(莱昂氏unix源代码分析导读-6) stack使用和进程的分段
1.Stack使用:
PDP11使用倒置的栈,即栈底在高地址,栈向低地址生长,如下图所示:
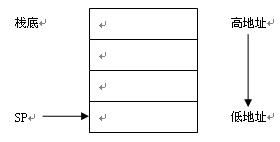
(1) 压栈示例: MOV R1,–(SP)
先移动SP,再放置R1
(2) POP示例: MOV (SP)+,R1
先取栈内值,再移动栈指针释放该地址。
参数压栈规则:
(1) 参数逆序压栈;
(2) 最后放置Return Address
如: rpta (aa, bb)
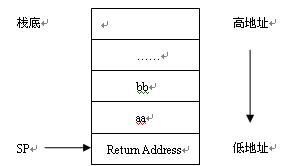
栈的示意图
【代码示例1】:
1889 savu(u.rsav); savu是一个单参数的Subroutine
725 _savu:
726 bis $340, PS 设置CPU Priority to 7
727 mov (sp)+, r1 “Return Address” to r1
728 mov (sp), r0 参数(u.rsav) to r0
729 mov sp, r0+ sp ---> u.rsav[0]
730 mov r5, r0+ r5 ---> u.rsav[1]
731 bic $340 设置CPU Priority to 0
732 jmp (r1) return
【代码示例2】:
696 _copyses:
697 mov PS, - (sp) 在栈中保存PS
698 mov UISA0, - (sp) 保存UISA0
699 mov UISA1, -(-sp) 保存UISA1
700 mov $30340, PS 设置PS
701 mov 10 (sp),UISA0 参数1--->UISA0
702 mov 12 (sp),UISA1 参数2--->UISA1
703 mov UISD0, - (sp) 保存UISD0
704 mov UISD1, - (sp) 保存UISD1
705 mov $6, UISD0 6--->UISD0
706 mov $6, UISD1 6--->UISD1
707 ……
这里的陷阱是:
(1)对栈使用了两种寻址:
“-sp”、“10(sp)”的单位是不同的,-sp会移动一个word(2 bytes);而10(sp)中的10是以byte为单位的。
(2)10(sp)、12(sp)中的10、12为octal,即8dec、10dec。
PDP11在硬件上对这种栈结构的形成提供了便利——它提供了jsr和rts指令,以完成子函数的调用和返回。
这两个指令比较复杂,简单的用法:
(1) jsr pc,gword ——当前pc压栈,然后将pc设置为gword(即跳到gword处)
(2) rts pc ——从栈顶弹回pc
更复杂一些的,如:
0558: klin: jsr r0,call; _klrint
(1) r0压栈;
(2) r0-<--updated pc(即(r0) == _klrint)
(3) pc<---- call
这样r0的内容可以作为参数带入。
【思考题】:Return Address处于栈顶,“被调用程序”可直接使用rts指令Return回调用程序。
那末,栈由谁负责清理呢?
2. 进程的分段:
(1) Text
正文段,可执行语句都在此段中。写保护,可重用。即一个程序启动两个进行,则这两个进程可重用Text段。
(2) Data
数据段,存放初始化的数据。
Data段紧跟在Text段之后。但由于Text段一般为写保护,故如其未满一page,该page也会被Text段保留。
所以,Date的起始地址为Text段后的第一个8K边界。
(3) Bss
存放程序中未初始化的全局变量的一块内存区域,一般在初始化时将会清零。
紧跟在Data段之后。
Data段往往是(可执行)文件的一部分,当可执行文件Load入系统后,data段就由文件内的内容进行了初始化。
bss段不同,在文件中没有这部分的内容,因此,Load入系统时,这部分的内容未经初始化。
以上并非进程的全部空间,例如,还有stack segment、PPDA(进程数据区)等等,我们将来还会谈到。
unix v6定义了“_ e d a t a”和“_ e n d”两个伪变量,分别表示“内核启动进程”的数据段以及数据段加上b s s段的长度,如图所示:
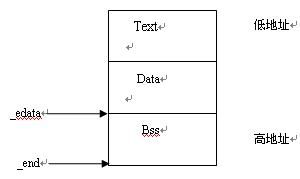
最后,顺便谈一下“.”和“^”的用法。我们已经遇到过这个两个符号了:
(1) “.”表示当前地址(位置);
(2) “^”用于给当前地址赋值。
代码示例:
1463 .bss Following is the content of bss segment
1464 /*------------------------------- */
1465 .globl nofault, ssr, badtrap 声明三个符号为全局符号
1466 nofault: .=.+2 当前地址 =当前地址+2,即保留2个Byte,初始化为0
1467 ssr: .=.+6 当前地址 =当前地址+6,即保留2个Byte,初始化为0
1468 badtrap: .=.+2 ……
507 .=0^. 当前地址 =0 octal
br 1f
4 指令IOT。执行20octal的中断。
…
.=40^. 当前地址设置为40 octal
博客地址: http://blog.csdn.net/cszhao1980