Android逆向之旅---Android应用的汉化功能(修改SO中的字符串内容)
一、前言
今天我们继续来讲述逆向的知识,今天我们来讲什么呢?我们在前一篇文章中介绍了关于SO文件的格式,今天我们继续这个话题来看看如何修改SO文件中的内容,看一下我们研究的主题:
需求:想汉化一个Apk
思路:汉化,想必大家都了解,老外开发的一个游戏,结果他不支持中文,那么我们就需要做一下汉化,那么我们知道汉化的工作其实很简单,就是替换Apk中英文的字符串位置,那么我们可以反编译Apk..得到smail文件,然后直接找到需要汉化的字符串位置,然后修改成对应的中文即可。这个倒是很简单。这里就不详细说明了,但是现在问题变得有点复杂,就是有些apk,他把字符串放到了底层,也就是so文件中,那么问题就变的伤心了,我需要去修改so中的内容了。这时候我们不能像修改smail文件那么搞了,因为底层都是指针操作字符串,而且还涉及到字符串的地址。所以我们这时候需要了解so文件的格式,才能做相应的修改。所以大家需要先来看这篇文章才能继续我们今天的课题:
http://blog.csdn.net/jiangwei0910410003/article/details/49336613
二、准备工作
我们了解了SO的文件格式,也手动的写了一个工具来解析他,那么我们现在如果想修改一个字符串的内容,还需要一些准备。
需要两个工具:
1、010Editor:查看16进制的工具,比UE轻了很多,也很好用
下载地址:http://pan.baidu.com/s/1qWEbuHY
2、IDA 6.6 Pro:这个工具太出名了,在逆向领域中堪比Android中的AndroidStudio.没有他的话,逆向是难上加难,当然,这个工具也是我们日后介绍逆向领域必备的技能,网上也有相关工具的说明书,这个工具学起来不难,但是一定要学会使用
下载地址:http://pan.baidu.com/s/1pJ28eoz
3、NDK:这个工具想必大家也不陌生了,我们后面需要编译so文件,所以需要用到他,关于如何配置NDK的话,看这篇文章:
http://blog.csdn.net/jiangwei0910410003/article/details/17710243
下载地址:http://pan.baidu.com/s/1dDwMRuh
有了这两个三具我们还不够,我们还需要了解一个常识:
我们在Java中不会接触到指针的概念,但是用IDA分析so的时候,就是汇编指令,所以都是地址,我们在学习C的时候,知道一句话:地址就是指针,指针就是地址,所以我们需要了解指针的一点知识,我们在编写C程序的时候,代码中定义一个字符串:
char *str = "Hello World";str就是一个指针,指向Hello World中的首个字符,也是这个字符串在内存中的首地址,但是这里我们需要了解的是,这个地址不是绝对地址,而是相对地址。是绝对地址减去偏移值。
三、技术原理
上面的准备工作做完了,下面我们来看看具体思路吧:
我们如果做汉化工作的话,其实原理打搅都了解,就是反编译Apk,然后将其英文改称中文即可。如果Apk的字符串都定义在string.xml中,或者是在java层代码中的话,那么就简单了,我们只需要用apktools工具修改smail文件和添加中文的string.xml就可以了。但是我今天不是重点来说这个内容,因为这个内容没难度。大家都可以实现的,今天我们要说的是有难度的,加入字符串定义在native层中,也就是在so文件中,我们该怎么办?
通过前一篇的so文件的格式详解之后,我们知道字符串都存在哪里。
下面我们就来通过一个案例来分析一下如何修改so中的字符串内容,这个案例的native层我们不准备自己手写了,我们用NDK中的一个demo就可以了:
![]()
在NDK的这个目录下,我们看一下C++的代码:
/*
* Copyright (C) 2009 The Android Open Source Project
