SQL SERVER 2005 页面文件头部结构
Next up in the Inside the Storage Engine series is a discussion of page structure. Pages exist to store records. A database page is an 8192-byte (8KB) chunk of a database data file. They are aligned on 8KB boundaries within the data files, starting at byte-offset 0 in the file.
Here's a picture of the basic structure
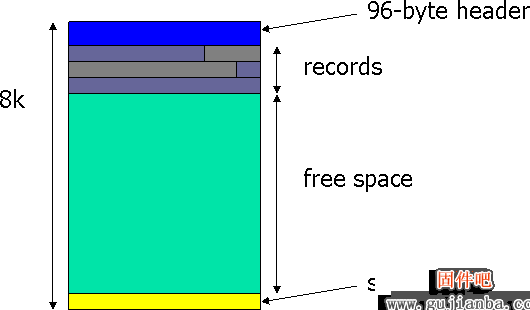
Header
The page header is 96 bytes long. What I'd like to do in this section is take an example page header dump from DBCC PAGE and explain what all the fields mean. I'm using the database from the page split post and I've snipped off the rest of the DBCC PAGE output.
DBCC
TRACEON (3604) DBCC
PAGE ('pagesplittest', 1, 143, 1); GO
m_pageId = (1:143) m_headerVersion = 1 m_type = 1
m_typeFlagBits = 0x4 m_level = 0 m_flagBits = 0x200
m_objId (AllocUnitId.idObj) = 68 m_indexId (AllocUnitId.idInd) = 256
Metadata: AllocUnitId = 72057594042384384
Metadata: PartitionId = 72057594038386688 Metadata: IndexId = 1
Metadata: ObjectId = 2073058421 m_prevPage = (0:0) m_nextPage = (1:154)
pminlen = 8 m_slotCnt = 4 m_freeCnt = 4420
m_freeData = 4681 m_reservedCnt = 0 m_lsn = (18:116:25)
m_xactReserved = 0 m_xdesId = (0:0) m_ghostRecCnt = 0
m_tornBits = 1333613242
m_xdesId
Here's what all the fields mean (note that the fields aren't quite stored in this order on the page):
- m_pageId
- This identifies the file number the page is part of and the position within the file. In this example, (1:143) means page 143 in file 1.
- m_headerVersion
- This is the page header version. Since version 7.0 this value has always been 1.
- m_type
- This is the page type. The values you're likely to see are:
- 1 - data page. This holds data records in a heap or clustered index leaf-level.
- 2 - index page. This holds index records in the upper levels of a clustered index and all levels of non-clustered indexes.
- 3 - text mix page. A text page that holds small chunks of LOB values plus internal parts of text tree. These can be shared between LOB values in the same partition of an index or heap.
- 4 - text tree page. A text page that holds large chunks of LOB values from a single column value.
- 7 - sort page. A page that stores intermediate results during a sort operation.
- 8 - GAM page. Holds global allocation information about extents in a GAM interval (every data file is split into 4GB chunks - the number of extents that can be represented in a bitmap on a single database page). Basically whether an extent is allocated or not. GAM = Global Allocation Map. The first one is page 2 in each file. More on these in a later post.
- 9 - SGAM page. Holds global allocation information about extents in a GAM interval. Basically whether an extent is available for allocating mixed-pages. SGAM = Shared GAM. the first one is page 3 in each file. More on these in a later post.
- 10 - IAM page. Holds allocation information about which extents within a GAM interval are allocated to an index or allocation unit, in SQL Server 2000 and 2005 respectively. IAM = Index Allocation Map. More on these in a later post.
- 11 - PFS page. Holds allocation and free space information about pages within a PFS interval (every data file is also split into approx 64MB chunks - the number of pages that can be represented in a byte-map on a single database page. PFS = Page Free Space. The first one is page 1 in each file. More on these in a later post.
- 13 - boot page. Holds information about the database. There's only one of these in the database. It's page 9 in file 1.
- 15 - file header page. Holds information about the file. There's one per file and it's page 0 in the file.
- 16 - diff map page. Holds information about which extents in a GAM interval have changed since the last full or differential backup. The first one is page 6 in each file.
- 17 - ML map page. Holds information about which extents in a GAM interval have changed while in bulk-logged mode since the last backup. This is what allows you to switch to bulk-logged mode for bulk-loads and index rebuilds without worrying about breaking a backup chain. The first one is page 7 in each file.
