Machine Learning - XVI. Recommender Systems 推荐系统(Week 9)
http://blog.csdn.net/pipisorry/article/details/44850971
机器学习Machine Learning - Andrew NG courses学习笔记
Recommender Systems 推荐系统
{an important application of machine learning}
Problem Formulation 问题规划
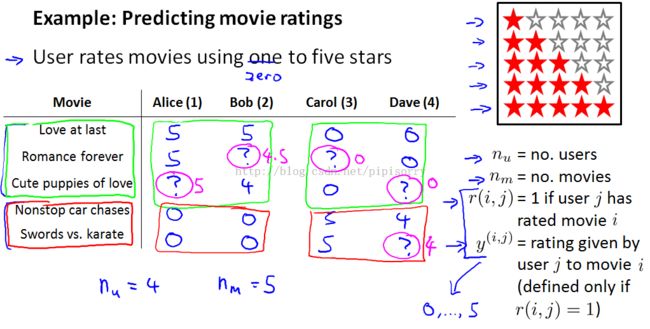
Note:
1. to allow 0 to 5 stars as well,because that just makes some of the math come out just nicer.
2. for this example, I have loosely 3 romantic or romantic comedy movies and 2 action movies.
3. to look through the data and look at all the movie ratings that are missing and to try topredictwhat these values of the question marks should be.
Content Based Recommendations基于内容的推荐
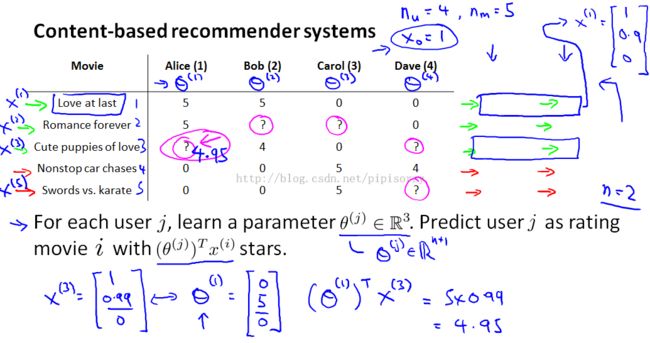
Note:
1. add an extra feature interceptor feature X0, which is equal to 1
2. set n to be the number of features, not counting this X zero intercept term so n is equal to two because we have two features x1 and x2
3. to make predictions, we could treat predicting the ratings of each user as aseparate linear regression problem. So specifically lets say that for each user j we are going to learn a parameter vector theta J which would be in r n+1, where n is the number of features,and we're going to predict user J as rating movie I, with just the inner product between the parameters vector theta and the features "XI".
4. let's say that you know we have somehow already gotten a parameter vector theta 1 for Alice.{线性规划求出:对于Alice评过的每部电影就是一个example,其中example0中x = [0.9 0], y = 5,用梯度下降求出theta}
Optimization algorithm:estimate of parameter vector theta j



Note:
1. to simplify the subsequent math,get rid of this term MJ.that's just a constant.
2. because our regularization term here regularizes only the values of theta JK for K not equal to zero.we don't regularize theta 0.
3. can also plug them into a more advanced optimization algorithm like cluster gradient or L-BFGS and use that to try to minimize the cost function J as well.
4. content based recommendations,because we assume that we have features for the different movies.that capture what is the content of these movies. How romantic/action is this movie?And we are really using features of the content of the movies to make our predictions.
5. Suppose there is only one user and he has rated every movie in the training set. This implies that nu=1 and r(i,j)=1 for every i,j . In this case, the cost function J(θ) is equivalent to the one used for regularized linear regression.
Collaborative Filtering协同过滤
{CF has an interesting property:feature learning can start to learn for itself what features to use}
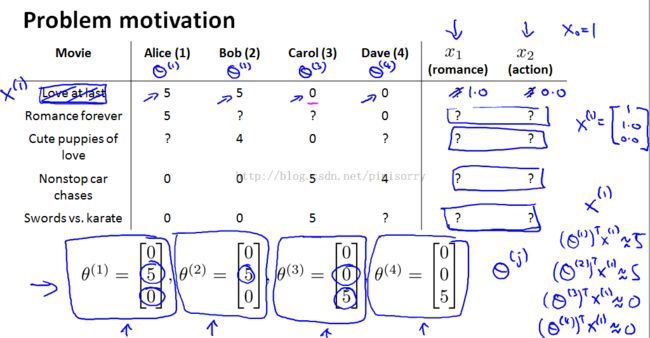
Note:we do not know the values of these features of movies.But assume we've gone to each of our users, and each of our users has told us how much they like the romantic movies and how much they like action packed movies.each user J just tells us what is the value of theta J for them.
Optimization algorithm
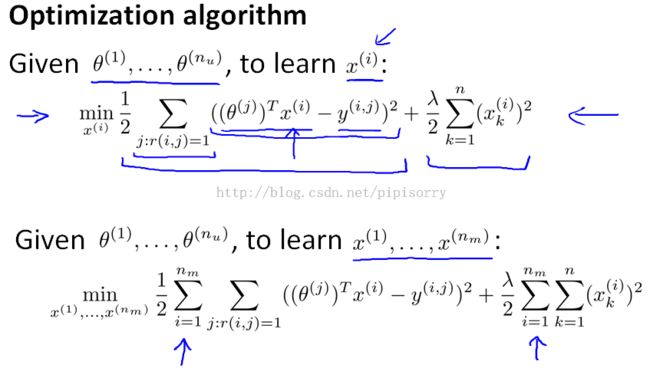

