【模式识别】CART和GML AdaBoost MATLAB TOOLBOX
GML AdaBoost Matlab Toolbox是一款非常优秀的AdaBoost工具箱,内部实现了Real AdaBoost, Gentle AdaBoost和Modest AdaBoost三种方法。
AdaBoost的训练和分类的结构都是相似的,可以参考前一篇《Boosting》,只简介一下GML。GML内部弱分类器使用的CART决策树。决策树的叶子表示决策,内部每个分支都是决策过程。从根部开始,每个决策结果指向下一层决策,最后到达叶子,得到最终的决策结果。一个比较简单的示意如下图所示:
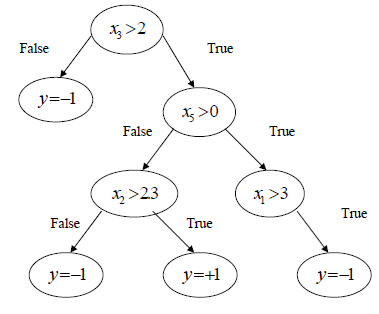
对于特征{x1,x2,x3}值为{4,-1,2}的样本,上图决策树的最终决策为y=-1,而对于{3,-2,3}的样本预测值为+1。
工具箱中CART根的构造算法如下:
1. 对于n为特征的每个维度,分别找到阈值使得分类错误率最小
2. 选择错误率最小的第i维构造根节点:
a) 预测xi>Θ
b) 分别构造true/false子树分支,各自的分类结果作为叶子
在树中移动并最终到达叶子,我们把得到的预测结果错误分类一个样本的概率作为“树叶的错误率”。整颗决策树的构造使用如下规则:
1. 构造根节点
2. 选择错误率最小的叶子
3. 仅适用于和所选叶子相关的训练数据构造节点
4. 使用构造的节点代替所选的叶子
5. 重复2-4步直到所有的叶子错误率为0,或者到达循环结束的循环次数。
事实上,工具箱使用中,CART树的构造过程只有树深一个可调参数,使用:
function tree_node = tree_node_w(max_splits)函数初始化最大树深,之后就是将构造的弱分类器传给相应的AdaBoost函数。以下是一个使用示例:
% Step1: reading Data from the file
clear
clc
file_data = load('Ionosphere.txt');
Data = file_data(:,1:10)';
Labels = file_data(:,end)';
Labels = Labels*2 - 1;
MaxIter = 200; % boosting iterations
% Step2: splitting data to training and control set
TrainData = Data(:,1:2:end);
TrainLabels = Labels(1:2:end);
ControlData = Data(:,2:2:end);
ControlLabels = Labels(2:2:end);
% Step3: constructing weak learner
weak_learner = tree_node_w(3); % pass the number of tree splits to the constructor
% Step4: training with Gentle AdaBoost
[GLearners GWeights] = GentleAdaBoost(weak_learner, TrainData, TrainLabels, MaxIter);
% Step5: training with Modest AdaBoost
[MLearners MWeights] = ModestAdaBoost(weak_learner, TrainData, TrainLabels, MaxIter);
% Step5: training with Modest AdaBoost
[RLearners RWeights] = RealAdaBoost(weak_learner, TrainData, TrainLabels, MaxIter);
% Step6: evaluating on control set
ResultG = sign(Classify(GLearners, GWeights, ControlData));
ResultM = sign(Classify(MLearners, MWeights, ControlData));
ResultR = sign(Classify(RLearners, RWeights, ControlData));
% Step7: calculating error
ErrorG = sum(ControlLabels ~= ResultG) / length(ControlLabels)
ErrorM = sum(ControlLabels ~= ResultM) / length(ControlLabels)
ErrorR = sum(ControlLabels ~= ResultR) / length(ControlLabels)
以上代码构造深度为3的CART决策树作为弱分类器,分别使用GentleAdaBoost,ModestAdaBoost和RealAdaBoost迭代200次训练AdaBoost分类器。以上代码直接使用MaxIter调用函数训练与下面方法是等价的:
% Step4: iterativly running the training
for lrn_num = 1 : MaxIter
clc;
disp(strcat('Boosting step: ', num2str(lrn_num),'/', num2str(MaxIter)));
%training gentle adaboost
[GLearners GWeights] = GentleAdaBoost(weak_learner, TrainData, TrainLabels, 1, GWeights, GLearners);
%evaluating control error
GControl = sign(Classify(GLearners, GWeights, ControlData));
GAB_control_error(lrn_num) = GAB_control_error(lrn_num) + sum(GControl ~= ControlLabels) / length(ControlLabels);
%training real adaboost
[RLearners RWeights] = RealAdaBoost(weak_learner, TrainData, TrainLabels, 1, RWeights, RLearners);
%evaluating control error
RControl = sign(Classify(RLearners, RWeights, ControlData));
RAB_control_error(lrn_num) = RAB_control_error(lrn_num) + sum(RControl ~= ControlLabels) / length(ControlLabels);
%training modest adaboost
[NuLearners NuWeights] = ModestAdaBoost(weak_learner, TrainData, TrainLabels, 1, NuWeights, NuLearners);
%evaluating control error
NuControl = sign(Classify(NuLearners, NuWeights, ControlData));
MAB_control_error(lrn_num) = MAB_control_error(lrn_num) + sum(NuControl ~= ControlLabels) / length(ControlLabels);
end但是第二段代码每次显示使用了上一次的训练结果,实际运行速度更快。