在python中的使用Libsvm
http://blog.csdn.net/pipisorry/article/details/38964135
LIBSVM是台湾大学林智仁(LinChih-Jen)教授等开发设计的一个简单、易于使用和快速有效的SVM模式识别与回归的软件包,他不但提供了编译好的可在Windows系列系统的执行文件,还提供了源代码,方便改进、修改以及在其它操作系统上应用;该软件对SVM所涉及的参数调节相对比较少,提供了很多的默认参数,利用这些默认参数可以解决很多问题;并提供了交互检验(Cross Validation)的功能。该软件包可在http://www.csie.ntu.edu.tw/~cjlin/免费获得。该软件可以解决C-SVM、ν-SVM、ε-SVR和ν-SVR等问题,包括基于一对一算法的多类模式识别问题。
1)Eclipse+Pydev搭建开发环境
从官网下载windows下的安装包python-2.7.3.msi并安装,完成python集成开发环境配置
ref: Eclipse+Pydev搭建开发环境 http://blog.csdn.net/pipisorry/article/details/38964249
2)下载使用libsvm
下载libsvm packages(http://download.csdn.net/detail/pipisorry/7847969),把包解压到如:E:\machine_learning\machine_learning\SVM\libsvm-3.182.
http://www.csie.ntu.edu.tw/~cjlin/libsvm/
因为要用libsvm自带的脚本grid.py和easy.py,需要下载(http://download.csdn.net/detail/pipisorry/7847991)绘图工具gnuplot安装
进入E:\machine_learning\machine_learning\SVM\libsvm-3.18\tools目录下,用文本编辑器(记事本,edit都可以)修改grid.py和easy.py两个文件,找到其中关于gnuplot路径的那项,根据实际路径进行修改,并保存
self.gnuplot_pathname = r"D:\gnuplot\bin\pgnuplot.exe"#'c:\tmp\gnuplot\binary\pgnuplot.exe'#改过的
3)在 Eclipse 中使用Python 的交互式 shell
【或者在open console > pydev console > ok就直接可以用了?求试过的说明】
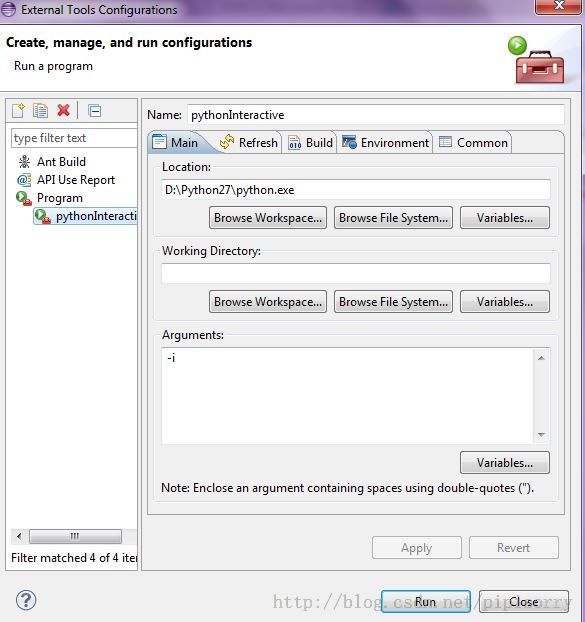
Python解释器支持 Python代码的交互式执行。这种方式对于调试一段代码是非常有用的,因为不用把代码放进 Python脚本中并执行脚本了。同时,Python解释器的交互模式可以很容易地集成到 Eclipse中(通过 Run > External Tools > ExternalTools Configurations增加一个 External Tool启动程序。这时将打开 External Tool启动程序配置窗口。 Configurations列表 > “Program” >点击创建一个新的配置。将该配置命名为诸如"pythonInteractive"之类,然后设置 Location,令其指向您的 Python解释器(python安装位置,如D:\Python27\python.exe),接着,将 "-i"作为唯一的参数传递进来(参阅图)。
在 Common选项卡下,选中复选框,使该配置在 External Tools收藏夹菜单中显示出来。
图Python 交互方式配置
要运行刚刚在 Eclipse中创建的启动器,可选择 Run > External Tools >pythonInterpreter。Python解释器的输出显示在 Console视图中。Console中可输入 Python命令并执行,就像从命令行中执行 Python一样(类似matlab)。为导入并在交互模式下使用模块,您需要将模块的位置增加到PYTHONPATH 环境变量中。
[我的电脑>右键>属性>系统设置>高级>环境变量;new name:PYTHONPATH value:E:\machine_learning\machine_learning\SVM\libsvm-3.18\python;]
在 Eclipse Console中执行 Python与用命令行执行的不同之处在于,无法启用命令历史特性(通过向上和向下的方向键实现),因为 Eclipse Console会自己解释这些键。
打开IDLE(pythonGUI,Run > External Tools > pythonInterpreter)
>>>import sys
>>>sys.version
