《淘宝技术这十年》读书笔记 (四). 分布式时代和中间件
《淘宝技术这十年》读书笔记 (一).淘宝网技术简介及来源
《淘宝技术这十年》读书笔记 (二).Java时代的脱胎换骨和坚若磐石
《淘宝技术这十年》读书笔记 (三).创造技术TFS和Tair
这篇文章主要讲述分布式时代和中间件相关知识,包括服务化、HSF、Notify和TDDL。同时里面有我们经常遇见的编码错误等相关问题,希望文章对你有所帮助!
一. 分布式时代
1.服务化
在系统发展的过程中,架构师的眼光至关重要,作为程序员,只要把功能实现即可,但作为架构师,要考虑系统的扩展性、重用性,对于这种敏锐的感觉,有人说是一种“代码洁癖”。
淘宝早期有几个架构师就具备了这种感觉,周锐虹开发的Webx是一个扩展性很强的框架,行癫在这个框架上插入了数据分库路由的模块、Session框架等。在做淘宝后台系统时,同样需要这几个模块,行癫指导我把这些模块单独打成JAR包。
上面说的都是比较小的复用模块,到2006年,我们做了一个商品类目属性的改造,在类目中引入了属性的概念。项目代号叫“泰山”,这是一个举足轻重的项目,这个改变是一个划时代的创新。
在这之前三年时间内,商品的分类都是按照树状一级一级的节点来分的,随着商品数量增长,类目也变得越来越深、复杂。这样,买家如果查找一件商品,就要逐级打开类目,找商品之前要弄清商品的分类。一个很严重的问题,例如男装里有T恤、T恤下面有耐克、耐克有纯棉的,女装也有T恤、T恤下面还是有耐克、耐克下有纯棉,那是先分男女装,再分款式、品牌和材质呢?还是先分品牌,再分款式、材质和男女装呢?
这时一灯说品牌、款式、材质等都可以叫做“属性”,属性是类似Tag(标签)的一个概念,与类目相比更加灵活,这样也缩减了类目的深度。这个思想解决了分类的难题!
从系统角度来看,我们建立了“属性”这样一个数据结构,由于除了类目的子节点有属性外,父节点也可能有属性,于是类目属性合起来也是一个结构化的数据对象。把它独立出来作为一个服务,叫做Catserver(Category Server)。跟类目属性密切关联的商品搜索功能独立出来,叫做Hesper(金星)。Catserver和Hesper供淘宝的前后台系统调用。
现在淘宝的商品类目属性已经是全球最大的,几乎没有什么类目的商品在淘宝上找不到(除违禁品),但最初的类目属性改造完之后,缺乏属性数据,尤其是数码类。从哪里弄这些数据呢?我们跟“中关村在线”合作,拿到了很多数据。
有了类目属性给运营工作带来了很大的便利,我们知道淘宝的运营主要就是类目的运营,什么季节推出什么商品,都要在类目属性上做调整,让买家容易找到。所属商品的卖家要编辑一次自己的商品,如冬天把羽绒衣调整到女装一级目录下,但随着商品量的增长,卖家的工作量越来越大。
到了2008年,我们研究了超市里前后台商品的分类,发现超市前后台商品可以随季节和关联来调整摆放场景(例如著名的啤酒和尿布的关联),后台仓库里要按照自然类目来存储,二者密切关联,却又相互分开。淘宝前台展示的是根据运营需要摆放商品的类目和属性。改造后的类目属性服务取名为Forest(森林,与类目属性有点神似。Catserver还用于提供卖家授权、品牌服务、关键词等相关服务)。类目属性的服务化是淘宝在系统服务化方面做的第一个探索。
2.一种常见的编码错误
虽然个别架构师具备了“代码洁癖”,但淘宝前台系统的业务量和代码量还是呈爆炸式的增长。
