Linux2.6内核--中断下半部实现方法 工作队列
工作队列子系统是一个用于创建内核线程的接口,通过它创建的进程负责执行由内核其他部分排到队列里的任务。它创建的这些内核线程称作工作者线程。工作队列可以让你的驱动程序创建一个专门的工作者线程来处理需要退后的工作。不过,工作队列子系统提供了一个缺省的工作者线程来处理这些工作。因此,工作队列最基本的表现形式,就转变成了一个把需要退后执行的任务交给特定的通用线程的这样一种接口。
缺省的工作者线程叫做 events/n ,这里 n 是处理器的编号;每个处理器对应一个线程。缺省的工作者线程会从多个地方得到被推后的工作。许多内核驱动程序都把它们的下半部交给缺省工作者线程去处理。除非一个驱动程序或者子系统必须建立一个属于它自己的内核线程,否则最好使用缺省线程。
说到这里,就需要分析下这种执行下半部的特点了。
它是唯一能在进程上下文中运行的下半部实现机制,也只有它才可以睡眠。这意味着你需要获得大量的内存时,在你需要获取信号量时,在你需要执行阻塞式的 IO 操作时,它都会非常有用。
下面首先给出一张图解释工作者线程的层次:
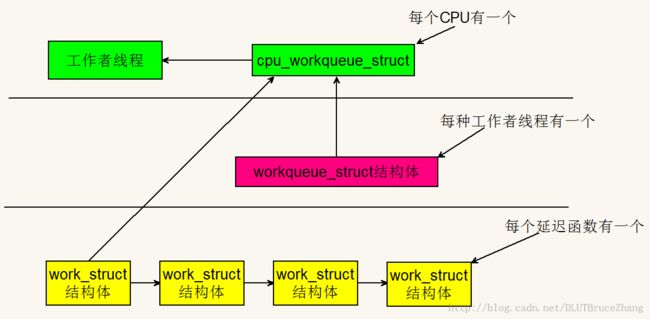
由这张图可以看出,工作者线程位于最高的一层。系统中允许有多种类型的工作者线程存在。对于指定的一个类型,系统的每个 CPU 上都有一个该类的工作者线程。
工作位于最底层,这些表示的就是你的驱动程序创建的这些需要退后执行的工作。
大部分驱动程序都使用的是现存的默认工作者线程。它们使用起来简单方便。可是,在有些要求严格的情况下,驱动程序需要自己的工作者线程,这时,就需要驱动程序创建一个属于自己的工作者线程。
下面,我们来看下工作者线程的执行函数 run_workqueue():
while(!list_empty(&cwq-worklist))
{
struct work_struct *work;
work_fun_t f;
void *data;
work = list_entry(cwq->worklist.next, struct work_struct, entry);
f = work->func;
list_del_init(cwq->worklist.next);
work_clear_pending(work);
f(work);
}
该函数循环遍历链表上每个待处理的工作,执行链表每个节点上的 workqueue_struct 中的 func 成员函数:
1.当链表不为空时,选取下一个节点对象
2.获取我们希望执行的函数 func 及其参数 data
3.把该节点从链表上解下来,将待处理标志位 pending 清零
4.调用函数
5.重复执行