基于GPU的高分一号影像正射校正的设计与实现
基于GPU的高分一号影像正射校正的设计与实现
一 RPC正射校正的原理
影像正射校正的方法有很多,主要包含两大类:一类是严格的几何纠正模型,另一类是近似几何纠正模型。当遥感影像的成像模型和有关参数已知时,可以根据严格的成像模型来校正图像,这种方法属于严格几何纠正,最具代表的是共线方程法。当传感器成像模型未知或者无法获取相关的辅助参数时,可以用假定的数学模型模拟成像模型,对影像实现校正,这种方法属于近似几何纠正,主要有:几何多项式纠正、有理函数法、局部区域校正等模型。本文将主要对RPC正射校正模型进行展开讨论。
RPC模型将像点坐标d(line,sample)表示为以地面点大地坐标D(Latitude,Longitude,Height)为自变量的比值。为了减小计算过程中舍入误差,增强参数求解的稳定性,需要把地面坐标和影像坐标正则化到(-1,1)之间。对于一个影像,定义如下比值多项式:
 (1-1)
(1-1)
式中,
其中,b1和d1通常为1,(P,L,H)为正则化的地面坐标,(X,Y)为正则化的影像坐标,a1,a2,a3,...a20,b1,b2,b3,...b20,c1,c2,c3,...c20,d1,d2,d3,..d20为RPC参数。
正则化规则如下:
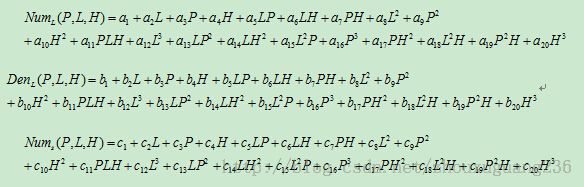
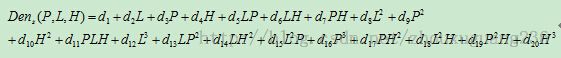
这里,LAT_OFF,LAT_SCALE,LONG_OFF,LONG_SCALE,HEIGHT_OFF,HEIGHT_SCALE为物方坐标的正则化参数。SAMP_OFF,SAMP_SCALE,LINE_OFF,LINE_SCALE为像方坐标的正则化参数。它们与RPC模型中4个多项式的80个系数共同保存于卫星厂家提供给用户的RPC文件中。
在RPC模型中,可用一阶多项式来表示由光学投影引起的畸变误差模型,由二阶多项式趋近由地球曲率、投影折射、镜头倾斜等因素引起的畸变,可用三阶多项式来模拟高阶部分的其他未知畸变。
1.2 RPC模型的优化
RPC模型的优化方法有两种:分为直接优化法和间接优化法。直接优化法是利用足够的地面控制点信息重新计算RPC系数。因此优化后的RPC系数可以直接代入用于影像的定位和计算,而不需要对已经建立起来的模型进行改变。间接优化法是在像方或物方空间进行一些补偿换算,以减小一些系统误差。在间接优化法中,仿射变换法是最常用的方法。
仿射变换公式如下:

式中,(x,y )是在影像上量测得到的GCP的影像坐标。
(sample,line)是利用RPC模型计算得到的GCP的影像坐标。
(e0,e1,e2,f0,f1,f2)是两组坐标之间的仿射变换参数。
利用少量的地面控制点即可解算出仿射变换的参数。这样就能利用仿射变换对由RPC模型计算得到的影像坐标解求出更为精确的行列坐标,从而达到优化RPC模型的目的。
本博客暂时先不考虑控制点和DEM,待以后完善。根据RPC系数,RPC正解变换就是从影像的行列号坐标到地面坐标点的变换,在RPC模型中,正解变换需要用到仿射变换六个参数以及RPC系数。RPC反变换是地面到影像行列号坐标的变换,只需要RPC系数就可以。
二、RPC正射校正的CPU上实现
RPC正射校正需要解决几个基本的问题,一个问题是第一部分提到的RPC正解和反解变换,另外还需要根据RPC系数填充多项式的系数。
1、计算各个多项式的项,即计算公式中(1-1)中的乘积项,也就是L,P,H相乘的那部分,其代码如下:
void RPCComputeCoeffTerms( double dfLong, double dfLat, double dfHeight, double *padfTerms )
{
padfTerms[0] = 1.0;
padfTerms[1] = dfLong;
padfTerms[2] = dfLat;
padfTerms[3] = dfHeight;
padfTerms[4] = dfLong * dfLat;
padfTerms[5] = dfLong * dfHeight;
padfTerms[6] = dfLat * dfHeight;
padfTerms[7] = dfLong * dfLong;
padfTerms[8] = dfLat * dfLat;
padfTerms[9] = dfHeight * dfHeight;
padfTerms[10] = dfLong * dfLat * dfHeight;
padfTerms[11] = dfLong * dfLong * dfLong;
padfTerms[12] = dfLong * dfLat * dfLat;
padfTerms[13] = dfLong * dfHeight * dfHeight;
padfTerms[14] = dfLong * dfLong * dfLat;
padfTerms[15] = dfLat * dfLat * dfLat;
padfTerms[16] = dfLat * dfHeight * dfHeight;
padfTerms[17] = dfLong * dfLong * dfHeight;
padfTerms[18] = dfLat * dfLat * dfHeight;
padfTerms[19] = dfHeight * dfHeight * dfHeight;
}
2、计算各个RPC项和L,P,H等的乘积和,代码如下:
double RPCEvaluateSum( double *padfTerms, double *padfCoefs )
