plan hash value: 2941272003
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 48 | 40046 (1)| 00:08:01 |
|* 1 | TABLE ACCESS FULL| EMP2 | 1 | 48 | 40046 (1)| 00:08:01 |
--------------------------------------------------------------------------
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
147357 consistent gets
147349 physical reads
0 redo size
869 bytes sent via SQL*Net to client
419 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
分析: 未发现造成物理读最大的sql。但发现查询语句为全表扫描,每条语句物理读都相对较大,预判需对该表添加索引。
⑤Buffer Pool Advisory
| statistics |
||||||||
| Time |
P |
Size for Est (M) |
Size Factr |
Buffers (thousands) |
Est Phys Read Factr |
Estimated Phys Reads (thousands) |
Est Phys Read Time
|
Est % dbtime for Rds
|
| 05:52:00 ~06:22:03 |
D |
64 |
1.0 |
8 |
1.0 |
10 |
7 |
.0 |
| 06:22:03 ~06:52:02 |
D |
64 |
1.0 |
8 |
1.0 |
10 |
7 |
.0 |
| 06:22:03 ~06:52:02 |
D |
64 |
1.0 |
8 |
1.0 |
10 |
7 |
.0 |
| 07:22:01 ~ 07:52:04 |
D |
64 |
1.0 |
4 |
1.0 |
10 |
7 |
.0 |
| avg(now) |
|
64 |
1.0 |
6 |
1.0 |
10 |
7 |
.0 |
| avg (last) |
|
32 |
1.0 |
4 |
1.0 |
19 |
17.25 |
.2 |
| example |
||||||||
| Time : 05:52:00 ~06:22:03 Est Phys Estimated Est Size for Size Buffers Read Phys Reads Est Phys % dbtime P Est (M) Factr (thousands) Factr (thousands) Read Time for Rds --- -------- ----- ------------ ------ -------------- ------------ -------- D 4 .1 0 31.1 300 206 1.0 D 8 .1 1 14.4 139 95 .5 D 12 .2 1 6.5 62 43 .2 D 16 .3 2 4.4 43 29 .1 D 20 .3 2 3.0 29 20 .1 D 24 .4 3 2.4 23 16 .1 D 28 .4 3 1.8 17 12 .1 D 32 .5 4 1.7 16 11 .1 D 36 .6 4 1.5 15 10 .1 D 40 .6 5 1.3 13 9 .0 D 44 .7 5 1.0 10 7 .0 D 48 .8 6 1.0 10 7 .0 D 52 .8 6 1.0 10 7 .0 D 56 .9 7 1.0 10 7 .0 D 60 .9 7 1.0 10 7 .0 D 64 1.0 8 1.0 10 7 .0 D 68 1.1 8 1.0 10 7 .0 D 72 1.1 9 1.0 10 7 .0 D 76 1.2 9 1.0 10 7 .0 D 80 1.3 10 1.0 10 7 .0 |
||||||||
分析: 对比4个时间段中的最佳buffer pool建议,再与未调整缓冲区之前比较,虽然最佳尺寸设置建议均为人为指定的值(第一次为32m、第二次为64m)。但当缓冲区由32m调高到64m时,缓冲区的使用平均由4000升高到6000,预估的物理读由之前平均为19000降低到10000,预估的物理读时间由原来的平均17.25降低到7。通过物理读的下降,发现将缓冲区调大,对I/O性能有明显的改善。
⑥time model system stats
time:05:52:00 ~06:22:03
Statistic Time (s) % DB time
----------------------------------- -------------------- ---------
sql execute elapsed time 1,767.9 99.3
DB CPU 1,751.9 98.4
parse time elapsed 56.9 3.2
hard parse elapsed time 53.4 3.0
hard parse (sharing criteria) elaps 6.8 .4
connection management call elapsed 6.6 .4
PL/SQL execution elapsed time 5.9 .3
hard parse (bind mismatch) elapsed 3.9 .2
PL/SQL compilation elapsed time 0.6 .0
repeated bind elapsed time 0.4 .0
sequence load elapsed time 0.1 .0
DB time 1,780.4
background elapsed time 12.4
background cpu time 1.6
time:06:22:03 ~06:52:02
Statistic Time (s) % DB time
----------------------------------- -------------------- ---------
sql execute elapsed time 1,756.0 99.2
DB CPU 1,749.6 98.9
parse time elapsed 48.7 2.8
hard parse elapsed time 45.0 2.5
connection management call elapsed 6.4 .4
hard parse (sharing criteria) elaps 6.0 .3
PL/SQL execution elapsed time 5.5 .3
hard parse (bind mismatch) elapsed 4.3 .2
PL/SQL compilation elapsed time 0.8 .0
