C# 网络编程之通过豆瓣API获取书籍信息
这篇文章主要是讲述如何通过豆瓣API获取书籍的信息,起初看到这个内容我最初的想法是在"C# 网络编程之网页简单下载实现"中通过HttpWebResponse类下载源码,再通过正则表达式分析获取结点标签得到信息.但后来发现可以通过豆瓣API提供的编程接口实现.
该文章仅是基础性C#网络编程文章,尝试测试了下豆瓣API,并没什么高深的内容.但希望对大家有所帮助,仅供学习.
(警告:文章仅供参考,提供一种想法,否则访问多次-10次被403 forbidden莫怪.建议认证使用豆瓣API)
一.豆瓣API介绍
在开发之前你需要申请创建一个应用,从而获取一个新的API Key(唯一标识你的Connect站点和API使用者).
正如豆瓣API快速入门(http://www.douban.com/service/apidoc/guide)中例子:这个示例中展示了使用API获得ID为1220562的书的信息, 请求的url如下(注意将{yourapikey}替换为你的API Key).
http://api.douban.com/book/subject/1220562?apikey={yourkeyapi}
返回的XML文档如下所示:
<?xml version="1.0" encoding="UTF-8"?> <entry xmlns="http://www.w3.org/2005/Atom" xmlns:db="http://www.douban.com/xmlns/" xmlns:gd="http://schemas.google.com/g/2005" xmlns:openSearch="http://a9.com/-/spec/opensearchrss/1.0/" xmlns:opensearch="http://a9.com/-/spec/opensearchrss/1.0/"> <id>http://api.douban.com/book/subject/1220562</id> <title>满月之夜白鲸现</title> <category scheme="http://www.douban.com/2007#kind" term="http://www.douban.com/2007#book"/> <author> <name>[日] 片山恭一</name> </author> <link href="http://api.douban.com/book/subject/1220562" rel="self"/> <link href="http://book.douban.com/subject/1220562/" rel="alternate"/> <link href="http://img3.douban.com/spic/s1747553.jpg" rel="image"/> <link href="http://m.douban.com/book/subject/1220562/" rel="mobile"/> <summary>那一年,是听莫扎特、钓鲈鱼和家庭破裂的一年。说到家庭破裂,母亲怪自己当初没有找到好男人,父亲则认为当时是被狐狸精迷住了眼,失常的是母亲,但出问题的是父亲……。</summary> <db:attribute name="isbn10">7543632608</db:attribute> <db:attribute name="isbn13">9787543632608</db:attribute> <db:attribute name="title">满月之夜白鲸现</db:attribute> <db:attribute name="pages">180</db:attribute> <db:attribute name="translator">豫人</db:attribute> <db:attribute name="author">[日] 片山恭一</db:attribute> <db:attribute name="price">15.00元</db:attribute> <db:attribute name="publisher">青岛出版社</db:attribute> <db:attribute name="binding">平装</db:attribute> <db:attribute name="pubdate">2005-1</db:attribute> <db:tag count="125" name="片山恭一"/> <db:tag count="59" name="日本"/> <db:tag count="53" name="日本文学"/> <db:tag count="36" name="小说"/> <db:tag count="31" name="满月之夜白鲸现"/> <db:tag count="14" name="爱情"/> <db:tag count="8" name="純愛"/> <db:tag count="8" name="外国文学"/> <gd:rating average="7.0" max="10" min="0" numRaters="322"/> </entry>
此时,我需要做的就是通过输入的URL获取返回的XML中的数据,通过HttpWebRequest和HttpWebResponse获取HTTP请求和应答,并解析XML中的信息(较难).后来我才发现如果想试验下API,豆瓣是允许在不申请API Key情况下进行API调用(每分钟请求不超过10次).也就是说我在程序中输入网址如下即可返回XML.