{
double dfSum = 0.0;
int i;
for( i = 0; i < 20; i++ )
dfSum += padfTerms[i] * padfCoefs[i];
return dfSum;
}
3、正解变换,即影像到地面坐标的变换,这个函数需要用到迭代,具体代码如下:
void RPCInverseTransform( stRPCInfo *pRPC,double *dbGeoTran,
double dfPixel, double dfLine, double dfHeight,
double *pdfLong, double *pdfLat )
{
double dfResultX, dfResultY;
//初始值使用放射变换系数求解
dfResultX = dbGeoTran[0] + dbGeoTran[1] * dfPixel + dbGeoTran[2] * dfLine;
dfResultY = dbGeoTran[3] + dbGeoTran[4] * dfPixel + dbGeoTran[5] * dfLine;
//开始用正变换的函数进行迭代
double dfPixelDeltaX=0.0, dfPixelDeltaY=0.0;
int nIter;
for( nIter = 0; nIter < 20; nIter++ )
{
double dfBackPixel, dfBackLine;
//反算像点坐标,计算阈值
RPCTransform( pRPC, dfResultX, dfResultY, dfHeight,
&dfBackPixel, &dfBackLine );
dfPixelDeltaX = dfBackPixel - dfPixel;
dfPixelDeltaY = dfBackLine - dfLine;
dfResultX = dfResultX
- dfPixelDeltaX * dbGeoTran[1] - dfPixelDeltaY * dbGeoTran[2];
dfResultY = dfResultY
- dfPixelDeltaX * dbGeoTran[4] - dfPixelDeltaY * dbGeoTran[5];
if( fabs(dfPixelDeltaX) < 0.001
&& fabs(dfPixelDeltaY) < 0.001 )
{
break;
}
}
//printf("迭代%d次\n",nIter);
*pdfLong = dfResultX;
*pdfLat = dfResultY;
}
4、反解变换,即地面坐标点到影像行列号坐标的变换,可由RPC系数直接求取,具体代码如下:
void RPCTransform( stRPCInfo *pRPC,
double dfLong, double dfLat, double dfHeight,
double *pdfPixel, double *pdfLine )
{
double dfResultX, dfResultY;
double adfTerms[20];
RPCComputeCoeffTerms(
(dfLong - pRPC->dfLONG_OFF) / pRPC->dfLONG_SCALE,
(dfLat - pRPC->dfLAT_OFF) / pRPC->dfLAT_SCALE,
(dfHeight - pRPC->dfHEIGHT_OFF) / pRPC->dfHEIGHT_SCALE,
adfTerms );
dfResultX = RPCEvaluateSum( adfTerms, pRPC->adfSAMP_NUM_COEFF )
/ RPCEvaluateSum( adfTerms, pRPC->adfSAMP_DEN_COEFF );
dfResultY = RPCEvaluateSum( adfTerms, pRPC->adfLINE_NUM_COEFF )
/ RPCEvaluateSum( adfTerms, pRPC->adfLINE_DEN_COEFF );
*pdfPixel = dfResultX * pRPC->dfSAMP_SCALE + pRPC->dfSAMP_OFF;
*pdfLine = dfResultY * pRPC->dfLINE_SCALE + pRPC->dfLINE_OFF;
}
至此,一些基本的准备做好了,那么下面就开始真正的校正了,RPC校正的大概的流程如下:
(1)根据输入未校正的影像得到输出影像的地理范围、地面分辨率大小以及仿射变换的留个参数。
(2)在输出的校正影像上,求得每一个像素对应的地理坐标,然后变换到原始影像上的行列号,根据一定的插值算法求得输出新影像上的对应的像素值。
(3)将对应的像素值写入到输出文件中。
基本流程已经确定后,那么下面就开始讲如何对大数据进行分块,是按照输入影像分块还是输出影像分块,为了方便编程,一般采用输出影像进行分块,具体过程如下:首先将输出影像按照行进行分块,然后计算每一个输出分块所对应的原始影像的行列号范围,再进行重采样操作,最后得到输出影像的像素值。在本博客中,每多少行为一块分块只是本人自己的实验,实际产品和生产中需要动态检测内存等资源信息。
还有一个需要注意的是,假设影像是多波段的影像,数据怎么排列,为了效率,我创建的输出影像是按照BIP规格存储,就一个像素的所有波段的数据存储在一起,每一个分块的数据也按照BIP方式读取,写入也按照BIP格式写入。
综上所述,CPU上的正射校正可以比容易写出来,影像的IO还是一如既往的用GDAL,具体代码如下:
bool ImageWarpRPC(const char * pszSrcFile, const char * pszDstFile, const char * pszDstWKT,
double dResX, double dResY, const char * pszFormat)
{
GDALAllRegister();
CPLSetConfigOption("GDAL_FILENAME_IS_UTF8", "NO");
// 打开原始图像
GDALDatasetH hSrcDS = GDALOpen(pszSrcFile, GA_ReadOnly);
if (NULL == hSrcDS)
{
return 0;
}
GDALDataType eDataType = GDALGetRasterDataType(GDALGetRasterBand(hSrcDS, 1));
int nBandCount = GDALGetRasterCount(hSrcDS);
double dbGeonTran[6];
GDALGetGeoTransform(hSrcDS,dbGeonTran);
const char* pszItem = GDALGetMetadataItem(hSrcDS,"INTERLEAVE","IMAGE_STRUCTURE");
//获得原始图像的行数和列数
int nXsize = GDALGetRasterXSize(hSrcDS);
int nYsize = GDALGetRasterYSize(hSrcDS);
// 提取RPC系数
char** pszMetadata = GDALGetMetadata(hSrcDS,"RPC");
GDALRPCInfo sRPCInfo;
if (pszMetadata != NULL)
{
GDALExtractRPCInfo( pszMetadata, &sRPCInfo );
}
stRPCInfo stInfo;
memcpy(&stInfo,&sRPCInfo,sizeof(stInfo));
// 计算输出图像四至范围、大小、仿射变换六参数等信息
double adfGeoTransform[6] = {0};
double adfExtent[4] = {0}; //minx,maxx,miny,maxy
int nPixels = 0, nLines = 0;
double dbX[4];
double dbY[4];
//计算四个角点的地理坐标
RPCInverseTransform(&stInfo,dbGeonTran,0,0,100,dbX,dbY);
RPCInverseTransform(&stInfo,dbGeonTran,nXsize,0,100,dbX+1,dbY+1);
RPCInverseTransform(&stInfo,dbGeonTran,nXsize,nYsize,100,dbX+2,dbY+2);
RPCInverseTransform(&stInfo,dbGeonTran,0,nYsize,100,dbX+3,dbY+3);
adfExtent[0] = min(min(dbX[0],dbX[1]) , min(dbX[2],dbX[3]));
adfExtent[1] = max(max(dbX[0],dbX[1]) , max(dbX[2],dbX[3]));
adfExtent[2] = min(min(dbY[0],dbY[1]) , min(dbY[2],dbY[3]));
adfExtent[3] = max(max(dbY[0],dbY[1]) , max(dbY[2],dbY[3]));
int nMinCellSize = min(dbGeonTran[1],fabs(dbGeonTran[5]));
nPixels = ceil( fabs(adfExtent[1] - adfExtent[0]) / dbGeonTran[1] );
nLines = ceil ( fabs(adfExtent[3] - adfExtent[2]) / fabs(dbGeonTran[5]) );
adfGeoTransform[0] = adfExtent[0];
adfGeoTransform[3] = adfExtent[3];
adfGeoTransform[1] = dbGeonTran[1];
adfGeoTransform[5] = dbGeonTran[5];
// 创建输出图像
GDALDriverH hDriver = GDALGetDriverByName( pszFormat );
if (NULL == hDriver)
{
return 0;
}
char **papszOptions = NULL;
papszOptions = CSLSetNameValue( papszOptions, "INTERLEAVE", "PIXEL" );
GDALDatasetH hDstDS = GDALCreate( hDriver, pszDstFile, nPixels, nLines, nBandCount, eDataType, papszOptions );
if (NULL == hDstDS)
{
return 0;
}
GDALSetProjection( hDstDS, pszDstWKT);
GDALSetGeoTransform( hDstDS, adfGeoTransform );
//然后是图像重采样