repeated bind elapsed time 0.4 .0
sequence load elapsed time 0.1 .0
DB time 1,769.8
background elapsed time 10.8
background cpu time 1.6
time:06:52:02~07:22:01
Statistic Time (s) % DB time
----------------------------------- -------------------- ---------
sql execute elapsed time 1,755.9 99.3
DB CPU 1,745.2 98.7
parse time elapsed 49.7 2.8
hard parse elapsed time 45.7 2.6
connection management call elapsed 7.3 .4
PL/SQL execution elapsed time 6.1 .3
hard parse (sharing criteria) elaps 6.1 .3
hard parse (bind mismatch) elapsed 3.5 .2
PL/SQL compilation elapsed time 1.4 .1
repeated bind elapsed time 0.5 .0
sequence load elapsed time 0.1 .0
DB time 1,767.4
background elapsed time 16.3
background cpu time 3.4
time:07:22:01 ~ 07:52:04
Statistic Time (s) % DB time
----------------------------------- -------------------- ---------
sql execute elapsed time 1,767.9 99.3
DB CPU 1,751.9 98.4
parse time elapsed 56.9 3.2
hard parse elapsed time 53.4 3.0
hard parse (sharing criteria) elaps 6.8 .4
connection management call elapsed 6.6 .4
PL/SQL execution elapsed time 5.9 .3
hard parse (bind mismatch) elapsed 3.9 .2
PL/SQL compilation elapsed time 0.6 .0
repeated bind elapsed time 0.4 .0
sequence load elapsed time 0.1 .0
DB time 1,780.4
background elapsed time 12.4
background cpu time 1.6
分析: 对比4个时间段的time model system stats,发现硬解析存在,较之前平均为46.28上升为平均的49.38,近似没有太大变化,但其值已经占据大部分解析,需要进一步分析对其优化,应重点关注。
⑦Latch Sleep breakdown
time:05:52:00 ~06:22:03
Get Spin
Latch Name Requests Misses Sleeps Gets
-------------------------- --------------- ------------ ----------- -----------
qmn task queue latch 252 9 9 0
shared pool 646,354 2 2 0
redo allocation 1,831 1 1 0
JS Sh mem access 5 1 1 0
FOB s.o list latch 7,824 1 1 0
SQL memory manager latch 3,271 1 1 0
time:06:22:03 ~06:52:02
Get Spin
Latch Name Requests Misses Sleeps Gets
-------------------------- --------------- ------------ ----------- -----------
shared pool 598,719 4 4 0
qmn task queue latch 260 3 3 0
shared pool simulator 94,784 2 2 0
row cache objects 807,801 2 2 0
JS Sh mem access 3 1 1 0
time:06:52:02~07:22:01
Get Spin
Latch Name Requests Misses Sleeps Gets
-------------------------- --------------- ------------ ----------- -----------
shared pool 598,719 4 4 0
qmn task queue latch 260 3 3 0
shared pool simulator 94,784 2 2 0
row cache objects 807,801 2 2 0
JS Sh mem access 3 1 1 0
time:07:22:01 ~ 07:52:04
Latch Name Requests Misses Sleeps Gets
-------------------------- --------------- ------------ ----------- -----------
qmn task queue latch 252 9 9 0
shared pool 646,354 2 2 0
redo allocation 1,831 1 1 0
JS Sh mem access 5 1 1 0
FOB s.o list latch 7,824 1 1 0
SQL memory manager latch 3,271 1 1 0
分析: 观察“Latch Sleep breakdown”,比较调整之前,“qmn task queue latch”在4个时间段中出现有miss、sleep的次数稍有增加,其余项很少有misss、sleeps。
总结:
通过以上几点分析发现,将缓冲区调大后,性能有所提升,体现在如下:
① buffer hit由之前平均99.81提高为99.99%,稍有提升;
② direct path read磁盘I/O产生量虽然仍为产生I/O的最大来源,但比较于之前I/O量,由平
均32,438,303下降为17,596,117,I/O性能上已有显著改善;
③ Buffer Pool Advisory中发现,预估的物理读由之前平均为19000降低到10000,物理读的下
降说明了性能的提升;
通过分析后,性能上仍存在需改善的方面,如下:
① library hit仍低于95%,库缓冲区命中率较低;