业务方总在后面催,开发人员不够就继续招人,招来的人根本看不懂原来的业务,只好摸索着在“合适的地方”加上一些“合适的代码”,看看运行起来像那么回事后,就发布上线。
在这样的恶性循环中,系统越来越肿,业务的耦合性越来越高(高内聚、低耦合),开发的效率越来越低。借用当时较流行的一句话:“你写一段代码,编译一下能通过,半个小时过去了;编译一下没通过,半天就过去了。”在这种情况下,系统出错的概率也逐步增长,这让开发人员苦不堪言。感觉现在很多公司招实习生都是这种感觉。
2007年年底的时候,研发部空降了一位从硅谷来的高管——空闻大师。他是一位温厚的长者,他告诉我们一切要以稳定为中心,所有影响系统稳定的因素都要解决掉。例如:每做一个日常修改,都必须对整个系统回归测试一遍;多个日常修改如果放在一个版本中,要是一个功能没有测试通过,整个系统都不能发布。我们把这个叫做“火车模型”,即任何一个乘客没有上车,都不许发车。这样做最直接的后果就是火车一直晚点,新功能上线更慢,我们能明显感觉到业务放的不满,压力非常大。
现在回过头来看,其实我们并没有理解背后的思路。正是在这种要求下,我们不得不开始改变些东西,例如:把回归测试日常化,每天晚上都跑一遍整个系统的回归。
另外,在这种要求下,我们不得不对这个超级复杂的系统做肢解和重构,其中复用性最高的一个模块:用户信息模块开始拆分出来,我们叫它UIC(User Information Center)。在UIC中,它只处理最基础的用户信息操作,例如getUserById、getUserByName等。
在另一方面,还有两个新兴的业务对系统基础功能的拆分也提出了要求。在那时候,我们做了淘宝旅行(trip.taobao.com)和淘宝彩票(caipiao.taobao.com)两个新业务,这两个新业务在商品的展示和交易的流程上都跟主站的业务不一样,机票是按照航班信息展示的,彩票是按照双色球、数字和足球的赛程来展示的。但用到的会员功能和交易功能是与主站差不多的,当时做起来很纠结,因为如果在主站中做,会有一大半跟主站无关的东西,如果重新做一个,会有很多重复建设。
最终我们决定不再给主站添乱了,就另起炉灶做了两个新的业务系统,从查询商品、购买商品、评价反馈、查看订单这一整个流程都重新写了一套。现在在“我的淘宝”中查看交易记录,还能发现“已买到的宝贝”中把机票和彩票另外列出来了,他们没加入到普通订单中。
当时如果已经把会员、交易、商品、评价这些模块都拆分出来,就不用什么都重做一遍了。

到2008年初,整个主动系统(有了机票、彩票系统之后,把原来的系统叫做主站)的容量已经达到了瓶颈,商品数在1亿个以上,PV在2.5亿个以上,会员数超过了5000万个。这时Oracle的连接池数量都不够用了,数据库的容量到了极限,即使上层系统加机器也无法继续扩容,我们只有把底层的基础服务继续拆分,从底层开始扩容,上层才能扩展,这才能容纳未来三五年的增长。
于是我们启动了一个更大的项目,即把交易这个核心业务模块拆分出来。
原来的淘宝交易除了跟商品管理耦合在一起,还在支付宝和淘宝之间转换,跟支付宝耦合在一起,这会导致系统很复杂,用户体验也很不好。我们把交易的底层业务拆分出来,叫交易中心(TradeCenter,TC),所谓底层业务,就如创建订单、减库存、修改订单状态等原子型的操作;交易的上层业务叫交易管理(TradeManager,TM)例如拍下一件普通商品要对订单、库存、物流进行操作,拍下虚拟商品不需要对物流进行操作,这些在TM中完成。
3.业务模块化