double dfPixel = 0;
double dfLine = 0;
int nFlag = 0;
float dfValue = 0;
CPLErr err = CE_Failure;
int nOffset = 0; //内存偏移量
int nBandList[4] = {1,2,3,4};
//分块的做法
int nSubHeight = 2000;
int nBlockNum = (nLines+nSubHeight-1)/nSubHeight; //块的数量
/*double *pLineXs = new double[nPixels*nSubHeight];
double *pLineYs = new double[nPixels*nSubHeight];*/
unsigned short *pValues = new unsigned short[nPixels*nBandCount*nSubHeight];
unsigned short *pSrcValues = NULL;
for (int nIndex = 0; nIndex < nBlockNum; nIndex ++)
{
//最后一块特殊处理
int nBottomIndex = (nIndex + 1) *nSubHeight;
if (nBlockNum - 1 == nIndex)
{
nBottomIndex = nLines;
}
//分块的左上角地理坐标
double dbX1 = adfGeoTransform[0] + 0* adfGeoTransform[1]
+ nIndex*nSubHeight * adfGeoTransform[2];
double dbY1 = adfGeoTransform[3] + 0 * adfGeoTransform[4]
+ nIndex*nSubHeight * adfGeoTransform[5];
//分块的右下角地理坐标
double dbX2 = adfGeoTransform[0] + nPixels * adfGeoTransform[1]
+ nBottomIndex * adfGeoTransform[2];
double dbY2 = adfGeoTransform[3] + nPixels * adfGeoTransform[4]
+ nBottomIndex * adfGeoTransform[5];
//分块的右上角地理坐标
double dbX3 = adfGeoTransform[0] + nPixels * adfGeoTransform[1]
+ nIndex*nSubHeight * adfGeoTransform[2];
double dbY3 = adfGeoTransform[3] + nPixels * adfGeoTransform[4]
+ nIndex*nSubHeight * adfGeoTransform[5];
//分块的左下角地理坐标
double dbX4 = adfGeoTransform[0] + 0 * adfGeoTransform[1]
+ nBottomIndex * adfGeoTransform[2];
double dbY4 = adfGeoTransform[3] + 0 * adfGeoTransform[4]
+ nBottomIndex * adfGeoTransform[5];
//由输出的图像地理坐标系变换到原始的像素坐标系
RPCTransform(&stInfo,dbX1,dbY1,100,&dfPixel,&dfLine);
int nCol1 = (int)(dfPixel + 0.5);
int nRow1 = (int)(dfLine + 0.5);
RPCTransform(&stInfo,dbX2,dbY2,100,&dfPixel,&dfLine);
int nCol2 = (int)(dfPixel + 0.5);
int nRow2 = (int)(dfLine + 0.5);
RPCTransform(&stInfo,dbX3,dbY3,100,&dfPixel,&dfLine);
int nCol3 = (int)(dfPixel + 0.5);
int nRow3 = (int)(dfLine + 0.5);
RPCTransform(&stInfo,dbX4,dbY4,100,&dfPixel,&dfLine);
int nCol4 = (int)(dfPixel + 0.5);
int nRow4 = (int)(dfLine + 0.5);
int nMinRow = min( min( nRow1,nRow2 ), min( nRow3 , nRow4));
if (nMinRow < 0)
{
nMinRow = 0;
}
int nMaxRow = max( max( nRow1,nRow2 ), max( nRow3 , nRow4));
if (nMaxRow >= nYsize)
{
nMaxRow = nYsize-1;
}
int nHeight = nMaxRow-nMinRow+1;
//读取原始数据
pSrcValues = new unsigned short[nXsize*nHeight*nBandCount];
int nDataSize = GDALGetDataTypeSize(eDataType)/8;
((GDALDataset*)hSrcDS)->RasterIO(GF_Read,0,nMinRow,nXsize,nHeight,