② 以全表扫描的方式查询数据,direct path read产生较多的磁盘I/O;
③ 仍存在部分硬解析。
*****************************************************************************************
步骤四:创建索引,生成statspack报告,分析数据
目标:
1、创建索引;
2、生成、导出报告;
3、分析报告。
*****************************************************************************************
1、创建索引
SQL> create index ind_empno on emp2(empno); --添加索引 $ sh script/bin/share_pool_sql_1.sh; --执行查询业务
2、生成报告
SQL>@?/rdbms/admin/spauto --开启自动快照 SQL> @?/rdbms/admin/spreport --生成报告
3、分析报告
关注点:
①buffer hit
②library hit
③Top 5 Timed Events
④造成最大物理读的sql
⑤Buffer Pool Advisory
⑥time model system stats
⑦Latch Sleep breakdown
① buffer hit、②library hit
| 时间 |
Buffer Hit(%) |
Library Hit(%) |
| 12:43:00 ~ 12:58:02 |
99.98 |
89.65 |
| 12:58:02 ~ 13:13:03 |
99.98 |
88.92 |
| 13:13:03 ~ 13:28:03 |
99.96 |
90.62 |
| 13:28:03 ~ 13:43:05 |
99.97 |
90.56 |
| avg(now) |
99.97 |
89.94 |
| avg(last) |
99.99 |
86.49 |
分析:
buffer hit较上次变化不大,其值已满足高于90%的标准。library hit由之前平均86.49%提高为平均89.94%,稍有提升,但仍低于95%标准值,说明库缓存区命中率仍然较低,仍需做进一步调整。
③Top 5 Timed Events
| 时间 |
name |
waits |
Time (s) |
| 12:43:00 ~12:58:02 |
Disk file operations I/O |
18,849 |
1 |
| log file parallel write |
280 |
1 |
|
| control file parallel write |
251 |
1 |
|
| 12:58:02 ~13:13:03 |
Disk file operations I/O |
18,641 |
1 |
| log file parallel write |
412 |
1 |
|
| cursor: pin S wait on X |
35 |
2 |
|
| 13:13:03 ~13:28:03 |
Disk file operations I/O |
19,002 |
1 |
| log file parallel write |
190 |
1 |
|
| control file parallel write |
251 |
1 |
|
| 13:28:03 ~13:43:05 |
Disk file operations I/O |
19,146 |
1 |
| log file parallel write |
224 |
1 |
|
| control file parallel write |
250 |
0 |
|
| avg |
Disk file operations I/O |
18,909 |
|
分析:
对于磁盘I/O的产生已由direct path read变为了Disk file operations,说明由全表扫描变成走索引了,waits值由之前平均17,630,648下降为18,909,性能上实现了显著的提高。并且log file parallel write、control file parallel write产生的部分磁盘I/O也相应下降了。由此,可以看出通过加索引显著地降低了I/O,提升了性能。
④查出造成物理读最大的前几个sql语句,产生执行计划
SQL>select sql_text from v$sql where disk_reads=(select max(disk_reads) from v$sql); --查询造成最大物理读的sql语句 SQL_ID SQL_TEXT ------------- ---------------------------------------- 3wmbtk9vt5pbq SELECT * FROM EMP3 WHERE EMPNO=:B1 Plan hash value: 2607329332 ----------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ----------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 41 | 4 (0)| 00:00:01 | | 1 | TABLE ACCESS BY INDEX ROWID| EMP3 | 1 | 41 | 4 (0)| 00:00:01 | |* 2 | INDEX RANGE SCAN | IND_EMPNO | 1 | | 3 (0)| 00:00:01 | -----------------------------------------------------------------------------------------
分析:
通过对比物理读最大的sql的执行计划,发现有相同的执行计划,预判可以使用绑定变量以提高性能。
⑤Buffer Pool Advisory
| statistics |
||||||||
| Time |
P |
Size for Est (M) |
Size Factr |
Buffers (thousands) |
Est Phys Read Factr |
Estimated Phys Reads (thousands) |
Est Phys Read Time
|
Est % dbtime for Rds
|
| 12:43:00 ~12:58:02 |
D |
64 |
1.0 |
8 |
1.0 |
10 |
7 |
.1 |
| 12:58:02 ~13:13:03 |
D |
64 |
1.0 |
8 |
1.0 |
10 |
7 |
.0 |
| 13:13:03 ~13:28:03 |
D |
64 |
1.0 |
8 |
1.0 |
10 |
8 |
.1 |
| 13:28:03 ~13:43:05 |
D |
64 |
1.0 |
4 |
1.0 |
10 |
8 |
.1 |
| avg(last) |