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*
*/
#include <string.h>
#include <jni.h>
/* This is a trivial JNI example where we use a native method
* to return a new VM String. See the corresponding Java source
* file located at:
*
* apps/samples/hello-jni/project/src/com/example/hellojni/HelloJni.java
*/
jstring
Java_com_example_hellojni_HelloJni_stringFromJNI( JNIEnv* env, jobject thiz )
{
return (*env)->NewStringUTF(env, "Hello from JNI !");
}
上层的Java代码:
package com.example.hellojni;
import android.app.Activity;
import android.os.Bundle;
import android.view.View;
import android.view.View.OnClickListener;
import android.widget.Button;
public class HelloJni extends Activity{
@Override
public void onCreate(Bundle savedInstanceState){
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
final Button btn = (Button)findViewById(R.id.btn);
btn.setOnClickListener(new OnClickListener(){
@Override
public void onClick(View arg0) {
String str = stringFromJNI();
btn.setText(str);
}});
}
public native String stringFromJNI();
public native String unimplementedStringFromJNI();
static {
System.loadLibrary("hello-jnis");
}
}
我们看到native层的字符串是:Hello from JNI !,那么我们现在来修改这个字符串内容。
四、技术实现
这时候我们就需要用到上面说到的那个强大的工具:IDA了,打开so文件,很简单的,界面如下:
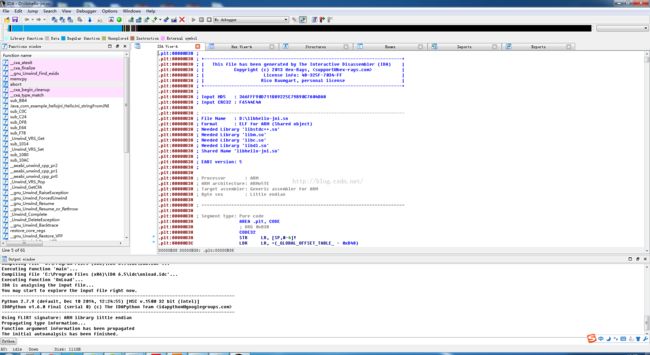
这里有很多窗口的,所以IDA工具很强大,我们需要慢慢的学习,还有各种快捷键的使用,都是一门学问。
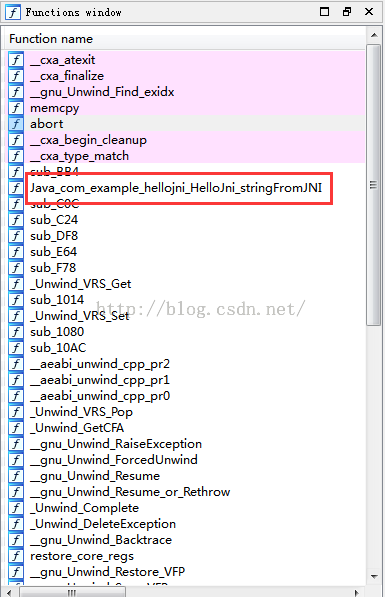
在Functions window窗口中我们可以看到我们的native函数,如果太多的话,我们可以用Ctrl+F搜索。然后我们双击这个函数,在IDA View窗口中就可以看到这个函数的汇编代码了:
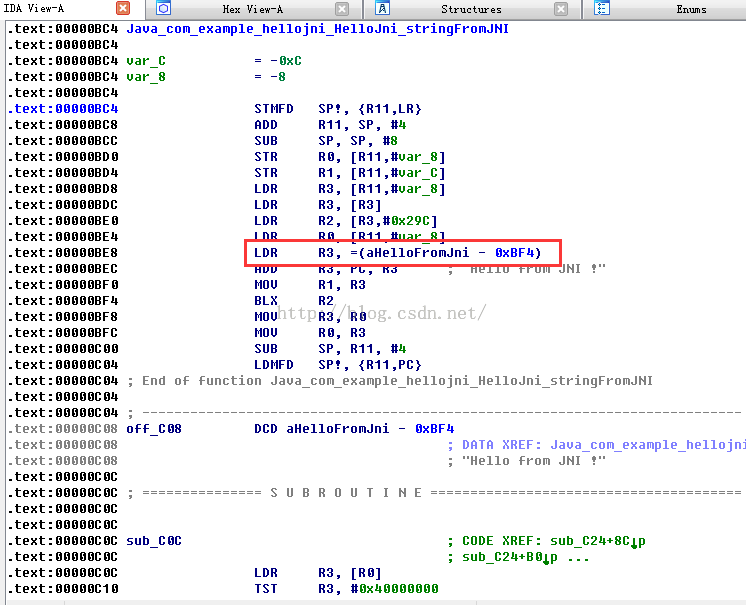
关于汇编指令,这里也不多解释了,大学里面都学过了,但是可能都忘了,所以还得复习一下。这里我们看到了,那个字符串的地址:aHelloFromJni - 0xBF4,0xBF4是偏移地址,这个aHelloFromJni应该是一个符号,所以我们双击跳到这个字符串的绝对地址。
这里又要在做一个插曲了,就是在详细介绍一下elf文件中的各个段的信息:
我们在IDA中可以使用Shift+F7快捷键打开段窗口:
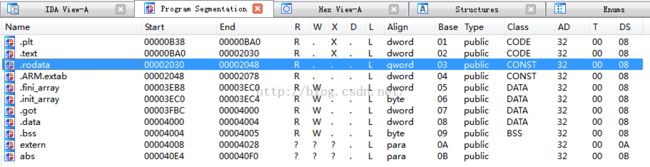
当然我们在IDA View窗口中使用Ctrl+S快捷键:
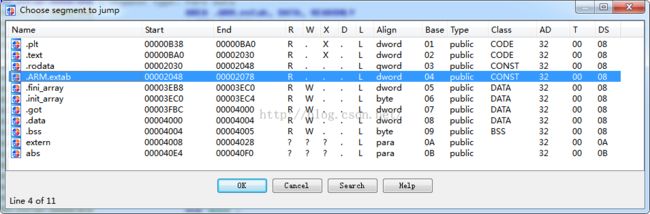
第一、介绍ELF文件的各个段信息
那么下面就来看看这些段的信息:
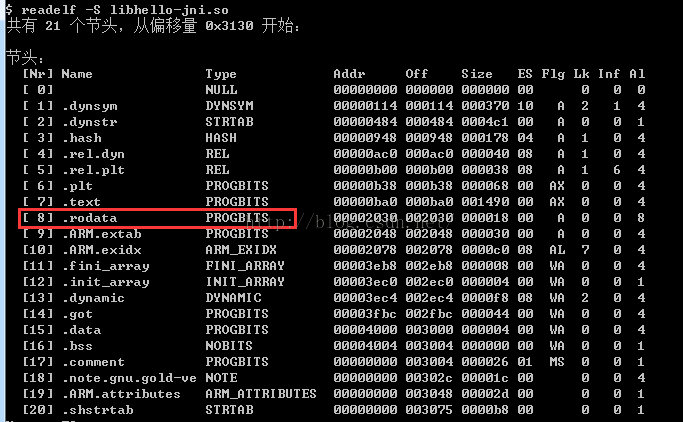
ELF文件主要由文件头(ELF header)、代码段(.text)、数据段(.data)、.bss段、只读数据段(.rodata)、段表(section table)、符号表(symtab)、字符串表()、重定位表(.rel.text)如下图所示: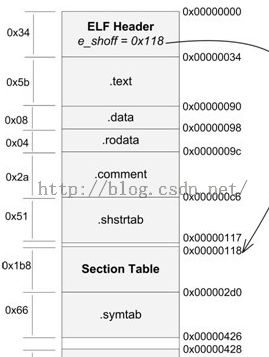
代码段与数据段分开的原因:
1.对进程来说,数据段是可读写的,指令段是只读的。这样可以防止程序指令被改写。
2.指令区与数据区的分离有助于提高程序的局部性,有助于对CPU缓存命中率的提高。
3.当系统运行多个改程序的副本的时候,他们对应的指令都是一样的,此时内存只需要保留一份改程序的指令即可。当然,每个副本进程的数据区域是不一样的,他们是进程私有的
结合下图进行分析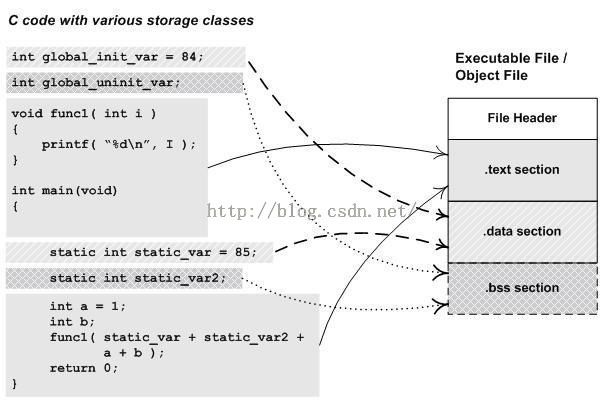
如上图所示,
1、.text段
一般C语言编译后的执行语句都编译成机器代码,保存在.text段。
2、.data段
已经初始化的全局变量和局部静态变量(虽然默认会初始化为0,或者手动初始化为0,都没有必要在数据段分配空间,直接放在.bss段,就默认值为0了)都保存在.data段。
大体来说,该section包含了在内存中的程序的初始化数据;data段包含三个部分:heap(堆)、stack(栈)和静态数据区。即.data还会存放其他类型的数据,比如局部变量。
数据段只是存放数据,变量名存放在字符串表中。
3、.bss段
未初始化的全局变量和局部静态变量都保存在.bss段。
大体来说该section包含了在内存中的程序的未初始化的数据。
由于程序加载(一般是指main之前)时,bss会被操作系统清零,所以未赋初值或初值为0的全局变量都在bss。.bss段只是为未初始化的全局变量和局部静态变量预留位置而已,它并没有内容,所以它在文件中也不占据空间,这样可减少目标文件体积。
但程序运行时需为变量分配内存空间,故目标文件必须记录所有未初始化的静态分配变量大小总和(通过start_bss和end_bss地址写入机器代码)。当加载器(loader)加载程序时,将为BSS段分配的内存初始化为0。
4、.rodata段
存放只读数据,一般是程序里面的只读变量(如const修饰的变量),以及字符串常量(不一定,也可能放在.data中)。
5、.got段
GOT(Global Offset Table)表中每一项都是本运行模块要引用的一个全局变量或函数的地址。可以用GOT表来间接引用全局变量、函数,也可以把GOT表的首地址作为一个基 准,用相对于该基准的偏移量来引用静态变量、静态函数。由于加载器不会把运行模块加载到固定地址,在不同进程的地址空间中,各运行模块的绝对地址、相对位 置都不同。这种不同反映到GOT表上,就是每个进程的每个运行模块都有独立的GOT表,所以进程间不能共享GOT表。
6、.plt段
过程链接表用于把位置独立的函数调用重定向到绝对位置。通过 PLT 动态链接的程序支持惰性绑定模式。每个动态链接的程序和共享库都有一个 PLT,PLT 表的每一项都是一小段代码,对应于本运行模块要引用的一个全局函数。程序对某个函数的访问都被调整为对 PLT 入口的访问。