pSrcValues,nXsize,nHeight,eDataType,nBandCount,nBandList,nBandCount*nDataSize,
nXsize*nBandCount*nDataSize,1*nDataSize);
//这一块适合做并行
if (HasCUDA())
{
DWORD t1 = GetTickCount();
/*RPCWarpCL(stInfo,adfGeoTransform,pSrcValues,nXsize,nHeight,nMinRow,
nYsize,pValues,nPixels,nSubHeight,nIndex*nSubHeight,nBandCount,nIndex,nBlockNum);*/
RPCWarpCuda(stInfo,adfGeoTransform,pSrcValues,nXsize,nHeight,nMinRow,
nYsize,pValues,nPixels,nSubHeight,nIndex*nSubHeight,nBandCount,nIndex,nBlockNum);
DWORD t2 = GetTickCount();
double tt = (t2-t1);
printf("%f毫秒\n",tt);
}
else
{
for (int nRow = nIndex*nSubHeight; nRow < nBottomIndex; nRow ++)
{
for (int nCol = 0; nCol < nPixels; nCol ++)
{
nOffset = ( (nRow - nIndex*nSubHeight)*nPixels + nCol ) * nBandCount;
double dbX = adfGeoTransform[0] + nCol * adfGeoTransform[1]
+ nRow * adfGeoTransform[2];
double dbY = adfGeoTransform[3] + nCol * adfGeoTransform[4]
+ nRow * adfGeoTransform[5];
RPCTransform(&stInfo,dbX,dbY,100,&dfPixel,&dfLine);
int nColIndex = (int)(dfPixel + 0.5);
int nRowIndex = (int)(dfLine + 0.5);
int nOffsetSrc = ( (nRowIndex - nMinRow)*nXsize + nColIndex ) * nBandCount;
//超出范围的用0填充
if (nColIndex < 0 || nColIndex >= nXsize || nRowIndex < 0 || nRowIndex >= nYsize)
{
for (int nBandIndex = 0; nBandIndex < nBandCount; nBandIndex ++)
{
pValues[nOffset++] = 0;
}
}
else
{
for (int nBandIndex = 0; nBandIndex < nBandCount; nBandIndex ++)
{
pValues[nOffset++] = pSrcValues[nOffsetSrc++];
}
}
}//for
}//for
}//else
delete []pSrcValues;
//写入数据
if (nIndex < nBlockNum - 1)
{
( (GDALDataset*)hDstDS )->RasterIO(GF_Write,0,nIndex*nSubHeight,nPixels,nSubHeight,
pValues,nPixels,nSubHeight,(GDALDataType)eDataType,nBandCount,nBandList,nBandCount*nDataSize,
nPixels*nBandCount*nDataSize,1*nDataSize);
}
else if (nIndex == nBlockNum - 1)
{
int nRealIndex = nIndex*nSubHeight;
nSubHeight = nLines - nIndex*nSubHeight;
( (GDALDataset*)hDstDS )->RasterIO(GF_Write,0,nRealIndex,nPixels,nSubHeight,
pValues,nPixels,nSubHeight,(GDALDataType)eDataType,nBandCount,nBandList,nBandCount*nDataSize,
nPixels*nBandCount*nDataSize,1*nDataSize);
}
}
/*delete []pLineXs;
delete []pLineYs;*/
delete []pValues;
GDALClose(hSrcDS );
GDALClose(hDstDS );
return 1;
}
上面的代码还是有很多瑕疵的,比如计算输出影像的范围,比较保险的做法是根据原始影像的四条边来计算,还有影像的数据类型还不支持泛型,这些都将在以后不断完善。细心的读者可能已经发现有RPCWarpCuda和RPCWrapCL的函数,不错,这正是CUDA实现和opencl上的实现,其实大家都知道影像几何校正的时间大部分都花费在影像的重采样上,所以本博客对于正射校正的GPU实现也主要针对坐标的正反算和重采样上。下面开始GPU之旅吧!