|
64 |
1.0 |
6 |
1.0 |
10 |
7 |
.0 |
| avg (now) |
|
64 |
1.0 |
7 |
1.0 |
10 |
7.5 |
.0 |
| example |
||||||||
| Time : 12:43:00 ~12:58:02 Est Phys Estimated Est Size for Size Buffers Read Phys Reads Est Phys % dbtime P Est (M) Factr (thousands) Factr (thousands) Read Time for Rds --- -------- ----- ------------ ------ -------------- ------------ -------- D 4 .1 0 21.6 207 196 2.5 D 8 .1 1 9.7 93 87 1.1 D 12 .2 1 4.7 45 41 .5 D 16 .3 2 3.2 31 27 .4 D 20 .3 2 2.0 19 16 .2 D 24 .4 3 1.7 16 13 .2 D 28 .4 3 1.5 14 11 .1 D 32 .5 4 1.3 12 9 .1 D 36 .6 4 1.1 11 8 .1 D 40 .6 5 1.1 11 8 .1 D 44 .7 5 1.1 10 7 .1 D 48 .8 6 1.0 10 7 .1 D 52 .8 6 1.0 10 7 .1 D 56 .9 7 1.0 10 7 .1 D 60 .9 7 1.0 10 7 .1 D 64 1.0 8 1.0 10 7 .1 D 68 1.1 8 1.0 10 7 .1 D 72 1.1 9 1.0 10 7 .1 D 76 1.2 9 1.0 10 7 .1 D 80 1.3 10 1.0 10 7 .1 |
||||||||
分析:
对比4个时间段中的最佳buffer pool建议,各指标数值近似与调整前持平。
⑥time model system stats
time:12:43:00 ~12:58:02
Statistic Time (s) % DB time
----------------------------------- -------------------- ---------
DB CPU 393.3 159.2
parse time elapsed 84.6 34.3
sql execute elapsed time 67.0 27.1
hard parse elapsed time 65.3 26.5
connection management call elapsed 51.8 21.0
PL/SQL execution elapsed time 7.3 3.0
hard parse (sharing criteria) elaps 3.8 1.6
hard parse (bind mismatch) elapsed 2.7 1.1
PL/SQL compilation elapsed time 1.1 .5
repeated bind elapsed time 0.3 .1
sequence load elapsed time 0.3 .1
DB time 247.0
background elapsed time 7.7
background cpu time 2.2
time:12:58:02 ~13:13:03
Statistic Time (s) % DB time
----------------------------------- -------------------- ---------
DB CPU 395.9 151.5
parse time elapsed 100.5 38.5
sql execute elapsed time 83.8 32.1
hard parse elapsed time 80.5 30.8
connection management call elapsed 51.8 19.8
PL/SQL execution elapsed time 7.6 2.9
hard parse (sharing criteria) elaps 6.0 2.3
hard parse (bind mismatch) elapsed 3.1 1.2
PL/SQL compilation elapsed time 2.3 .9
sequence load elapsed time 0.7 .3
repeated bind elapsed time 0.5 .2
DB time 261.2
background elapsed time 9.8
background cpu time 4.3
time:13:13:03 ~13:28:03
Statistic Time (s) % DB time
----------------------------------- -------------------- ---------
DB CPU 378.0 171.7
parse time elapsed 62.6 28.4
connection management call elapsed 47.4 21.6
sql execute elapsed time 44.8 20.4
hard parse elapsed time 43.3 19.6
PL/SQL execution elapsed time 6.7 3.0
hard parse (sharing criteria) elaps 2.5 1.1
hard parse (bind mismatch) elapsed 1.8 .8
PL/SQL compilation elapsed time 0.4 .2
repeated bind elapsed time 0.1 .0
sequence load elapsed time 0.1 .0
DB time 220.1
background elapsed time 5.2
background cpu time 0.8
time:13:28:03 ~13:43:05
Statistic Time (s) % DB time
----------------------------------- -------------------- ---------
DB CPU 375.8 170.5
parse time elapsed 62.4 28.3
connection management call elapsed 47.5 21.5
sql execute elapsed time 45.7 20.7
hard parse elapsed time 43.2 19.6
PL/SQL execution elapsed time 6.9 3.1
hard parse (sharing criteria) elaps 2.3 1.1
hard parse (bind mismatch) elapsed 1.7 .8
PL/SQL compilation elapsed time 0.4 .2