类目属性、用户中心、交易中心,随着这些模块逐步拆分和服务化改造,我们在系统架构方面也积累了不少经验。到2008年年底就做了一个更大的项目,把淘宝所有的业务都模块化,这是继2004年从LAMP架构到Java架构之间的第二次脱胎换骨。
我们对这个项目取了一个很霸气的名字——“五彩石”(女娲炼石补天用的石头)。这个系统重构的工作非常惊险,有人称为“给一架高速飞行的飞机换发动机”。他们把淘宝的系统拆分成了如下架构。
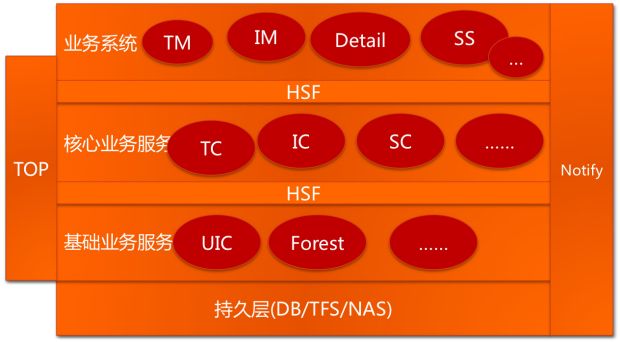
其中,UIC和Forest在上文已说过,TC、IC、SC分别是交易中心(Trade Center)、商品中心(Item Center)、店铺中心(Shop Center),这些中心级别的服务只提供原子级的业务逻辑,如根据ID查找商品、创建交易、减少库存等操作。
再往上一次是业务系统TM(Trade Manager,交易业务)、IM(Item Manager,商品业务)、SM(Shop Manager,后来改名叫SS,即Shop System,店铺业务)、Detail(商品详情)。
拆分之后,系统之间的交互关系变得非常复杂。
系统这么拆分的好处显而易见,拆分之后每个系统可以单独部署,业务简单,方便扩容;有大量可重用的模块便于开发新的业务;能够做到专人专事,让技术人员更加专注于某一个领域。
这样要解决的问题也很明显,拆分后,系统之间还是必须要打交道的,越往底层的系统,调用它的客户越多,这要求底层系统必须具有超大规模的容量和非常高的可用性。
另外,拆分之后的系统如何通信?这里需要两种中间件系统,一种是实时调用的中间件(淘宝的HSF,高性能服务框架),一种是异步消息通知的中间件(淘宝的Notify)。另外,一个需要解决的问题是用户在A系统登录后,到B系统的时候,用户的登录信息怎么保存?这又设计一个Session框架。再者,还有一个软件工程方面的问题,这么多层的一套系统,怎么去测试它?
二. 中间件
1.HSF
其实互联网网站发展过程类似于超市经营(此处省略超市销售收银的例子,可以想象下沃尔玛排队购物付款的场景吧),只是在技术层面用其他名词来表达而已,例如:有集群、分工、负载均衡、根据QoS分配资源等。
集群:所有收银员提供的都是收银功能,每个收银员都可以完成收款,可以认为所有的收银员构成了一个集群。互联网集群会受限于调度、数据库、机房等。
分工:收银员和打扫卫生的人分开,这种分工容易解决,而这种分工在互联网中是一项重要而复杂的技术,涉及的主要有按功能和数据库的不同拆分系统等。如何拆分和拆分后如何交互是需要面临的两个挑战。隐藏会有高性能通信框架、SOA平台、消息中间件、分布式数据层等基础产品的诞生。
负载均衡:让每个收银台排队差不多长,设立小件通道、团购通道、VIP通道等,这些都可认为是集群带来的负载均衡的问题,从技术层面上实现自然比生活中复杂得多。
根据QoS(Quality of Service,服务质量)分配资源:部分员工仅在晚上加班的机制在生活中不难实现,但对互联网应用而言,就是一件复杂而且极具挑战的事。
而且生活中面对用户增长的情况下,想出这些招应该不难。不过要掌握以上四点涉及的技术就相当复杂了,而且互联网中涉及的其他很多技术还没有在这个例子中展现出来。例如缓存、CDN等优化手段;运转状况监测、功能降级、资源劣化、流控等可用性手段;自建机房、硬件组装等成本控制手段。因此,构建一个互联网网站确实是不容易的,技术含量十足,当然,经营一家超市也不简单。
服务拆分之后,如何取得我需要的服务呢?