每个 PLT 入口项对应一个 GOT 项,执行函数实际上就是跳转到相应 GOT 项存储的地址,该 GOT 项初始值为 PLTn项中的 push 指令地址(即 jmp 的下一条指令,所以第 1 次跳转没有任何作用),待符号解析完成后存放符号的真正地址。动态链接器在装载映射共享库时在 GOT 里设置 2 个特殊值:在 GOT+4( 即 GOT[1]) 设置动态库映射信息数据结构link_map 地址;在 GOT+8(即 GOT[2])设置动态链接器符号解析函数的地址_dl_runtime_resolve。
每一个外部定义的符号在全局偏移表 (Global Offset Table GOT)中有相应的条目,如果符号是函数则在过程连接表(Procedure Linkage Table PLT)中也有相应的条目
下面来看张图就了解了.got段和.plt段的关系:
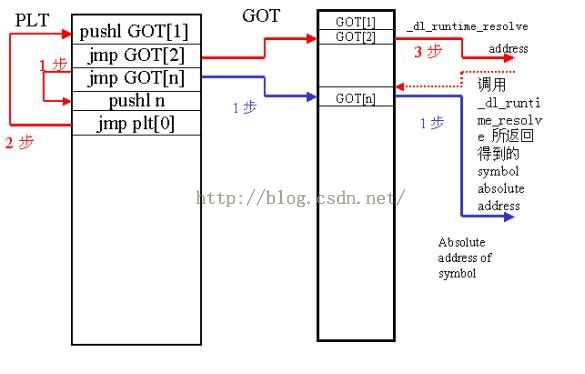
这个在我们之前说到Hook技术就是用着两个段来实现的。只要修改需要hook的函数地址,插入我们hook的函数,执行之后,再回来就可以了,这里只要修改.got和.plt表就可以了,相关知识大家去网上搜一下吧。这里就不在解释了。
第二、修改字符串
解释了上面的各个段详情之后,我们看到Hello from JNI !这个字符串是个常量,所以放在了.rodata段中,那么我们现在修改这个字符串,比如我们要修改成 "jiangwei",这里该怎么弄呢?很简单,直接修改就可以了,但是我们不用IDA来修改,因为IDA修改起来特麻烦,我需要用010Editor工具来做修改,简单。用这个工具打开so文件:
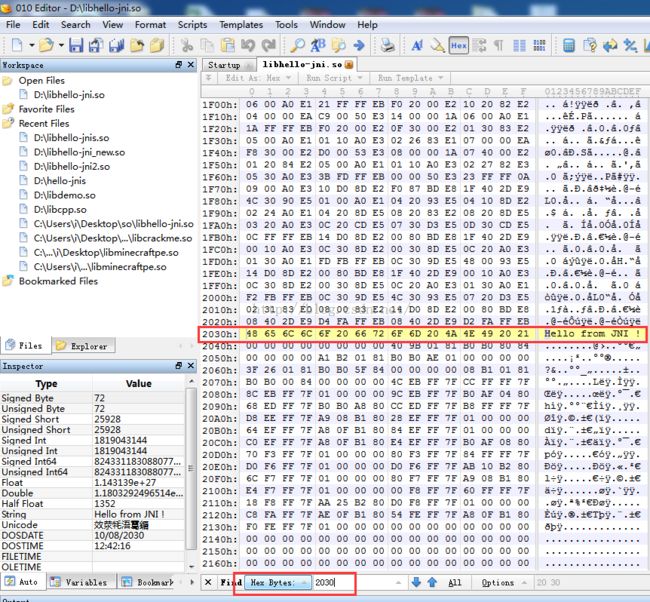
因为我们在IDA中知道这个字符串的地址是:0x2030,所以这里使用Ctrl+G快捷键直接跳转到这个地址就可以了,我们看到了这个字符串内容:我们直接修改:

但是这里需要注意的是:“jiangwei"这个字符串比”Hello from JNI !"这个字符串短,所以我们不能改变原来字符串的长度,所以需要用空字符串来补充。这里我们可以看到在修改字符串的时候我们会发现有这些问题:
遵从一个原则:在修改文件的内容的时候,一定不能影响到其他内容的地址,这样会导致其他信息的偏移值发生变化之后,代码就会异常报错的。有了这个原则,我们就有以下集中情况以及处理方法:
1、如果修改的字符串的长度和源字符串的长度相等,那么简单,直接替换就可以
2、如果修改的字符串的长度比源字符串的长度短,那么我们需要用空字符串进行补齐
3、如果修改的字符串的长度比源字符串的长度要长,那么我们就需要这么做了:
1) 在.rodata段、.data段、.string段找到一块空地,在哪里添加一个字符串,这里的so文件,我们看到没有太多的空地,我们看一下下面的这个so文件:
![]()
如何找到这些段,很简单,用IDA打开so文件,用Ctrl+S搜索,到这个段得到起始地址,然后在用010Editor打开,我们看到有一大片空字符串的地方,这就是空地,我们可以在这里添加一个字符串,添加完之后,我们还需要做一件事:
就是要修改源字符串在代码中的指针(相对地址),如何在文件中找到这个地址呢?很简单:
![]()
我们用绝对地址减去偏移值就可以了:0x2030 - 0xBF4 = 0x143C
但是这里又需要注意一个问题,就是高位和地位需要倒叙,这个是因为内存地址都是从地位到高位开始分配地址的。
所以倒叙之后就是0x3C14,这个就是源字符串的指针,在010Editor中查找一下:

然后用同样的方法来计算出新字符串的指针,然后替换即可。
但是我们看到案例的so文件没有空地,怎么办呢?这时候我们就需要自己添加一个段来充当空白地了。
第三、添加新的段(Section)
这个就引出了我们今天的核心内容,如何在so文件中添加一个自己的段信息?
如果要添加一个段的话,我们需要注意哪些问题,步骤是什么?
1、添加段的内容肯定不能影响到以前的信息内容,特别是偏移值,那么按照这个原则的话,我们只能在文件的末尾添加一个段了。那么这时候新加的段的位置找到了。
2、添加一个段我们需要做哪些工作?