repeated bind elapsed time 0.1 .1
sequence load elapsed time 0.0 .0
DB time 220.5
background elapsed time 5.7
background cpu time 1.1
分析:
对比4个时间段的time model system stats,发现仍有硬解析存在,较之前平均为49.38上升为平均的58.08,说明硬解析有所增加,对性能已经造影响,需要调整。
⑦Latch Sleep breakdown
time:12:43:00 ~12:58:02
Get Spin
Latch Name Requests Misses Sleeps Gets
-------------------------- --------------- ------------ ----------- -----------
cache buffers chains 1,773,511 20 1 19
shared pool 2,017,327 10 10 0
space background task latc 567 2 2 0
row cache objects 2,796,969 2 2 0
call allocation 66,319 1 1 0
time:12:58:02 ~13:13:03
Get Spin
Latch Name Requests Misses Sleeps Gets
-------------------------- --------------- ------------ ----------- -----------
cache buffers chains 2,114,166 70 2 68
shared pool 2,190,149 9 9 0
row cache objects 3,062,858 8 7 1
space background task latc 564 2 2 0
JS Sh mem access 4 1 1 0
enqueue hash chains 153,468 1 1 0
time:13:13:03 ~013:28:03
Get Spin
Latch Name Requests Misses Sleeps Gets
-------------------------- --------------- ------------ ----------- -----------
shared pool 1,807,752 5 5 0
space background task latc 565 3 3 0
row cache objects 2,526,040 1 1 0
shared pool simulator 319,487 1 1 0
JS Sh mem access 3 1 1 0
time:13:28:03 ~13:43:05
Latch Name Requests Misses Sleeps Gets
-------------------------- --------------- ------------ ----------- -----------
shared pool 1,838,349 8 8 0
space background task latc 574 4 4 0
JS Sh mem access 3 1 1 0
SQL memory manager workare 86,098 1 1 0
分析:
观察“Latch Sleep breakdown”,在平均的时间段内,发生misss、sleeps的次数并不显著。
总结:
通过以上几点分析发现,将缓冲区调大后,性能有所提升,通过Disk file operations发现,磁盘I/O
性能显著提升;
通过分析后,性能上仍存在需改善的地方:存在硬解析、库缓冲命中率较低。
*****************************************************************************************
步骤五:使用绑定变量,生成 statspack报告,分析数据
目标:
1、使用绑定变量;
2、生成、导出报告;
3、分析报告。
*****************************************************************************************
1、使用绑定变量
$ vi script/bin/share_pool_sql_2.sh --重新编写查询的业务脚本,语句中加入绑定变量
sqlplus scott/tiger <<EOF
declare
v_empno emp2.empno%type;
v_emp2 emp2%rowtype;
begin
v_empno := 1;
while v_empno<=2000000 loop
v_empno :=v_empno + 1;
select * into v_emp2
from emp2 where empno=v_empno;
if v_empno=2000000 then
v_empno:=1;
end if;
end loop;
end;
/
2、生成报告
$ sh script/bin/share_pool_sql_2.sh --执行加入绑定变量的业务脚本 SQL> @?/rdbms/admin/spreport --通过快照,生成报告
3、分析报告
关注点:
①buffer hit
②library hit
③Top 5 Timed Events
④造成最大物理读的sql
⑤Buffer Pool Advisory
⑥time model system stats
⑦Latch Sleep breakdown
① buffer hit、②library hit
| 时间 |
Buffer Hit(%) |
Library Hit(%) |
| 16:34:03 ~ 16:49:02 |
99.76 |
99.99 |
| 16:49:02 ~ 17:04:01 |
99.76 |
99.98 |
| 17:04:01 ~ 17:19:00 |
99.76 |
99.99 |
| 17:19:00 ~ 17:34:00 |
99.76 |
99.99 |
| avg(last) |
99.97 |
89.94 |
| avg |
99.76 |
99.99 |
分析:
buffer hit较上次变化不大,其值已满足高于90%的标准;
library hit由之前平均89.94%提高为平均99.99%(高出95%的标准),库缓存区命中率已达到显著提
升;
buffer hit、library hit都达到高性能值。
③Top 5 Timed Events
| 时间 |
name |
waits |
Time (s) |
| 16:34:03 ~16:49:02 |
db file sequential read |
289,756 |
22 |
| cursor: pin S |
110 |
11 |
|
| cursor: mutex S |