如果你的python是32位,将出现如下字符:
‘2.7.3 (default,Apr 10 2012, 23:31:26) [MSC v.1500 32bit (Intel)]’
这个时候LIBSVM的python接口设置将非常简单。在libsvm-3.16文件夹下的windows文件夹中找到动态链接库libsvm.dll,将其添加到系统目录,如`C:\WINDOWS\system32\’,即可在python中使用libsvm
如果你的python是64位的,将出现如下字符:
'2.7.3 (default,Apr 10 2012, 23:24:47) [MSC v.150064bit (AMD64)]'
这时你需要首先自己编译64位的动态链接库libsvm.dll。方法如下:
【或者参阅作者文档README中Building Windows Binaries部分】
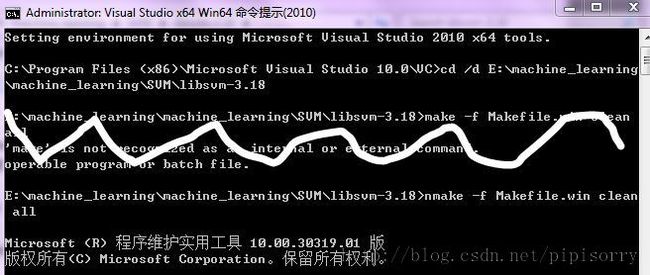
在程序列表(开始菜单)中的Microsoft Visual Studio 2010/Visual Studio Tools下找到Visual Studio x64 Win64 Command Prompt(2010),注意一定要是64位的command prompt
cd到LIBSVM所在文件夹libsvm-3.18【windows中测试见下图】
输入nmake -f Makefile.win clean all
这时libsvm-3.18的windows目录下将生成64位的动态链接库。将新生成的libsvm.dll复制到系统目录(例如`C:\Windows\System32')即可。
皮皮Blog
4)两个小例子
1.Run > External Tools > pythonInterpreter
console中输入:
import sys
sys.version
import os
os.chdir('E:\machine_learning\machine_learning\SVM\libsvm-3.18\python')
from svmutil import *
y, x = svm_read_problem('../heart_scale')
m = svm_train(y[:200], x[:200], '-c 4')
p_label, p_acc, p_val =svm_predict(y[:200], x[:200], m)
运行结果:
>>>'2.7.6 (default, Nov 10 2013, 19:24:24) [MSC v.1500 64 bit (AMD64)]'
>>>*.*
optimization finished, #iter = 257
>>> nu = 0.351161
obj = -225.628984, rho = 0.636110
nSV = 91, nBSV = 49
Total nSV = 91
>>> Accuracy = 91% (182/200) (classification)
使用个人的数据
libsvm的数据格式如下:

第一列代表标签,第二列是第一个特征值,第三列是第二个特征值。所以,先要把数据按规定格式整理好。然后开始训练。
import os
import sys
os.chdir('E:\machine_learning\machine_learning\SVM\libsvm-3.18\python')
from svmutil import *
y, x = svm_read_problem('../lkagain.txt')
m = svm_train(y[:275], x[:275], '-c 5')
y, x = svm_read_problem('../lk2.txt')
p_label, p_acc, p_val = svm_predict(y[0:], x[0:], m)
print p_label
print p_acc
print p_val
2.直接在windows下的cmd中进行(train自带的heart_scale数据集):

直接type svm-train可看到其用法:

5)python接口的说明
在libsvm-3.18的python文件夹下主要包括了两个文件svm.py和svmutil.py。
svmutil.py接口主要包括了high-level的函数,这些函数的使用和LIBSVM的MATLAB接口大体类似
svmutil中主要包含了以下几个函数:
svm_train() : train an SVM model #训练
svm_predict() : predict testing data #预测
svm_read_problem() : read the data from a LIBSVM-format file.#读取libsvm格式的数据
svm_load_model() : load a LIBSVM model.