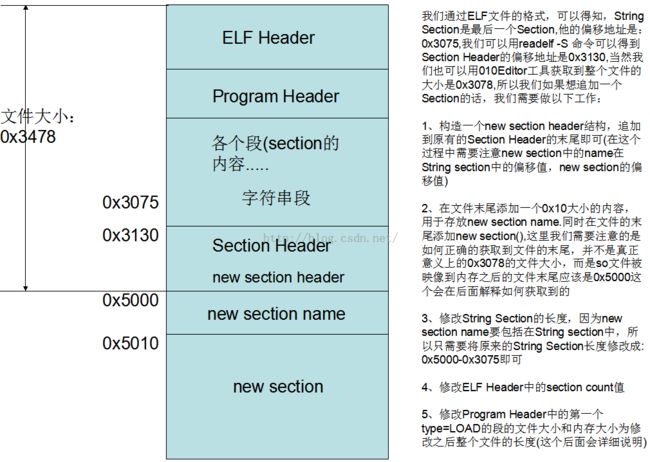
1)、构造一个new section header结构,追加到原有的Section Header的末尾即可(在这个过程中需要注意new section中的name在String section中的偏移值,new section的偏移值)
2)、在文件末尾添加一个0x10大小的内容,用于存放new section name.同时在文件的末尾添加new section(),这里我们需要注意的是如何正确的获取到文件的末尾,并不是真正意义上的0x3078的文件大小,而是so文件被映像到内存之后的文件末尾应该是0x5000这个会在后面解释如何获取到的
3)、修改String Section的长度,因为new section name要包括在String section中,所以只需要将原来的String Section长度修改成:
0x5000-0x3075即可
4)、修改ELF Header中的section count值
5)、修改Program Header中的第一个type=LOAD的段的文件大小和内存大小为修改之后整个文件的长度(这个后面会详细说明)
有了上面的步骤下面我们就好办了。直接上代码吧:
第一步:添加Section Header信息
/**
* 添加section header信息
* 原理:
* 找到String Section的位置,然后获取他偏移值
* 将section添加到文件末尾
*/
public static byte[] addSectionHeader(byte[] src){
/**
* public byte[] sh_name = new byte[4];
public byte[] sh_type = new byte[4];
public byte[] sh_flags = new byte[4];
public byte[] sh_addr = new byte[4];
public byte[] sh_offset = new byte[4];
public byte[] sh_size = new byte[4];
public byte[] sh_link = new byte[4];
public byte[] sh_info = new byte[4];
public byte[] sh_addralign = new byte[4];
public byte[] sh_entsize = new byte[4];
*/
byte[] newHeader = new byte[sectionSize];
//构建一个New Section Header
newHeader = Utils.replaceByteAry(newHeader, 0, Utils.int2Byte(addSectionStartAddr - stringSectionOffset));
newHeader = Utils.replaceByteAry(newHeader, 4, Utils.int2Byte(ElfType32.SHT_PROGBITS));//type=PROGBITS
newHeader = Utils.replaceByteAry(newHeader, 8, Utils.int2Byte(ElfType32.SHF_ALLOC));
newHeader = Utils.replaceByteAry(newHeader, 12, Utils.int2Byte(addSectionStartAddr + newSectionNameLen));
newHeader = Utils.replaceByteAry(newHeader, 16, Utils.int2Byte(addSectionStartAddr + newSectionNameLen));
newHeader = Utils.replaceByteAry(newHeader, 20, Utils.int2Byte(newSectionSize));
newHeader = Utils.replaceByteAry(newHeader, 24, Utils.int2Byte(0));
newHeader = Utils.replaceByteAry(newHeader, 28, Utils.int2Byte(0));
newHeader = Utils.replaceByteAry(newHeader, 32, Utils.int2Byte(4));
newHeader = Utils.replaceByteAry(newHeader, 36, Utils.int2Byte(0));
//在末尾增加Section
byte[] newSrc = new byte[src.length + newHeader.length];
newSrc = Utils.replaceByteAry(newSrc, 0, src);
newSrc = Utils.replaceByteAry(newSrc, src.length, newHeader);
return newSrc;
}
这里我们需要详细介绍一下SectionHeader中的各个字段的含义了:
还是看那个pdf文档说的最详细了

1)、sh_name:这个字段是Section name,这个值一般保存在.strtab段中的,但是这个值是section name在.strtab段中的偏移值,所以值是:new section的起始地址减去String Section的偏移值
那么new section的起始地址是多少呢?
这个我们刚刚说过了,这个段是加载文件的末尾处的,所以new section的起始地址就是文件的总长度:0x3078
那String Section的偏移值是多少呢?这个也简单,因为我们在之前的一篇文章中介绍了如何解析elf文件
http://blog.csdn.net/jiangwei0910410003/article/details/49336613
那里我们解析出了所有的Section Header信息,然后我们在定位String Section在这个header列表中的位置即可,这个位置在elf文件的头部信息中有,就是这个字段:e_shstrndx
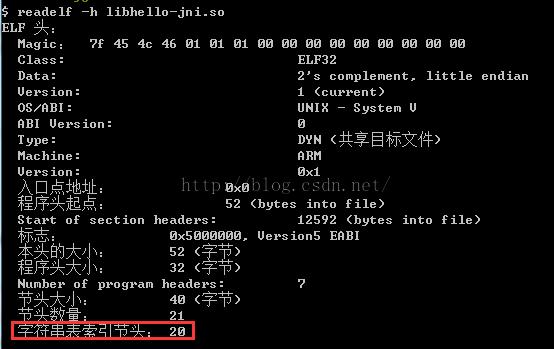
那么我们就可以找到String Section的偏移值了:0x3075
![]()
2)、sh_type:段的类型,这个字段我们需要把和设置的和.rodata段的类型相同即可,取值如下:
/****************sh_type********************/ public static final int SHT_NULL = 0; public static final int SHT_PROGBITS = 1; public static final int SHT_SYMTAB = 2; public static final int SHT_STRTAB = 3; public static final int SHT_RELA = 4; public static final int SHT_HASH = 5; public static final int SHT_DYNAMIC = 6; public static final int SHT_NOTE = 7; public static final int SHT_NOBITS = 8; public static final int SHT_REL = 9; public static final int SHT_SHLIB = 10; public static final int SHT_DYNSYM = 11; public static final int SHT_NUM = 12; public static final int SHT_LOPROC = 0x70000000; public static final int SHT_HIPROC = 0x7fffffff; public static final int SHT_LOUSER = 0x80000000; public static final int SHT_HIUSER = 0xffffffff; public static final int SHT_MIPS_LIST = 0x70000000; public static final int SHT_MIPS_CONFLICT = 0x70000002; public static final int SHT_MIPS_GPTAB = 0x70000003; public static final int SHT_MIPS_UCODE = 0x70000004;
