How to Tell if the I/O of the Database is Slow - 2
IO的类型:
平均响应时间直接关联到具体的IO类型:
1. 读或写
2. 单块或多块
单块IO,指一次只读一个块。例如,当一个session等待一个单块IO时,典型的等待事件就是“db file sequential read”,表明正在等待需要的块。
多块读指的是一次读多个块,从2到128个Oracle块不等,依赖于块的大小与操作系统设置。通常一个多块请求容量上有1MB的限制。例如当一个session等待一次多块IO时,典型的等待事件就是“db file scattered read”,表明正在等待需要的块。
3. 同步或异步
同步(阻塞)操作等待硬件完成物理IO,完成后能得到通知,合理地管理操作的成功或失败(成功读的情况下可以接收结果)。当需要等待系统调用结果的时候,进程的执行是被堵塞的。
对于异步(非阻塞)操作,一旦IO请求传递到硬件,或放入操作系统的队列中(典型的情况是物理IO开始之前),系统调用会立即返回。进程的执行不会被堵塞,因为它不需要等待系统调用的结果。它能继续执行,当IO操作有结果时再接收。
响应时间的预期阈值:
一次典型的多块同步读64x 8k(总计512KB)的平均时间应该在未出现IO变慢的情况下大约是20毫秒左右。小请求应该更快(10-20毫秒),大请求的消耗时间应该不多于25毫秒。
1. 异步操作应该至少和同步操作一样快,甚至还要更快。
2. 单块读至少应该和多块读一样快,甚至还要更快。
3. “log file parallel write”,“control file write”和“direct path writes“等待时间应该不多于15毫秒。
数据文件写的测量不像读那样简单。DBWR以批量的方式("db file parallel write")异步写入块,现在还没有写操作响应时间的标准。
如果DBWR(多块或单块,带或不带IO salves)足够快速能够清理脏块,那么其他的等待事件和统计信息就会显露出来。
作为规则,超过上述等待事件时间的等待事件都应该详细分析,当对比之前的时间消耗,有明显变化时更需要知晓。
注意:当系统低于这些最大阈值的时候,并不意味着没有其他的调优方法。
响应时间因系统而有所不同。例如,接下来的几项内容可以看做是正常平均值:
1. 多块同步读时间是10毫秒。
2. 单块同步读时间是5毫秒。
3. 'log file parallel write'时间是3毫秒。
以上是基于多块IO比单块IO需要更多的IO子系统资源的前提。如果接受这些建议,redo日志最好放在最快的磁盘,并且没有其它并发活动的争用。
确认IO响应时间:
Oracle记录特定的等待事件与统计信息的IO操作响应时间作为”Elapsed Time“。”Response time“和”elapsed time“在上下文中是同义词,可互换的词汇。接下来的列表是一些常见的等待事件,以及可接受的典型等待时间(不是最全的)。
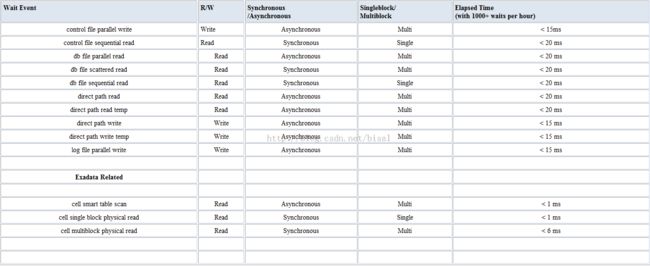
Oracle中明确IO响应时间的方法:
10046 trace文件:
当在10046 trace中使用级别8或12时,会包含相关的等待事件,响应时间显示到ela字段。从9i以后,单位是微妙。8i以前是1/100秒(10毫秒)。
672 microseconds = 0.672 ms
1018 microseconds => 1.018 ms
"waiting for"
表示进程处于等待状态。11g之前可以查看”seconds since wait started“字段,显示进程已经等待多久了。从11gR1开始,”total“字段显示等待的时间。
如果”waiting for“显示一个进程正在等待一个IO相关的操作,”seconds since wait started“>0,表示可能IO丢失,session处于hang状态。(因为之前提到过平均可接受时间是20毫秒,任何IO等待时间超过1秒都需要关注)。
”last wait for“
是与11g之前的版本相关的,表明进程不在等待(例如正在使用CPU)。等待时间记录到”wait_time“字段。(11g中”wait_time“被”not in wait“替代)
last wait for 'db file sequential read' blocking sess=0x0 seq=100 wait_time=2264 seconds since wait started=0
file#=45, block#=17a57, blocks=1
2264 microseconds => 2.264 ms
”waited for“
表示session不在等待。通常是11gR1以后的系统级trace中使用。”total“字段表示等待的总时间。
0: waited for 'db file sequential read' file#=9, block#=46526, blocks=1
wait_id=179 seq_num=180 snap_id=1
wait times: snap=0.007039 sec, exc=0.007039 sec, total=0.007039 sec
wait times: max=infinite
wait counts: calls=0 os=0
0.007039 sec => 7.039 ms
Statspack和AWR报告:
前台进程和后台进程的等待事件:
报告会展示前台进程与后台进程各自的等待细节。
Avg
%Time Total Wait wait Waits % DB
Event Waits -outs Time (s) (ms) /txn time
-------------------------- ------------ ----- ---------- ------- -------- ------
db file sequential read 2,354,428 0 8,256 4 2.6 21.2
db file scattered read 23,614 0 48 2 0.0 .1
报告中,平均响应时间通过Avg wait (ms)反映(以毫秒计算的平均读)。
表空间IO:
表空间节则展示了从表空间观点得到的一些有用信息:
Tablespace
------------------------------
Av Av Av Av Buffer Av Buf
Reads Reads/s Rd(ms) Blks/Rd Writes Writes/s Waits Wt(ms)
-------------- ------- ------- ------- ------------ -------- ---------- -------
APPS_DATA
1,606,553 446 2.2 8.3 75,575 21 60,542 0.9 平均响应时间通过Av Rd (ms)反映(以毫秒计算的平均读)。
等待事件直方图:
等待事件直方图节可以提供组成这些平均值的写操作时间分布。他会展示出所有写操作都接近于平均值,还是会有若干波峰或波谷的情况。
% of Waits
-----------------------------------------------
Total
Event Waits <1ms <2ms <4ms <8ms <16ms <32ms <=1s >1s
-------------------------- ----- ----- ----- ----- ----- ----- ----- ----- -----
db file parallel read 4139 .2 .5 2.5 26.4 23.5 15.0 31.9 .1
db file parallel write 329K 88.5 4.0 2.1 1.9 2.3 1.1 .3 .0
db file scattered read 14.4K 54.3 8.5 6.1 16.6 11.5 2.6 .4 每列都表明每个bucket之间等待事件时间分布的百分比。例如,”<16毫秒“的等待大于”<8毫秒“。只要最大的百分比是从<1毫秒到16毫秒的范围内,那么IO性能通常就可以接受。