李航,统计学习方法-决策树章节修正
声明:
1,本篇为个人对《2012.李航.统计学习方法.pdf》的学习总结,不得用作商用,欢迎转载,但请注明出处(即:本帖地址)。
2,由于本人在学习初始时有很多数学知识都已忘记,因此为了弄懂其中的内容查阅了很多资料,所以里面应该会有引用其他帖子的小部分内容,如果原作者看到可以私信我,我会将您的帖子的地址付到下面。
3,如果有内容错误或不准确欢迎大家指正。
4,如果能帮到你,那真是太好了。
这里分享下《2012.李航.统计学习方法》的一个让人痛苦的地方,也算是自己做个标记:
如果你看的是pdf,那在第76页,
如果你看的是纸质书,那看第5.2.2章
这里需要说明的是关于“熵、条件熵和信息增益”的那三个公式,
首先根据书上对这三个公式及其变量的含义列举如下:
说明:
1,这一步列举完全按照书上的定义来的,而这个定义中说明的变量含有真心混乱,请不要记!
2,经验熵的公式就是熵的公式,经验条件熵的公式就是条件熵的公式。
熵:
设X为一个取有限个值的离散随机变量,则其概率分布为:
![]()
然后其熵为
![]()
总结:上述的X为随机变量集合,即:样本集合
条件熵:
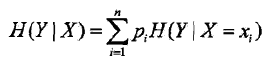
在条件熵下面紧跟着一句话:

总结:上述的X为特征集合,Y为类集合
那这样的话熵中的X的就是特征集合喽(真的?)
信息增益:
![]()
书上该公式的下面紧跟着如下内容:

总结:
1,上述的D为训练数据集,A为特征。
2,而上面截图中的第二段又说明了:H(D)为经验熵,H(D|A)为经验条件熵,于是我们可以将信息增益的公式换成X,Y,来更好的理解:
g( X, Y ) = H( X ) – H( X | Y )
。。。。
。。。。
等等,不对,怎么这里变成 H( X | Y ) 了。 H( D ) 对应 H( X ) 没错,那用X替换D的话,不就改用Y替换A吗?
好吧,书上你到信息增益这里把X,Y给调换下位置了。
行,为了保持统一,我就把熵的公式写成

行了吧。
于是,从新总结一遍(最终这一遍还不对!):
熵:

Y为:特征集合
条件熵:
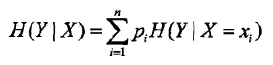
X为特征集合,Y为类集合
信息增益:
g( D, A ) =H( D ) – H( D | A ) D为训练数据集,A为特征
改成了:
g(X, Y ) = H( X ) – H( X | Y ) X为训练数据集,Y为特征
等等!哪里不对!!
怎么熵里:Y为特征,条件熵里:X为特征,到信息增益里:又成了Y为特征。
什么鬼!!
无奈之下我只好继续向下看,直到下面的例子:
--------------------------------------------------------------------------------------------------------------------------------
下面是截图,想看就看,看的头晕就看后面的“简单的说”

简单的说:
一个总的数据集按照两种标准进行了两种分类:
标准一,按照类分类:
这个集合一共有|D|个元素,使用分类的方法将集合D分成了K份,C1,C2,…,Ck,一份集合中有|Ck|个样本数量。那这样一份小集合占总集合的比例就是:|Ck|/|D|
标准二,按照特征分类:
还是这个集合,按照有i个不同取值{a1,a2,…,ai}的特征集合A把这个集合D划分成i个子集D1,D2,…,Di,|Di|就是第i个子集中的样本个数,这样一个小子集占总集合的比例就是:|Di|/|D|
而一定会有这样的元素们满足“属于类Ck时也属于Di”对吧,假设我们已经统计出来这个元素集合的数量为|Dik|了,那么这样的元素集合占总集合的比例就是:|Dik|/|D|
然后:
1,计算熵:H(D)

2,计算经验熵:
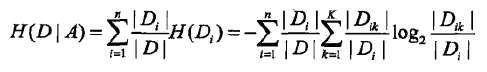
3,计算信息增益:
![]()
下面让我们对一对这些变量:
对于熵的计算:
Ck为一个类集合的数量
D是总集合数
对于经验熵:
D是总集中元素的总数
A是特征
Di是一个特征集合中元素的数量
Dik是即属于“熵”中那个类又属于“经验熵”中的这个类的元素的数量。
--------------------------------------------------------------------------------------------------------------------------------
到此,终于明了:
下面进行汇总:
熵:
设X为一个取有限个值的离散随机变量,则其概率分布为:
![]()
然后其熵为
![]()
总结:上述的X为样本集合总数,pi = 某个类的数量(xi) / 样本集合总数
条件熵:

总结:上述的X为样本集合总数,Y为特征
于是H(X | Y ) = * pi * ( pj * pj),pj = “即属于“熵”中那个类又属于“经验熵”中的这个类的元素的数量” / 该类的元素数量
信息增益:
![]()
然后利用这个总结,再向后看没问题了。
后续:
如果看我上面的有些不知所云的话,那总结起来就一句话:
把条件熵的 H(Y|X)改成了H(X|Y)
因为书上规定:
熵:H(X)
条件熵:H(Y|X)
信息增益: g(D,A) = H(D) - H(D|A)
而书上又说H(D)就是经验熵,H(D|A)是经验条件熵,那把D换成X,A换成Y的话就成了 g(X,Y) = H(X)-H(X|Y),这完全对不上号。