3)、sh_flags:段的属性,这个字段的取值如下:
/*****************sh_flag***********************/ public static final int SHF_WRITE = 0x1; public static final int SHF_ALLOC = 0x2; public static final int SHF_EXECINSTR = 0x4; public static final int SHF_MASKPROC = 0xf0000000; public static final int SHF_MIPS_GPREL = 0x10000000;这个我们看到字段就知道每个属性是什么意思了,这里我们设置成可分配属性:ALLOC
4)、sh_addr:段被映像到内存中的首地址,也就是这个section的起始地址,也就是文件的末尾地址在加上section name的大小,看到代码,我们把section name大小设置成了0x10,也就说新加的section段的name长度不可超过16个字节,当然这个数值是可以改的,但是我感觉没必要了,因为一个section name没必要搞那么长。那么这里的值就是:文件的长度+0x10
5)、sh_offset:这个字段是值该段到文件开始位置的偏移值,这个值我们想一下就知道他的值和sh_addr的值应该一样的。
还有其他字段需要设置,但是这里没必要做解释了,所以就和.rodata段的值保持一致即可。这里就不再做介绍了。
上面就构造了一个Section Header了,那么这个头部加到哪里呢?肯定也是文件末尾处了,看上面的图就知道了:
第二步:添加New Section 的内容到文件末尾
这一步我们主要是添加一个空白的段在末尾处,大小我们这里设定为1000个字节。
/**
* 在文件末尾添加空白段+增加段名String
* @param src
* @return
*/
public static byte[] addNewSectionForFileEnd(byte[] src){
byte[] stringByte = newSectionName.getBytes();
byte[] newSection = new byte[newSectionSize + newSectionNameLen];
newSection = Utils.replaceByteAry(newSection, 0, stringByte);
//新建一个byte[]
byte[] newSrc = new byte[addSectionStartAddr + newSection.length];
newSrc = Utils.replaceByteAry(newSrc, 0, src);//复制之前的文件src
newSrc = Utils.replaceByteAry(newSrc, addSectionStartAddr, newSection);//复制section
return newSrc;
}
这里在添加顺便把Section name也添加进去了,那么长度就是1000+0x10个,位置是在文件的末尾。
第三步:修改String Section Header中的大小
因为我们新加的Section name在String Section中,所以我们还得修改一下String Section的大小了
/**
* 修改.strtab段的长度
*/
public static byte[] changeStrtabLen(byte[] src){
//获取到String的size字段的开始位置
int size_index = sectionHeaderOffset + (stringSectionInSectionTableIndex)*sectionSize + stringSectionSizeIndex;
//多了一个Section Header + 多了一个Section的name的16个字节
byte[] newLen_ary = Utils.int2Byte(addSectionStartAddr - stringSectionOffset + newSectionNameLen);
src = Utils.replaceByteAry(src, size_index, newLen_ary);
return src;
}
我们知道String Section Header中的sh_size字段是记录大小的,所以我们找到String Section Header然后修改这个字段的值就可以了,那么现在的String Section的大小是多大呢?

新的String Section的大小变成了,new section name的结束位置减去String Section的起始位置,也就是:
文件末尾+0x10 - 0x3075
![]()
我们需要把0xb8改成最新的值就可以了。这个sh_size字段也是好定位的。
首先知道String Section Header,然后替换sh_size位置的字节数即可。
第四步:修改elf头部中section的count数
这步就简单了,修改一下这个字段:e_shnum
/**
* 修改elf头部总的section的总数信息
*/
public static byte[] changeElfHeaderSectionCount(byte[] src){
byte[] count = Utils.copyBytes(src, elfHeaderSectionCountIndex, 2);
short counts = Utils.byte2Short(count);
counts++;
count = Utils.short2Byte(counts);
src = Utils.replaceByteAry(src, elfHeaderSectionCountIndex, count);
return src;
}
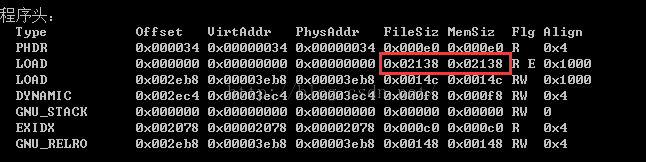
第五步:修改Program Header中第一个类型为LOAD的段的文件大小和内存映像的大小
这里需要修改的是第一个Type为LOAD的file_size和mem_size字段的大小为文件的总大小即可。下面会说道type为PT_LOAD的都会被加载到内存中。那么我们如果想把我们新加的段的内容加载内存中,这里需要修改一下file_size和mem_size为文件的总大小。
代码如下:
/**
* 修改Program Header中的信息
* 把新增的段内容加入到LOAD Segement中
* 就是修改第一个LOAD类型的Segement的filesize和memsize为文件的总长度
*/
public static byte[] changeProgramHeaderLoadInfo(byte[] src){
//寻找到LOAD类型的Segement位置
int offset = elfHeaderSize + programHeaderSize * firstLoadInPHIndex + programFileSizeIndex;
//file size字段
byte[] fileSize = Utils.int2Byte(src.length);
src = Utils.replaceByteAry(src, offset, fileSize);
//mem size字段
offset = offset + 4;
byte[] memSize = Utils.int2Byte(src.length);
src = Utils.replaceByteAry(src, offset, memSize);
//flag字段
offset = offset + 4;
byte[] flag = Utils.int2Byte(7);
src = Utils.replaceByteAry(src, offset, flag);
return src;
}
上面我们完成了工作,下面还需要来讲解一下一个重要的知识点,就是我们上面一直说到的文件末尾这个词?