http://api.douban.com/book/subject/1220562
二.C#获取豆瓣书籍信息
1.添加命名空间
using System.Net; //HTTP using System.IO; //文件 流操作 using System.Text.RegularExpressions; //正则表达式 using System.Xml; //Xml文档
2.添加按钮点击事件
//点击按钮"获取信息"
private void button1_Click(object sender, EventArgs e)
{
richTextBox1.Clear();
//获取输入的URL
string url = textBox1.Text.ToString();
//HttpWebRequest对象实例:该类用于获取和操作HTTP请求 创建WebRequest对象
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
//HttpWebResponse对象实例:该类用于获取和操作HTTP应答
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
//构造字节流
StreamReader reader = new StreamReader(response.GetResponseStream());
//流从头读至尾
string xmlUrl = reader.ReadToEnd();
reader.Close();
response.Close();
//调用自定义函数获取XML信息
GetInfoXML(xmlUrl);
}
3.自定义函数获取书籍信息
//获取豆瓣XML内容并显示
private void GetInfoXML(string xmlUrl)
{
try
{
//实例Xml文档
XmlDocument xmlDoc = new XmlDocument();
//从指定字符串加载xml文档
xmlDoc.LoadXml(xmlUrl);
//实例解析、加入并移除集合的命名空间及范围管理
XmlNamespaceManager xmlNM = new XmlNamespaceManager(xmlDoc.NameTable);
//将给定命名空间添加到集合
xmlNM.AddNamespace("db", "http://www.w3.org/2005/Atom");
//获取文档根元素
XmlElement root = xmlDoc.DocumentElement;
//选择匹配Xpath(内容)表达式的结点列表
//函数原型:SelectNodes(string xpath,XmlNamespaceManger nsmgr)
XmlNodeList nodes = root.SelectNodes("/db:entry", xmlNM);
//获取子节点信息
foreach (XmlNode nodeData in nodes)
{
foreach (XmlNode childnode in nodeData.ChildNodes)
{
string str = childnode.Name;
switch (str)
{
case "title":
string name = "标题名称:" + childnode.InnerText + "\r\n\r\n";
richTextBox1.AppendText(name);
break;
case "author":
string author = "作者:" + childnode.InnerText + "\r\n\r\n";
richTextBox1.AppendText(author);
break;
case "db:attribute":
{
//获取<db:attribute name="XXX">的属性
switch (childnode.Attributes[0].Value)
{
case "pages":
string pages="总页数:"+childnode.InnerText+"\r\n\r\n";
richTextBox1.AppendText(pages);
break;
case "price":
string price="价格:"+childnode.InnerText+"\r\n\r\n";
richTextBox1.AppendText(price);
break;
case "publisher":
string publisher="出版社:"+childnode.InnerText+"\r\n\r\n";