三、RPC正射校正的GPU实现
自从NVIDIA推出CUDA,GPGPU的发展速度非常迅速,以前要编写GPU上处理非图形的编程,需要将问题域转化为图形问题,而GPGPU的出现,大大简化了GPU编程,随着技术的进一步发展,之后又出现opencl,这是跨平台的一个标准,最先由苹果公司联合几家公司推出的标准,opencl的具体实现交给各个硬件厂商。
下面就着重介绍CUDA上的实现。CUDA上实现的函数声明如下:
extern "C" void RPCWarpCuda(stRPCInfo& stInfo,
double*pfGeoTransform,
unsignedshort* poDataIn,
intnWidthIn,
intnHeightIn,
intnMinRowIn,
intnSrcHeight,
unsignedshort* poDataOut,
intnWidthOut,
intnHeightOut,
intnMinRowOut,
intnBandCount,
intnBlockIndex,
intnBlockNum);
CUDA的运行模型是由多个线程运行同一个计算过程,在一个计算设备上,划分为不同的线程块,每一个线程块由不同的线程组成,这样组成了一个两层的线程组织体系,对于图像处理来说,最适合划分为二维网格,每一个线程计算一个输出像素,在RPC正射校正模型中,波段数、RPC的参数以及归一化的参数以及输出影像的仿射变换系数在每一个线程都是一样的,所以只需拷贝这些参数到GPU上一次,这些参数在CUDA设备上需要声明为__constant__的,如下:
__constant__ double dbGeoTrans[6];
__constant__ double dfLINE_OFF;
__constant__ double dfSAMP_OFF;
__constant__ double dfLAT_OFF;
__constant__ double dfLONG_OFF;
__constant__ double dfHEIGHT_OFF;
//缩放比例
__constant__ double dfLINE_SCALE;
__constant__ double dfSAMP_SCALE;
__constant__ double dfLAT_SCALE;
__constant__ double dfLONG_SCALE;
__constant__ double dfHEIGHT_SCALE;
//系数
__constant__ double adfLINE_NUM_COEFF[20];
__constant__ double adfLINE_DEN_COEFF[20];
__constant__ double adfSAMP_NUM_COEFF[20];
__constant__ double adfSAMP_DEN_COEFF[20];
//波段数
__constant__ int nBandCount;
在RPCWarpCuda中,只在第一个块的数据传递过来的时候将这些数据拷贝的CUDA设备的常量内存上。代码如下,
if(0 == nBlockIndex)
{
cudaMalloc(&poDataOut_d,nDataSizeOut);
//给参数常量分配空间
cudaMemcpyToSymbol(adfLINE_DEN_COEFF,stInfo.adfLINE_DEN_COEFF,sizeof(double)*20);
cudaMemcpyToSymbol(adfLINE_NUM_COEFF,stInfo.adfLINE_NUM_COEFF,sizeof(double)*20);
cudaMemcpyToSymbol(adfSAMP_DEN_COEFF,stInfo.adfSAMP_DEN_COEFF,sizeof(double)*20);
cudaMemcpyToSymbol(adfSAMP_NUM_COEFF,stInfo.adfSAMP_NUM_COEFF,sizeof(double)*20);
cudaMemcpyToSymbol(dfHEIGHT_OFF,&stInfo.dfHEIGHT_OFF,sizeof(double));
cudaMemcpyToSymbol(dfHEIGHT_SCALE,&stInfo.dfHEIGHT_SCALE,sizeof(double));
cudaMemcpyToSymbol(dfLAT_OFF,&stInfo.dfLAT_OFF,sizeof(double));
cudaMemcpyToSymbol(dfLAT_SCALE,&stInfo.dfLAT_SCALE,sizeof(double));
cudaMemcpyToSymbol(dfLINE_OFF,&stInfo.dfLINE_OFF,sizeof(double));
cudaMemcpyToSymbol(dfLINE_SCALE,&stInfo.dfLINE_SCALE,sizeof(double));
cudaMemcpyToSymbol(dfLONG_OFF,&stInfo.dfLONG_OFF,sizeof(double));
cudaMemcpyToSymbol(dfLONG_SCALE,&stInfo.dfLONG_SCALE,sizeof(double));
cudaMemcpyToSymbol(dfSAMP_OFF,&stInfo.dfSAMP_OFF,sizeof(double));
cudaMemcpyToSymbol(dfSAMP_SCALE,&stInfo.dfSAMP_SCALE,sizeof(double));