svm_save_model() : save model to a file.
evaluations() : evaluate prediction results.
- There are three ways to call svm_train()#svm_train()三种训练写法
>>> model = svm_train(y, x [, 'training_options'])
>>> model = svm_train(prob [, 'training_options'])
>>> model = svm_train(prob, param)
svm.py接口主要包括了一些low-level的应用。
在svm.py中采用了python内置的ctypes库,由此python可以直接访问svm.h中定义的C结构和接口函数。svm.py主要运用了四个数据结构svm_node, svm_problem, svm_parameter和svm_model。
皮皮Blog
6)有关参数的设置:
[read me 文件夹中有详细说明:E:\machine_learning\machine_learning\SVM\libsvm-3.18\readme]
Usage: svm-train [options] training_set_file [model_file]
options:
-s svm_type : set type of SVM (default 0)#选择哪一种svm
0 -- C-SVC (multi-class classification)
1 -- nu-SVC (multi-class classification)
2 -- one-class SVM
3 -- epsilon-SVR (regression)
4 -- nu-SVR (regression)
-t kernel_type : set type of kernel function (default 2)#是否用kernel trick
0 -- linear: u'*v
1 -- polynomial: (gamma*u'*v + coef0)^degree
2 -- radial basis function: exp(-gamma*|u-v|^2)
3 -- sigmoid: tanh(gamma*u'*v + coef0)
4 -- precomputed kernel (kernel values in training_set_file)
-d degree : set degree in kernel function (default 3)
-g gamma : set gamma in kernel function (default 1/num_features)
-r coef0 : set coef0 in kernel function (default 0)
-c cost : set the parameter C of C-SVC, epsilon-SVR, and nu-SVR (default 1)
-n nu : set the parameter nu of nu-SVC, one-class SVM, and nu-SVR (default 0.5)
-p epsilon : set the epsilon in loss function of epsilon-SVR (default 0.1)
-m cachesize : set cache memory size in MB (default 100)
-e epsilon : set tolerance of termination criterion (default 0.001)
-h shrinking : whether to use the shrinking heuristics, 0 or 1 (default 1)
-b probability_estimates : whether to train a SVC or SVR model for probability estimates, 0 or 1 (default 0)
-wi weight : set the parameter C of class i to weight*C, for C-SVC (default 1)
-v n: n-fold cross validation mode
-q : quiet mode (no outputs)
皮皮Blog
附:
提高预测的准确率:
通过一定的过程,可以提高预测的准确率(在文献A practical guide to support vector classification中有详细介绍):
a.转换数据为libsvm可用形式.(可以通过下载的数据了解格式)
b.进行一个简单的尺度变换
c.利用RBF kernel,利用cross-validation来查找最佳的参数 C 和 r
d.利用最佳参数C 和 r ,来训练整个数据集
e.测试
from:http://blog.csdn.net/pipisorry/article/details/38964135
ref: Eclipse中使用 Python 的交互式 shell http://www.ibm.com/developerworks/cn/opensource/os-ecant/
LIBSVM在python下的使用 http://blog.csdn.net/lqhbupt/article/details/8599295
如何利用python使用libsvm http://www.cnblogs.com/Dzhouqi/p/3653823.html
Python下的LibSVM的使用 http://blog.chinaunix.net/uid-22414998-id-4175203.html
libsvm作者主页:http://www.csie.ntu.edu.tw/~cjlin/