19 |
2 |
|
| 16:49:02 ~17:04:01 |
db file sequential read |
294,214 |
19 |
| cursor: pin S |
105 |
11 |
|
| cursor: mutex S |
24 |
2 |
|
| 17:04:01 ~17:19:00 |
db file sequential read |
294,404 |
13 |
| cursor: pin S |
90 |
9 |
|
| cursor: mutex S |
31 |
3 |
|
| 17:19:00 ~17:34:00 |
db file sequential read |
296,040 |
9 |
| cursor: pin S |
104 |
11 |
|
| cursor: mutex S |
32 |
3 |
|
| avg |
db file sequential read |
293,603 |
|
分析:
对于磁盘I/O的产生,由之前产生最大I/O的“Disk file operations I/O”的waits: 18,909变成了“db file sequential read”产生的waits :293,603,I/O有所提升,性能上是可以接受的。
④查出造成物理读最大的前几个sql语句,产生执行计划
SQL>select sql_text from v$sql where disk_reads=(select max(disk_reads) from v$sql); --查询造成最大物理读的sql语句 SQL_ID SQL_TEXT ------------- ---------------------------------------- 3wmbtk9vt5pbq SELECT * FROM EMP3 WHERE EMPNO=:B1 Plan hash value: 2607329332 ----------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ----------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 41 | 4 (0)| 00:00:01 | | 1 | TABLE ACCESS BY INDEX ROWID| EMP3 | 1 | 41 | 4 (0)| 00:00:01 | |* 2 | INDEX RANGE SCAN | IND_EMPNO | 1 | | 3 (0)| 00:00:01 | -----------------------------------------------------------------------------------------
分析:
通过对比物理读最大的sql的执行计划,发现重用的执行计划已经使用绑定变量,所以性能已经达到最佳。
⑤Buffer Pool Advisory
| statistics |
||||||||
| Time |
P |
Size for Est (M) |
Size Factr |
Buffers (thousands) |
Est Phys Read Factr |
Estimated Phys Reads (thousands) |
Est Phys Read Time
|
Est % dbtime for Rds
|
| 16:34:03 ~16:49:02 |
D |
64 |
1.0 |
8 |
1.0 |
712 |
490 |
3.8 |
| 16:49:02 ~17:04:01 |
D |
64 |
1.0 |
8 |
1.0 |
1,007 |
509 |
3.4 |
| 17:04:01 ~17:19:00 |
D |
64 |
1.0 |
8 |
1.0 |
1,301 |
522 |
3.1 |
| 17:19:00 ~17:34:00 |
D |
64 |
1.0 |
8 |
1.0 |
1,597 |
531 |
2.9 |
| avg(now) |
|
64 |
1.0 |
8 |
1.0 |
1,132 |
513 |
3.3 |
| avg (last) |
|
64 |
1.0 |
7 |
1.0 |
10 |
7.5 |
.0 |
| example |
||||||||
| Time : 16:34:03 ~16:49:02 Est Phys Estimated Est Size for Size Buffers Read Phys Reads Est Phys % dbtime P Est (M) Factr (thousands) Factr (thousands) Read Time for Rds --- -------- ----- ------------ ------ -------------- ------------ -------- D 4 .1 0 1.7 1,177 811 6.3 D 8 .1 1 1.3 934 643 5.0 D 12 .2 1 1.2 824 567 4.4 D 16 .3 2 1.1 778 535 4.1 D 20 .3 2 1.1 750 516 4.0 D 24 .4 3 1.0 741 510 3.9 D 28 .4 3 1.0 731 503 3.9 D 32 .5 4 1.0 724 498 3.8 D 36 .6 4 1.0 721 496 3.8 D 40 .6 5 1.0 719 495 3.8 D 44 .7 5 1.0 718 494 3.8 D 48 .8 6 1.0 716 493 3.8 D 52 .8 6 1.0 713 491 3.8 D 56 .9 7 1.0 713 491 3.8 D 60 .9 7 1.0 713 490 3.8 D 64 1.0 8 1.0 712 490 3.8 D 68 1.1 8 1.0 712 490 3.8 D 72 1.1 9 1.0 711 489 3.8 D 76 1.2 9 1.0 711 489 3.8 D 80 1.3 10 1.0 711 489 3.8 |
||||||||
分析: 通过4个时间段进行对比,发现buffer pool的尺寸对性能的影响已经稳定了,无需再调整缓冲区的大小了。
⑥time model system stats
time:16:34:03 ~16:49:02
Statistic Time (s) % DB time
----------------------------------- -------------------- ---------
sql execute elapsed time 1,810.3 100.2
DB CPU 896.4 49.6
PL/SQL execution elapsed time 219.0 12.1
parse time elapsed 10.8 .6
hard parse elapsed time 10.5 .6
hard parse (sharing criteria) elaps 0.9 .1