//传递放射变换系数
cudaMemcpyToSymbol(dbGeoTrans,pfGeoTransform,sizeof(double)*6);
cudaMemcpyToSymbol(nBandCount,&nBands,sizeof(int));
}
由于输出影像是均匀分块,所以只需要第一次给输出的数据申请设备存在,这样可以减少设备内存分配的时间,在最后一次的时候将输出数据设备内存释放掉。
在RPCWarpCuda中,只在第一个块的数据传递过来的时候将这些数据拷贝的CUDA设备的常量内存上。还有调用内很函数的时候将线程块设为32*32的,这刚好是1024个线程,现在很多设备都至少支持每个线程块都支持1024个线程,但是真正产品中需要检测设备的参数。一切准备工作就绪后,那么下面就只需编写内核函数了,其实内核函数要做的工作主要是影像坐标和地面点的坐标之间的换算以及影像重采样,其核函数如下:
__global__ void RPCWarpKernel(
unsigned short* poDataIn,
int nWidthIn,
int nHeightIn,
int nMinRowIn,
int nSrcHeight,
unsigned short* poDataOut,
int nWidthOut,
int nHeightOut,
int nMinRowOut)
{
int idy = blockIdx.y*blockDim.y + threadIdx.y; //行
int idx = blockIdx.x*blockDim.x + threadIdx.x; //列
if (idx < nWidthOut && idy < nHeightOut)
{
//求出输出影像的实际行列号
int nRow = idy + nMinRowOut;
int nCol = idx;
double dbX = dbGeoTrans[0] + nCol * dbGeoTrans[1]
+ nRow * dbGeoTrans[2];
double dbY = dbGeoTrans[3] + nCol * dbGeoTrans[4]
+ nRow * dbGeoTrans[5];
double dfPixel = 0.0;
double dfLine = 0.0;
RPCTransformCUDA(dbX,dbY,100,&dfPixel,&dfLine);
//求出原始影像所在坐标,然后最邻近采样
int nColIndex = (int)(dfPixel + 0.5);
int nRowIndex = (int)(dfLine + 0.5);
int nOffsetSrc = ( (nRowIndex - nMinRowIn)*nWidthIn + nColIndex ) * nBandCount;
int nOffset = ( (nRow - nMinRowOut)*nWidthOut + nCol ) * nBandCount;
//超出范围的用0填充
if (nColIndex < 0 || nColIndex >= nWidthIn || nRowIndex < 0 || nRowIndex >= nSrcHeight)
{
for (int nBandIndex = 0; nBandIndex < nBandCount; nBandIndex ++)
{
poDataOut[nOffset++] = 0;
}
}
else
{
for (int nBandIndex = 0; nBandIndex < nBandCount; nBandIndex ++)
{
poDataOut[nOffset++] = poDataIn[nOffsetSrc++];
}
}
}
}
至此,CUDA上的实现就介绍到这里,关于OPENCL上的实现也和CUDA实现差不多,具体就不阐述了,我会上传代码,有兴趣的读者可以下载自己研究并改进。
四、性能测试
我测试环境是硬件环境是GT750m,CUDA是5.5版本,opencl是CUDA上的实现。
测试数据时高分一号宽幅的数据,行数是13400,列数是12000,4个波段,数据类型是unsigned short,原始影像文件的大小是1.2GB。经过大量的测试,测试的结果如下:
|
CPU |
CUDA |
加速比 |
OPENCL |
加速比 |
包括IO时间 |
230.031s |
85.773s |
2.68 |
85.782s |
2.68 |
不包括IO时间 |
130.576s |
6.657s |
19.61 |
6.781s |
19.26 |
从上面的结论可以看出,如果不统计影像IO的时间,CUDA和OPENCL都可以获得很大的加速比,加速比能够达到20左右,并且CUDA和OPENCL的加速效果相当接近。影像IO的时间大约是80-100秒左右。如果计算影像IO的时间,加速效果大概是2.68倍左右,所以下一步该研究如何优化影像的IO操作。
校正前后的图像比较如下:

校正前

校正后。
五、结论与展望
通过对RPC正射校正的的GPU实现,可以看出,GPU在遥感影像处理中可以发挥它巨大的优势,有GPU的用武之地。但是本文没对GPU优化进行进一步研究。下一步研究加入DEM以及加入控制点提高精度;对于影像IO部分,也需要深入的研究。代码下载地址是:http://download.csdn.net/detail/zhouxuguang236/7910583
对于相关的环境,可能需要读者自己配置了。也欢迎大家提出意见,共同进步。