在“电视机”上,把每个集群能提供的服务显示出来。你不需要关心哪个人为你服务,当你有需要的时候,头顶的电视机会告诉你哪个服务在哪个区域。当你去到这个区域时,系统会给你找到一个最快的服务通道。
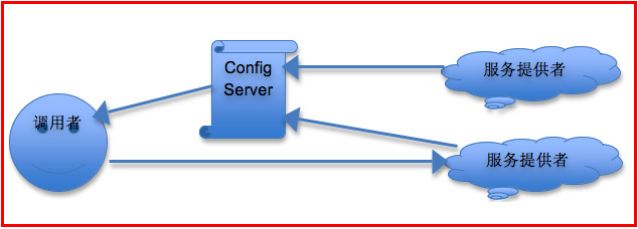
这就是HSF(High-Speed Service Framework)的设计思想:
服务的提供者启动时通过HSF框架向ConfigServer(类似超市的电视机)注册服务信息(接口、版本、超时时间、序列化方式等),ConfigServer上定义了所有可供调用的服务(同一个服务也可能有不同的版本);
服务调用者启动时向ConfigServer注册对哪些服务感兴趣(接口、版本),当服务提供者的信息变化时,ConfigServer向赶兴趣的服务调用者推送新的服务信息列表;调用者在调用时则根据服务信息的列表直接访问相应的服务提供者,无须经过ConfigServer。
我们注意ConfigServer并不会把服务提供者的IP地址推送给服务的调用者,HSF框架会根据负载状况来选择具体的服务器,返回结果给调用者,这不仅统一了服务调用的方式,也实现了“软负载均衡”。平时ConfigServer通过和服务提供者的心跳来感应服务提供者的存活状态。
在HSF的支持下,服务集群对调用者来说是“统一”的,服务之间是“隔离”的,这保证了服务的扩展性和应用的统一性。再加上HSF本身提供的“软负载均衡”,服务层对应用层来说就是一片“私有云”了。
HSF框架以SAR包的方式部署到Jboss、Jetty或Tomcat下,在应用启动时,HSF(High-Speed Service Framework,在开发团队内部有一些人称HSF为“好舒服”)服务随机启用。HSF旨在为淘宝的应用提供一个分布式的服务框架,HSF从分布式应用层面以及统一的发布/调用方式层面为大家提供支持,更容易地开发分布式应用或使用公用功能模块,而不用考虑分布式领域中的各种细节技术,例如:远程通讯、性能损耗、调用的透明化、同步异步调用的问题。
2.Notify
HSF解决了服务调用的问题,我们再提出一个很早就说过的问题:用户在银行的网关付钱后,银行需要通知到支付宝,但银行的系统不一定能发出通知;如果通知发出了,不一定能通知到;如果通知到了,不一定不重复通知一遍。
这个状况在支付宝持续了很长时间,非常痛苦。支付宝从淘宝剥离出来时,淘宝和支付宝之间的通信也面临同样的问题,支付宝架构师鲁肃提出用MQ(Message Queue)的方式来解决这个问题,我负责淘宝这边读取消息的模块。但消息数量上来后,常常造成拥堵,消息的顺序也会出错,系统挂掉消息也会挂掉。
然后鲁肃提出做一个系统框架上的解决方案,把要发出的通知存到数据库中,如果实时发送失败,再用一个时间程序来周期性地发送这些通知,系统记录下消息中间状态和时间戳,这样就保证了消息一定能发出,也一定能通知到,且通知带有时间顺序,甚至可以实现失去性的操作。
(PS:这个技术感觉以前做Android类似微信的随手拍软件时非常适用)
在“千岛湖”项目和“五彩石”项目后,淘宝系统拆分成了很多个,他们之间也需要类似的通知。例如,拍下一件商品,在交易管理系统中完成时,它需要通知商品管理系统减少库存,同时旺旺服务系统发送旺旺提醒,通知物流系统上门取货,通知SNS系统分享订单,通知公安局的系统这是骗子等等。
用户一次请求,在底层系统可能产生10次的消息通知。这一大堆的通知信息是异步调用的(如果同步,系统耦合在一起就达不到拆分的目的),这些消息通知需要一个强大的系统提供支持,从消息的数量级上看,比支付宝和淘宝之间的消息量又上了一个层次,于是按照类似的思路,一个更加强大的消息中间件系统就诞生了,它的名字叫做Notify。
Notify是一个分布式的消息中间件系统,支持消息的订阅、发送和消费,其架构图如下所示:
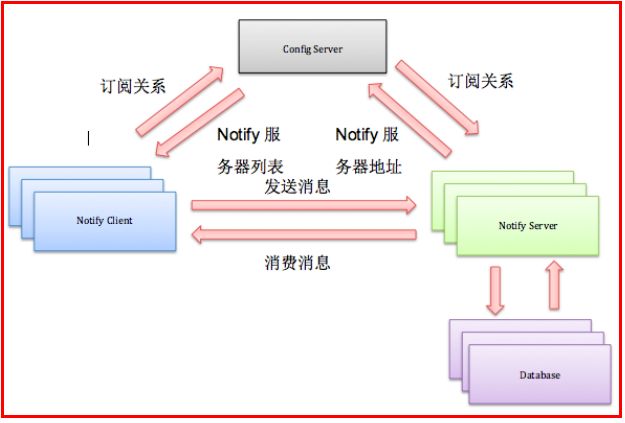