hard parse (bind mismatch) elapsed 0.2 .0
PL/SQL compilation elapsed time 0.1 .0
repeated bind elapsed time 0.1 .0
sequence load elapsed time 0.0 .0
DB time 1,807.6
background elapsed time 8.1
background cpu time 0.7
time:16:49:02 ~17:04:01
Statistic Time (s) % DB time
----------------------------------- -------------------- ---------
sql execute elapsed time 1,812.9 100.1
DB CPU 896.6 49.5
PL/SQL execution elapsed time 217.1 12.0
parse time elapsed 9.7 .5
hard parse elapsed time 8.7 .5
hard parse (sharing criteria) elaps 0.8 .0
hard parse (bind mismatch) elapsed 0.1 .0
PL/SQL compilation elapsed time 0.1 .0
repeated bind elapsed time 0.1 .0
sequence load elapsed time 0.0 .0
DB time 1,810.8
background elapsed time 13.9
background cpu time 2.4
time:17:04:01 ~17:19:00
Statistic Time (s) % DB time
----------------------------------- -------------------- ---------
sql execute elapsed time 1,811.9 100.2
DB CPU 898.3 49.7
PL/SQL execution elapsed time 218.1 12.1
parse time elapsed 6.8 .4
hard parse elapsed time 6.2 .3
hard parse (sharing criteria) elaps 0.5 .0
hard parse (bind mismatch) elapsed 0.3 .0
repeated bind elapsed time 0.1 .0
PL/SQL compilation elapsed time 0.1 .0
sequence load elapsed time 0.0 .0
DB time 1,808.3
background elapsed time 7.1
background cpu time 0.6
time:17:19:00 ~17:34:00
Statistic Time (s) % DB time
----------------------------------- -------------------- ---------
sql execute elapsed time 1,811.3 100.2
DB CPU 899.4 49.7
PL/SQL execution elapsed time 222.6 12.3
parse time elapsed 8.1 .4
hard parse elapsed time 7.9 .4
hard parse (sharing criteria) elaps 1.6 .1
hard parse (bind mismatch) elapsed 0.1 .0
PL/SQL compilation elapsed time 0.1 .0
repeated bind elapsed time 0.0 .0
sequence load elapsed time 0.0 .0
DB time 1,808.5
background elapsed time 6.1
background cpu time 0.6
分析: 对比4个时间段的hard parse elapsed time,发现硬解析已经由原来平均的58.08下降到平均8.3,说明绑定变量后的重用执行计划,大大的降低了硬解析的次数。所以,对于硬解析的性能问题已经得到了解决。
⑦Latch Sleep breakdown
time:16:34:03 ~16:49:02
Get Spin
Latch Name Requests Misses Sleeps Gets
-------------------------- --------------- ------------ ----------- -----------
cache buffers chains 178,903,796 564,805 20 564,785
cache buffers lru chain 290,646 4 4 0
redo allocation 1,095 4 4 0
simulator lru latch 384 1 1 0
JS Sh mem access 3 1 1 0
time:16:49:02 ~17:04:01
Get Spin
Latch Name Requests Misses Sleeps Gets
-------------------------- --------------- ------------ ----------- -----------
cache buffers chains 181,404,031 512,003 23 511,980
cache buffers lru chain 295,633 8 8 0
shared pool 10,639,749 4 4 0
time:17:04:01 ~17:19:00
Get Spin
Latch Name Requests Misses Sleeps Gets
-------------------------- --------------- ------------ ----------- -----------
cache buffers chains 181,912,648 596,092 28 596,064
cache buffers lru chain 295,426 7 7 0
shared pool 10,382,962 2 2 0
simulator lru latch 388 1 1 0
JS Sh mem access 3 1 1 0
time:17:19:00 ~17:34:00
Get Spin
Latch Name Requests Misses Sleeps Gets
-------------------------- --------------- ------------ ----------- -----------
cache buffers chains 182,649,027 589,449 23 589,426
