Kafka基础概念
Kafka基础概念
前言
最近项目中要使用到流式数据处理,借此机会学习一下Kafka的相关知识。
简介
Apache Kafka是一个分布式的、分区的、可重复提交的日志系统。它以独特的设计提供了消息系统的功能。作为一个Apache开源项目,Kafka已经得到很多业内人士的关注,并且已经在很多公司内部进行使用,如Linkin、eBay等。
Kafka作为一个分布式发布-订阅系统,也遵循着一般的发布-订阅系统的基础架构。
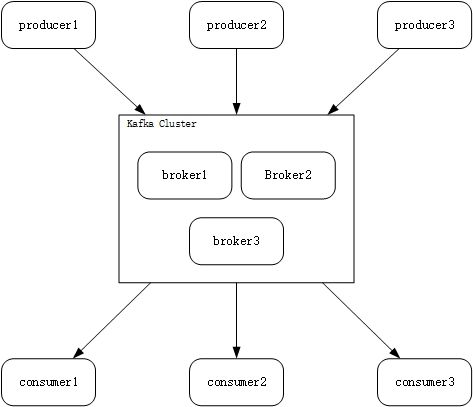
Kafka中将不同的消息通过不同的主题(topic)来区分,在图中,生产者向Kafka集群发布消息,消费者通过向某一个主题注册,进而接收相关主题的消息。Kafka可以运行在一台或多台的服务器上,每台服务器成为一个经纪人(broker)。
主要概念
分区(Partition)
Kafka会为每个主题分一个区,发布的消息都会存到相应的分区中。每个分区是一个有序的、不可变的序列,每条消息通过偏移量来定位。具体情形如下:
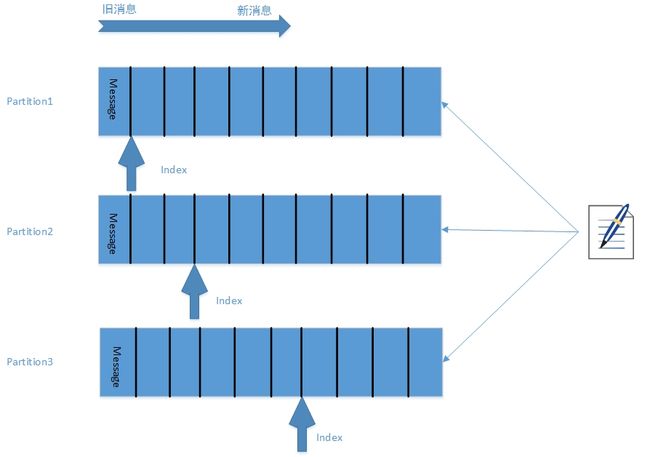
这样做的好处是,因为一个主题可以有多个分区,所以可以容易地拓展主题的容量到多台机器。同时分区也为高并发、高容错性提供了可能性。
主题(Topics)和日志(Logs)
需要注意的是,Kafka保存数据是根据时间来决定的,而不是它是否被消费者消费。如果在数据的生命周期内,它被消费后仍然会存储在Kafka中。但如果它在生命周期内没有被消费,同样它也会在生命周期结束时被丢弃。而消费者是通过分区中的偏移量来定位消费的数据的,通常是顺序读下去,但也可以通过改变偏移量的值来随意读取信息。
分布式(Distribution)
分布式跟分区是紧密相连的,正是数据是以分区的形式存储的,才给分布式提供了可能。分区的数据会在多个服务器上进行备份以便容错。每份数据都会以主分区的形式存储在某一台服务器上,它的副本称为从分区,存储在其他服务器上。主分区处理来自外界的读写请求,从分区会被动的复制数据的变化。如果主分区出现了故障,某一个从分区会变为主分区。此外一台服务器可以拥有一个主分区和多个其他分区的从分区,这样能充分利用资源,又保证了容错性。
生产者(Producers)
生产者决定发布什么消息、消息属于哪个主题及在该主题的哪个分区下,关于分区的选择可以通过自己设定的方法来实现不同的方案。
消费者(Consumers)
消费者会被被划分成一个个消费者组,属于某一个主题的消息会被分派到它的一个分区下,而该分区与订阅了该主题的消费组中的某一个消费者相对应,也就是说消息只会发送给订阅的消费者组中的一个消费者。可以把消费者组理解成消息的真正的订阅者,而它下面的消费者只是处理消息的线程池,这样做可以保证系统的扩展性和容错性。而消费者与分区的关系是,每个分区只能有一个消费者,这样保证了在这一分区中的所有消息都能按序处理。但不同分区中的消息处理顺序不能保证,如果要保证所有的数据都按序处理,可以使每个话题只有一个分区,每个消费者组只有一个消费者。
保证(Guarantees)
Kafka可以保证:
- 由生产者发送给特定主题分区的消息会以发送的顺序添加。也就是说,后发送的消息一定在先发送的消息之后。
- 消费者会按消息在日志中的存储顺序看到它们。
- 对于副本因子为N的主题,我们可以承受N-1个服务器发生故障而保证提交到日志的消息不会丢失。
应用场景
消息队列
跟大多数的消息系统相比,Kafka有更好的吞吐量和容错性,这让Kafka成为了一个很好的大规模消息处理应用的解决方案。消息系统一般吞吐量相对较低,但是需要更小的端到端延时,而Kafka能提供这些保障。
网页行为跟踪
Kafka的另一个应用场景是跟踪用户浏览页面、搜索操作及其他用户行为,以发布-订阅的模式实时记录到对应的话题中。这些结果被订阅者拿到后就可以做进一步的处理。
数据监控
Kafka也可以作为操作记录的监控模块来使用,即汇集记录一些操作信息,对系统进行监控。
日志聚合
日志聚合一般来说是从服务器上收集日志文件,然后放到一个集中的位置进行处理。然而Kafka忽略掉文件的细节,将其更清晰地抽象成一个个日志或事件的消息流。这就让Kafka处理过程延迟更低,更容易支持多数据源和分布式数据处理。比起以日志为中心的系统比如Scribe或者Flume来说,Kafka提供同样高效的性能和因为冗余达到的更高的可用性保证,以及更低的端到端延迟。
流式处理
这是Kafka的一个重要应用场景。保存收集流数据,以提供给之后对接的Storm或其他流式计算框架进行处理。很多用户会对那些从原始话题来的数据进行阶段性处理、汇总、扩充或者以其他的方式转换到新的话题下再继续后面的处理。
事件源
事件源是一种应用程序设计的方式,该方式的状态转移被记录为按时间顺序排序的记录序列。Kafka可以存储大量的日志数据,这使得它成为一个对这种方式的应用来说绝佳的后台。
持久性日志
Kafka可以为一种外部的持久性日志的分布式系统提供服务。这种日志可以在节点间备份数据,并为故障节点数据回复提供一种重新同步的机制。Kafka中日志压缩功能为这种用法提供了条件。在这种用法中,Kafka类似于Apache BookKeeper项目。
总结
这篇文章主要介绍了Apache Kafka中的几个基本概念,及其应用场景。