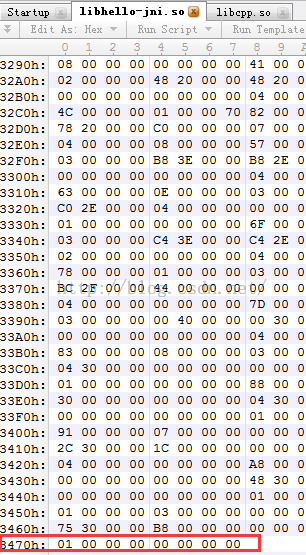
我在开始的时候就说了,这里的文件末尾不是真正意义上的文件末尾,比如这里的文件长度是:0x3478
这里的文件末尾指的是映像到内存中的字节大小?因为我们知道文件的大小和这个文件映像到内存中的大小是不一定相等的,因为映像到内存中是需要做很多操作的,比如最简单的就是页面对其工作,这个就会增加字节了,所以映像到内存的大小肯定是大于等于文件大小的。
那么我们该如何获取到这个文件映像到内存之后的大小呢?这里就需要先来了解一个知识点:
可执行文件和共享目标文件(动态链接库)是程序在磁盘中的静态存储形式;要执行一个程序,系统就要先把相应的可执行文件和共享目标文件装载到进程的地址空间中,这样就形成一个可运行进程的内存空间布局,称为进程镜像;一个已经装载完成的进程空间中会包含多个不同的段(Segment),比如,代码段、数据段、堆栈段,等等;
准备一个程序的内存镜像,大体上可以分为两个步骤:装载和链接;前者是把目标文件装载到内存中,后者是解析目标文件中的符号引用;
一个可执行文件及其依赖的共享目标文件被完全成功地装载到进程的内存地址空间中之后,这个可执行文件或共享目标文件中的程序头部表(Program Header Table)就是必须存在的、不可缺少的必需品,程序头部表是一个数组,数组中的每一个元素就称为一个程序头(Program Header),每一个程序头描述一个内存段(Segment)或者一块用于准备执行程序的信息;内存中的一个目标文件中的段包含一个或多个节;也就是ELF文件在磁盘中的一个或多个节可能会被映射到内存中的同一个段中;程序头只对可执行文件或共享目标文件有意义,对于其它类型的目标文件,该信息可以忽略;
p_type=PT_LOAD时,段的内容会被从文件中拷贝到内存中,如果p_memsz>p_filesz,则在内存中多出的存储空间中填0补充,即,段在内存中可以比在文件中占用更大空间;相反,p_filesz永远都不应该比p_memsz大,因为这样的话,在内存中就将无法完整地映射段的内容;在程序头部表中,所有PT_LOAD类型的程序头都按照p_vaddr的值做升序排列;
从上面的两段话可以看出我们看到两个知识点:
1、程序头中的p_type=PT_LOAD的时候,段的内容会被从文件中拷贝到内存中
2、所有PT_LOAD类型的程序头都按照p_vaddr的值做升序排列的
那么我们就好办了,我们只要获取到最后一个PT_LOAD的p_vaddr的值然后加上这个段的mem_size在做一下页面对其操作就可以得到内存中的末尾了。
关于页面对其的操作,网上有相关的资料,可以去搜一下,这里也不解释了。
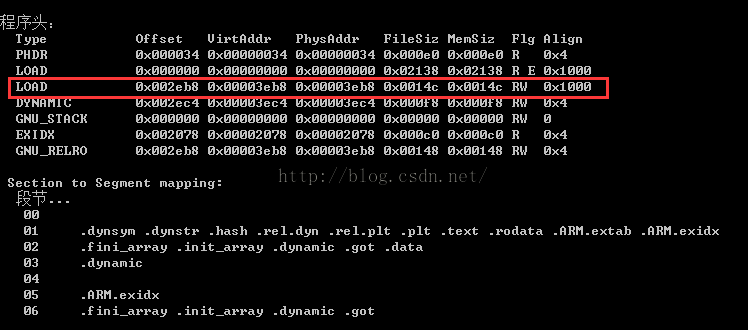
这里就是0x3EB8+0x14c对0x1000对其操作结果是:0x5000也就是上面我们说的文件末尾值了。
第四、验证结果
好了,上面我就做完了所有的工作,下面就将我们修改之后的so文件保存一下,然后用readelf工具验证一下:
1、验证elf的头部信息中的section变成22了
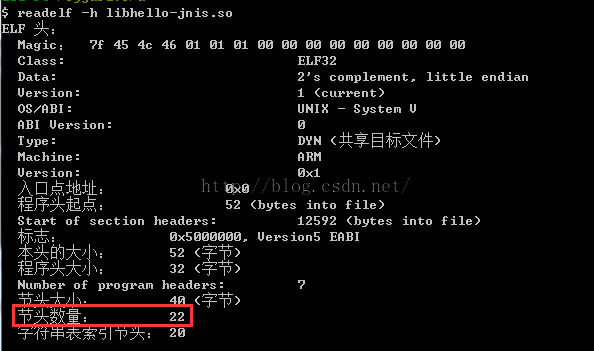
2、验证Section Header
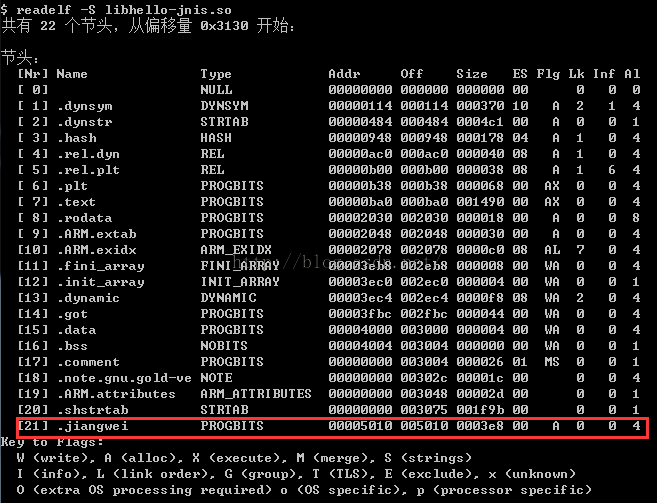
最后一个段是我们添加的
3、验证Program Header信息

新加的Section能够加载到内存中。
我们同样也可以用IDA进行验证一下:
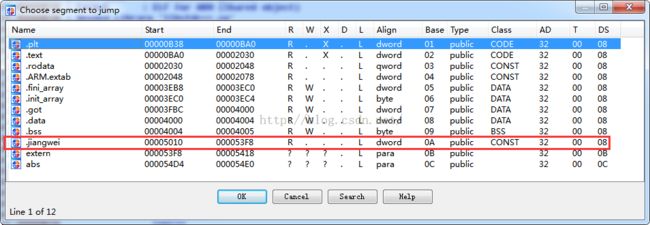
用010Editor查看一下:
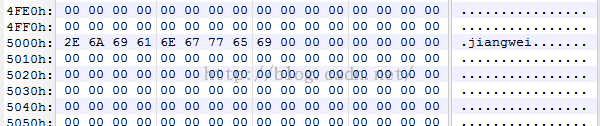
段名位置都是正确的,那么下面我们就来修改字符串吧,因为我们新加的段完全就是一个空白地,想怎么加就怎么加?