Note:
1. kind of a chicken and egg problem.So randomly guess some value of the thetas.Now based on your initial random guess for the thetas, you can then go ahead and use the procedure to learn features for your different movies.You need toinitialize them to different values so that you learn different features and parameters (i.e., perform symmetry breaking).不能都初始化为0.
2. by rating a few movies myself,the system learn better features and then these features can be used by the system to make better movie predictions for everyone else.And so there is a sense of collaboration where every user is helping the system learn better features for the common good. This is this collaborative filtering.
Collaborative Filtering Algorithm协同过滤算法
{more efficient algorithm that doesn't need to go back and forth between the x's and the thetas, but that can solve for theta and x simultaneously}
Collaborative filteringoptimization objective

Note:
1. Sum over J says, for every user, the sum of all the movies rated by that user.for every movie I,sum over all the users J that have rated that movie.
2. just something over all the user movie pairs for which you have a rating.
3. if you were to hold the x's constant and just minimize with respect to the thetas then you'd be solving exactly the first problem.
4. Previously we have been using this convention that we have a feature x0 equals one that corresponds to an interceptor.When we are using this sort of formalism where we're are actually learning the features,we are actually going to do away with feature x0.And so the features we are going to learn x, will be in Rn.
Collaborative filtering algorithm

Vectorization: Low Rank Matrix Factorization向量化:低秩矩阵分解
an Vectorization wayof writing out the predictions of the collaborative filtering algorithm


Note:the collaborative filtering algorithm is also calledlow rank matrix factorization.And this term comes from the property that this matrix x times theta transpose has a mathematical property in linear algebra called that this is a low rank matrix.
use the learned features in order to find related movies

Implementational Detail: Mean Normalization实现细节:均值
{do mean normalization as a sort of pre-processing step for collaborative filtering Depending on your data set}
Users who have not rated any movies

Note:so there's no one movie with a higher predicted rating that we could recommend toEve, so, that's not very good.
Mean Normalization

Note:
1. 没有评分的user_item不计入mean的计算
2. my prediction where in my training data subtracted off all the means and so when we make predictions and we need toadd back in these means mu i for movie i.
3.in case you have some movies with no ratings,you can normalize the different columns to have means zero, instead of normalizing the rows to have mean zero,but if you really have a movie with no rating, maybe you just shouldn't recommend that movie to anyone.And so, taking care of the case of a user who hasn'trated anything might be more important than taking care of the case of a movie that hasn't gotten a single rating.
Reviews复习

![]()

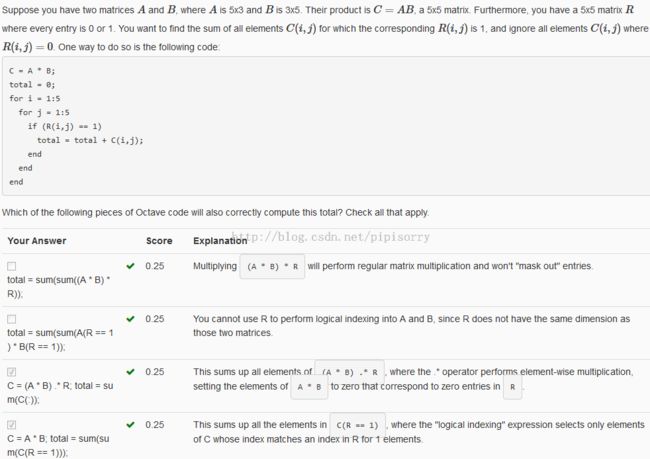

from:http://blog.csdn.net/pipisorry/article/details/44850971
ref:海量数据挖掘MMDS week4:推荐系统Recommendation System