NotifyServer在ConfigServer上注册消息服务,消息的客户端通过ConfigServer订阅消息服务。某个客户端调用NotifyServer发送一条消息,NotifyServer负责把消息发送到所有订阅这个消息的客户端(参照HSF图)。
为了保证消息一定能发出,且对方一定能收到,消息数据本身就需要记录下来,这些信息存放在数据库中。由于消息具有中间状态(已发送、未发送等),应用系统通过Notify可以实现分布式事物——BASE(基本可用Basically Available、软状态Soft State、最终一致Eventually Consistent)。
NotifyServer可以水平扩展,NotifyClient也可以水平扩展,数据库也可以水平扩展。从理论上讲,这个消息系统的吞吐量时没有上限的,现在Notify系统每天承载了淘宝10亿次以上的消息通知。
下图展示了创建一笔交易后,TC(交易中心)向Notify发送一条消息,后续Notify所完成的一系列消息通知。
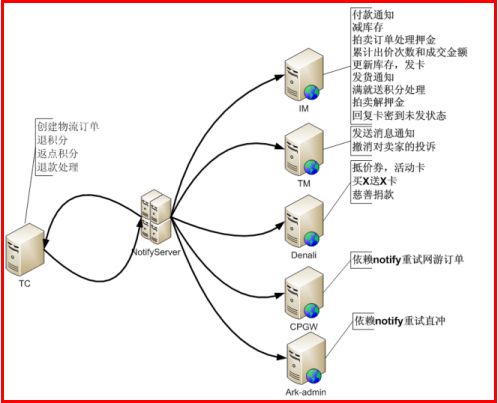
3.TDDL
有了HSF和Notify的支持,在应用级别中,整个淘宝网的系统可以拆分了,还有一个制约系统规模的更重要的因素就是数据库,也必须拆分。
前面讲过淘宝很早就对数据进行过分库的处理,上层系统连接多个数据库,中间有一个叫做DBRoute的路由来对数据进行统一访问。DBRoute对数据进行多库的操作、数据的整合,让上层系统像操作一个数据库一样操作多个库。随着数据量的增长,对于库表的分发有了更高的要求。例如,你的商品数据到了百亿级别时,任何一个库都无法存放了,于是分成2个、4个…1024个、2048个。分成这么多,数据能存放了,那怎么查询它?
这时候,数据查询的中间件就要能够承担这个重任了,它对上层来说,必须像查询一个数据库一样来查询数据,还要想查询一个数据库一样快(每条查询在几毫秒内完成),TDDL就承担了这样一个工作。
另外,加上数据的备份、复制、主备切换等功能,这一套系统都在TDDL中完成。在外面有些系统也用DAL(数据访问层)这个概念来命名这个中间件。TDDL实现了下面三个主要的特性:
1).数据访问路由——将针对数据的读写请求发送到最适合的地方
2).数据的多向非对称复制——一次写入,多点读取
3).数据存储的自由扩展——不再受限于单台机器的容量瓶颈与速度瓶颈,平滑迁移
下图展示了TDDL所处的位置:

大家逐渐发现,如果按照业务的发展规模和速度,那么使用高端存储和小型机的Oracle存储的成本将难以控制,于是降低成本就成了必然。如何能够在不影响业务正常发展的前提下,解决成本问题呢?
“对一部分数据库使用MySQL”,DBA们的决策是这样,于是分布式数据层的重担就落到了华黎的头上。当时的需求如下:对外统一一切数据访问、支持缓存和文件存储系统、能够在Oracle和MySQL之间自由切换、支持搜索引擎。
那么,如何实现分布式Join(连接)?(跨节点后简单Join就会变成M*N台机器的合并,代价太大)如何实现高速多维度查询?如何实现分布式事务?
于是动手我们自己做,名字叫Taobao Distributed Data Layer(TDDL,外号“头都打了”),学习开源的Amoeba Proxy。这就是TDDL 1.0时代。
粗略统计下来,TDDL已经走过了4年时间,满足了近700个业务应用的使用需求。其中有交易商品评价用户等核心数据,也有不那么有名的中小型应用。量变产生质变,如何能够更好地帮助这些业务以更低的成本完成业务需求,将成为数据层未来最重要的挑战。
最后希望文章对你有所帮助,如果文章有不足或错误的地方,还请海涵!文章写到此处,感觉读后感还是会应该以精简为主,下次写书籍读后感尽量写成一篇,而不是大量的摘抄原文。希望大家购买原书看看,非常不错~
(By:Eastmount 2015-6-10 半夜1点 http://blog.csdn.net/eastmount/)