下面我们来修改一下字符串:

在0x5010出添加了修改的字符串,那么我还需修改一下指针:
修改之后的指针:0x5010-0xBF4 = 0x441c
倒叙之后就是0x1C44,我们替换一下源字符串的指针,上面说到了是:0x3C14

这就改好了,我们这时候可以用IDA进行验证一下:

可以看到我们修改应该是成功了。
Java版代码下载:http://download.csdn.net/detail/jiangwei0910410003/9204119
C++版代码下载:http://download.csdn.net/detail/jiangwei0910410003/9204139
但是最终的验证是集成到Android程序中测试:
测试Demo下载:http://download.csdn.net/detail/jiangwei0910410003/9207019
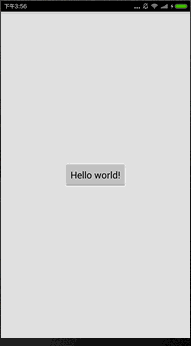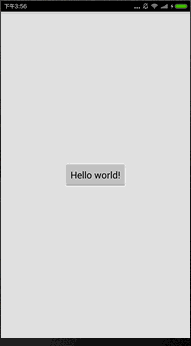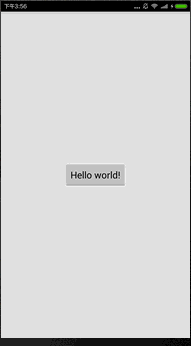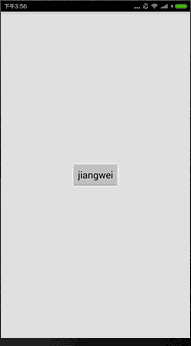
果然成功了。
第五、技术延展
我们这篇文章可能只是通过添加一个section来进行修改字符串的内容,其实有了添加段的知识之后,我们可以去给别人的so文件植入恶意代码了,而这段代码我们就可以放到我们新加的段中,然后在利用修改.got和.plt段的信息,干掉别人的so文件还是很简单的。但是呢,这个想法是初级的,我想到了,想必大家也都想到了,那么就有了防范之道了,比如他们对so加密,这会导致我们无法分析so文件了。那谈何修改so文件呢?或者是对so文件进行校验,一旦修改了,就不能运行,这些都是防御的方法。但是关于so加密的知识,我后面会详细介绍,所以说防御和逆向是相生相克的,永不停息的战争。
第六、知识梳理
这里我们就算是完成了汉化功能,有的人说?这不是忽悠人吗?这哪是汉化呀。就是修改so中的字符串内容呀。但是这里我说道了一个添加新段的方法,这个才是本文的核心,如果都能添加段了,那么替换中文又有何难呢?不过从这篇文章的篇幅来看,就知道这里的知识点真的很多?而且我可能还有遗漏的地方,下面就来总结一下我们这篇文章的思路把:
思路:
1、我们需要修改so文件中的字符串从而达到汉化效果,但是在在这个过程中我可能会遇到一些问题,就是我们修改的字符串的长度和修改之后的字符串的长度,因为我们要秉承着修改之后其他部分内容的偏移地址不能发生变化的原则,所以当要修改的字符串的长度大于源字符串的长度的话,我们就要做一些操作了,这里我们可以观察so中有没有空地,如果有空地而且空地的大小够用的话,那么问题就简单了,如果没有空地的话,那么就引出了我们今天的核心内容,自己加段。
2、在加一个段的时候,我们需要注意的哪些问题和具体步骤上面也都说了。我们还是遵照一个原则就是修改之后不能影响之前的内容的偏移值。所以就在文件的末尾添加,然后构造一个Section header,和追加一个空白的section即可。
3、修改完之后的so,我们需要校验一下,用readelf工具进行查看添加的段信息,或者IDA也是可以的。
技术点:
1、对elf文件的格式有了深刻的了解
2、对内存映像的概念有了深刻的了解
3、C语言中的字符串的指针如何修改
4、IDA工具的初步使用
5、.got和.plt段对hook的过程的作用
第七、总结
有了这篇文章的讲述,我们汉化一个游戏的话,那是轻松的话,而且汉化游戏也是一个赚钱之道。本人只是为了研究,并没有尽力去搞这些,所以就留个后人去赚大钱吧。其实说到最后,这篇文章主要介绍了如何在so中添加一个段,这个用处还是很大的,其实我们看了代码之后可以知道,我们只需要将段名和段的大小当做参数抽取出来的话,那么这个就是一个小工具了,输入:需要修改的so,新加的段名,新加的段的大小,输出就是修改之后的so文件了。后面我会继续分享逆向的相关知识,下一篇会介绍如何动态调试smail/dex/so。尽情期待~~
PS: 关注微信,最新Android技术实时推送