richTextBox1.AppendText(publisher);
break;
case "pubdate":
string pubdate="出版日期:"+childnode.InnerText+"\r\n\r\n";
richTextBox1.AppendText(pubdate);
break;
}
break;
}
case "summary":
//显示内容 WordWrap设置为true自动换行(无需调用Split函数或求字符长度)
string summary="内容:"+childnode.InnerText+"\r\n\r\n";
richTextBox1.AppendText(summary);
break;
case "link":
//结点属性是Attributes[0]却失败,不能获取
if (childnode.Attributes[1].Value == "image")
{
//获取image路径 <link rel="image" href="http://xxx.jpg"/>
string imagePath = childnode.Attributes[0].Value;
//下载图片
string imageName = "local.jpg";
System.Net.WebClient client = new System.Net.WebClient();
//下载指定URL资源到本地文件夹
//函数原型 DownloadFile(string address,string fileName)
client.DownloadFile(imagePath,imageName);
//从本地文件中加载图片
this.pictureBox1.Image = Image.FromFile(imageName);
//图像原图大小
this.pictureBox1.SizeMode = PictureBoxSizeMode.Zoom;
//下载第二张图片时总是出现"WebClient请求期间发生异常"
}
break;
} //switch
} //foreach
} //foreach
}
catch (Exception msg) //异常处理
{
MessageBox.Show(msg.Message);
}
} //GetInfoXML
4.运行结果如下
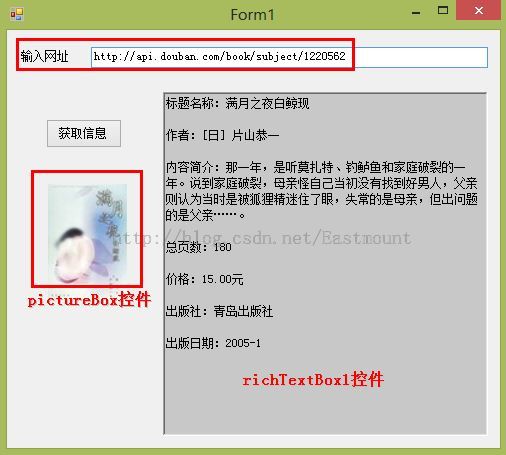
源网址中的书籍信息介绍如下图所示:
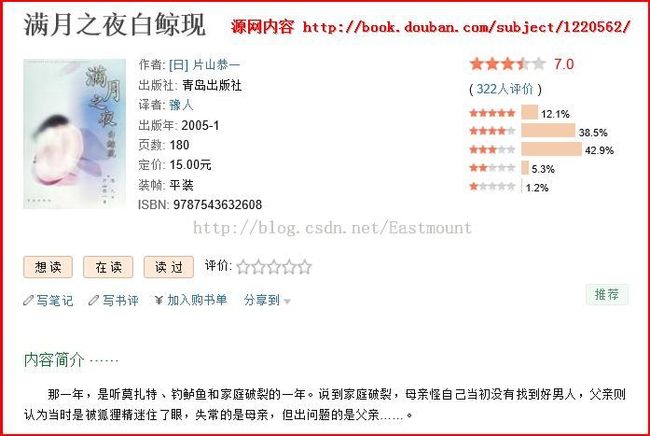
三.遇到的问题及总结
由上图可以发现我输入的网址没有包含API key也能获取,但我在测试时总是使用的.然后同时我也遇到了一些问题:
1.豆瓣API获取书籍信息接口,需要传subjectID或isbnID(国际标准书号),但我想实现的是只知道书名,就能获取书籍的信息,而不是仅仅传入一串URL,这些分析都让程序内容实现,这是接下来需要做的.
2.在使用WebClient和DownloadFile(string address,string fileName)下载图片时,当获取第二张图片总会提示错误"WebClient请求期间发生异常",不知道为啥,但不想使用stream或并发获取图片,仅想知道这是为啥?
3.这仅仅是一篇基础性的介绍使用豆瓣API的文章,目前豆瓣针对已经授权用户(开发API采用OAuth协议进行鉴权)可以实现很多功能,后面如果有时间可以写些“查看用户信息、用户友邻信息、增删改查用户收藏、查看评论”的文章.
最后希望该文章对大家有所帮助,如果文章中有错误或不足之处,还请海涵.同时文章也参考了一些资料,感谢这些作者.
(By:Eastmount 2014-5-2 下午3点 原创:http://blog.csdn.net/eastmount)
参考资料:
1.豆瓣API快速入门
http://www.douban.com/service/apidoc/guide
2.c#使用豆瓣API-sun8134
这里非常感谢该文章,在解析XML中我使用SelectSingleNodes方法失败后,参考了他的方法,也推荐大家去阅读
http://www.cnblogs.com/sun8134/archive/2010/12/15/1906879.html
3.豆瓣客户端-zh19900207 该文章仅有界面,但也是我想实现的功能描述
http://blog.csdn.net/zh19900207/article/details/8586000
4.XmlNode.SelectNodes 方法
http://msdn.microsoft.com/zh-cn/library/4bektfx9.aspx