cache buffers lru chain 296,763 5 5 0
simulator hash latch 5,532,691 1 1 0
qmn task queue latch 128 1 1 0
shared pool 10,743,634 1 1 0
JS Sh mem access 3 1 1 0
分析: 观察“Latch Sleep breakdown”,在平均的时间段内,cache buffers chains发生misss、sleeps的次数较多,而"cache buffers lru chain",发生misss、sleeps的次数比较少。
总结:
通过以上几点分析,解决了库缓冲区命中率低、硬解析数量大的情况。数据库的性能已经得到了较好的提升。
***********************************************声明***********************************************************************
原创作品,出自 “深蓝的blog” 博客,欢迎转载,转载时请务必注明出处,否则追究版权法律责任。
深蓝的blog:http://blog.csdn.net/huangyanlong/article/details/39803995
***************************************************************************************************************************
系列链接:
蓝的成长记——追逐DBA(1):奔波于路上,挺进山东
蓝的成长记——追逐DBA(2):安装!安装!久违的记忆,引起我对DBA的重新认知
蓝的成长记——追逐DBA(3):古董上操作,数据导入导出成了问题
蓝的成长记——追逐DBA(4):追忆少年情愁,再探oracle安装(Linux下10g、11g)
蓝的成长记——追逐DBA(5):不谈技术谈业务,恼人的应用系统
蓝的成长记——追逐DBA(6): 做事与做人:小技术,大为人
蓝的成长记——追逐DBA(7):基础命令,地基之石
个人杂记,无关于技术:
自言自语的自说自话,不念过往,不畏将来。
当没进入到oracle这行之前,觉得1年可能会发生些什么事吧,即使技术水平提高不多,处事方法或许也会有所提高和改善吧。但在向其努力的这段时间里,才发现原来即使四个月也足以发生一件未曾想过能应该用1年时间发生的事,现在算是一只脚已经进入到行业以后,才发现,在高节奏快速的技术发展流中,每秒都有数以万计的人投身到这里,每四个小时足以让人发生质的变化,即使1个小时,也可能会发生很多事......无关于教育背景高低、无关于人生阅历长短、无关于人品善恶、无关于出身贫富,技术就是征服一切的力量,可以扫除一切屏障,这就是技术的魅力。
时常蓝在想,到底是什么给了蓝来到一线城市闯荡的勇气,原来一切,源于oracle。有时候给予一个人强大支撑的可能不只是一个人,或许只是一项技术由其衍生的一种精神追求,我不知道能否把这称之为“信仰”,但我确信这种力量促使着我,应该在某年某月的时候决定进入到这个行业里来试试看,决定有些改变。已经不敢回想在决定进入到oracle行业后在上海度过的最初的一个月,那段时间有些不敢想起。就像是一个莽撞的孩子,在挣扎着想要得到一个糖吃的时候,却发现无处寻觅的焦虑感。还好这一切都过去了。那一个月犯得错大约占我这半年来犯错的80%了。同时我也感谢这一个月,让我笃定我要在oracle这里做出点什么来。更感谢当时的项目经理给我指明的前进路,可以说是为我这样一个没有任何思路的初学者勾勒出了一个蓝图。包括之后对于文档编写需清晰明确、操作需谨慎小心、做事要周全大气等做事做人的积淀。突然有些感慨,很多时候“改变”真的不在于时间的长度,而在于某个“时间点”出现的那么一个“原点”的转折,人生轨迹可能翻天覆地。之后来到北京,包括在CUUG参加培训ocp脉络等知识系统性的学习、之后工作中理论变为实践等等又是一波三折,一时间想到想要感谢的人似乎太多太多,包括我的老单位,确实应该感谢的有很多。但是就感觉冥冥中有着某种力量让我留在北京,隐约中感觉到,或许就是在北京,在未来的某一天可能冥冥中就注定了应该发生些什么事吧。这种感觉很强烈,只是说不太清楚。回想起这一路,似乎都是不停得被引导到了这一条路上。扯得有点悬了,全当我酒后醉语吧。谁知道未来会怎样呢?不过看看现在,不仅身在oracle行业其中,而且同时成为了在这个时代里,对于这门技术的成长与发展的鉴证者和践行者。应该有了些许欣喜,不过还不能懈怠,因为此时此处,一个起点刚刚出现,不能再学着一步一步的走了,而是要一步一步的跑起来。如果说之前还在酝酿什么,那么下面,真的,要向DBA追逐了。而且要用跑的。
习惯了一个人的日子,蓝,又有些迷茫了。
2014年10月3日星期五于北京
*******************************************蓝的成长记系列_20150820*************************************
原创作品,出自 “深蓝的blog” 博客,欢迎转载,转载时请务必注明出处(http://blog.csdn.net/huangyanlong)。
蓝的成长记——追逐DBA(1):奔波于路上,挺进山东
蓝的成长记——追逐DBA(2):安装!安装!久违的记忆,引起我对DBA的重新认知
蓝的成长记——追逐DBA(3):古董上操作,数据导入导出成了问题
蓝的成长记——追逐DBA(4):追忆少年情愁,再探oracle安装(Linux下10g、11g)
蓝的成长记——追逐DBA(5):不谈技术谈业务,恼人的应用系统
蓝的成长记——追逐DBA(6):做事与做人:小技术,大为人
蓝的成长记——追逐DBA(7):基础命令,地基之石
蓝的成长记——追逐DBA(8):重拾SP报告,回忆oracle的STATSPACK实验
蓝的成长记——追逐DBA(9):国庆渐去,追逐DBA,新规划,新启程
蓝的成长记——追逐DBA(10):飞刀防身,熟络而非专长:摆弄中间件Websphere
蓝的成长记——追逐DBA(11):回家后的安逸,晕晕乎乎醒了过来
蓝的成长记——追逐DBA(12):七天七收获的SQL
蓝的成长记——追逐DBA(13):协调硬件厂商,六个故事:所见所感的“服务器、存储、交换机......”
蓝的成长记——追逐DBA(14):难忘的“云”端,起步的hadoop部署
蓝的成长记——追逐DBA(15):以为FTP很“简单”,谁成想一波三折
蓝的成长记——追逐DBA(16):DBA也喝酒,被捭阖了
蓝的成长记——追逐DBA(17):是分享,还是消费,在后IOE时代学会成长
蓝的成长记——追逐DBA(18):小机上WAS集群故障,由一次更换IP引起
蓝的成长记——追逐DBA(19):路上的插曲:触碰“框架”与“软件系统”
******************************************************************************************************************