- This is the page type. The values you're likely to see are:
- m_typeFlagBits
- This is mostly unused. For data and index pages it will always be 4. For all other pages it will always be 0 - except PFS pages. If a PFS page has m_typeFlagBits of 1, that means that at least one of the pages in the PFS interval mapped by the PFS page has at least one ghost record.
- m_level
- This is the level that the page is part of in the b-tree.
- Levels are numbered from 0 at the leaf-level and increase to the single-page root level (i.e. the top of the b-tree).
- In SQL Server 2000, the leaf level of a clustered index (with data pages) was level 0, and the next level up (with index pages) was also level 0. The level then increased to the root. So to determine whether a page was truly at the leaf level in SQL Server 2000, you need to look at the m_type as well as the m_level.
- For all page types apart from index pages, the level is always 0.
- m_flagBits
- This stores a number of different flags that describe the page. For example, 0x200 means that the page has a page checksum on it (as our example page does) and 0x100 means the page has torn-page protection on it.
- Some bits are no longer used in SQL Server 2005.
- m_objId
- m_indexId
- In SQL Server 2000, these identified the actual relational object and index IDs to which the page is allocated. In SQL Server 2005 this is no longer the case. The allocation metadata totally changed so these instead identify what's called the allocation unit that the page belongs to (I'll do another post that describes these later today).
- m_prevPage
- m_nextPage
- These are pointers to the previous and next pages at this level of the b-tree and store 6-byte page IDs.
- The pages in each level of an index are joined in a doubly-linked list according to the logical order (as defined by the index keys) of the index. The pointers do not necessarily point to the immediately adjacent physical pages in the file (because of fragmentation).
- The pages on the left-hand side of a b-tree level will have the m_prevPage pointer be NULL, and those on the right-hand side will have the m_nextPage be NULL.
- In a heap, or if an index only has a single page, these pointers will both be NULL for all pages.
- pminlen
- This is the size of the fixed-length portion of the records on the page.
- m_slotCnt
- This is the count of records on the page.
- m_freeCnt
- This is the number of bytes of free space in the page.
- m_freeData
- This is the offset from the start of the page to the first byte after the end of the last record on the page. It doesn't matter if there is free space nearer to the start of the page.
- m_reservedCnt
- This is the number of bytes of free space that has been reserved by active transactions that freed up space on the page. It prevents the free space from being used up and allows the transactions to roll-back correctly. There's a very complicated algorithm for changing this value.
- m_lsn
- This is the Log Sequence Number of the last log record that changed the page.
- m_xactReserved
- This is the amount that was last added to the m_reservedCnt field.
- m_xdesId
-
- This is the internal ID of the most recent transaction that added to the m_reservedCnt field.
- m_ghostRecCnt
- The is the count of ghost records on the page.
- m_tornBits
- This holds either the page checksum or the bits that were displaced by the torn-page protection bits - depending on what form of page protection is turnde on for the database.
Records
See this blog post for details.
Slot Array
It's a very common misconception that records within a page are always stored in logical order. This is not true. There is another misconception that all the free-space in a page is always maintained in one contiguous chunk. This also is not true. (Yes, the image above shows the free space in one chunk and that very often is the case for pages that are being filled gradually.)
If a record is deleted from a page, everything remaining on the page is not suddenly compacted - inserters pay the cost of compaction when its necessary, not deleters.
Consider a completely full page - this means that record deletions cause free space holes within the page. If a new record needs to be inserted onto the page, and one of the holes is big enough to squeeze the record into, why go to the bother of comapcting it? Just stick the record in and carry on. What if the record should logically have come at the end of all other records on the page, but we've just inserted it in the middle - doesn't that screw things up somewhat?
No, because the slot array is ordered and gets reshuffled as records are inserted and deleted from pages. As long as the first slot array entry points to the logically first record on the page, everything's fine. Each slot entry is just a two-byte pointer into the page - so its far more efficient to manipulate the slot array than it is to manipulate a bunch of records on the page. Only when we know there's enough free space contained within the page to fit in a record, but its spread about the page do we compact the records on the page to make the free space into a contiguous chunk.
One interesting fact is that the slot array grows backwards from the end of the page, so the free space is squeezed from the top by new rows, and from the bottom by the slot array.
-
适合英文不错的朋友,介绍的算是网上比较详细的了