C++对象模型(五):The Semantics of Data Data语义学
本文是《Inside the C++ Object Model》第三章的读书笔记。主要讨论C++ data member的内存布局。这里的data member 包含了class有虚函数时的vptr和vtable的布局情况。
1. 开头几个小问题
1. 首先回答一个问题: 一个空类,sizeof是多少?答案是1。因为编译器会生成一个隐晦的1bytes,用于区分,当该类多个对象时,各个对象都能在内存分配唯一地址。
2. 还有虚函数表的指针vptr,可能在类的开始,也可能在类的结尾。通常是类的结尾。(注:比较新的VC++和GCC都是在开头。不知道是否所有的版本都是)。
3. 关于成员变量的内存对齐,例如一个类只有char a一个属性; 但是它的大小是4(32位。64位机器是8?但是我是用GCC的sizeof仍然是1。熟悉汇编应该知道,这个地址应该不会存其他的内容了,因此说sizeof是4/8也可理解)。虽然char的大小是1。
4. 属性的内存顺序和声明顺序是一致的。不同级别(public、protected和private)属性的排列顺序是相对一致的,就是说可能不连续,但是必须符合较晚出现的属性存在较高的地址。
2. vptr值的不同存储方式
以下的图来自http://blog.csdn.net/hherima同学。非常感谢hherima同学的图。我将使用hherima同学的图,加上我自身的理解来彻底巩固并且分享给各位可爱的程序猿们。
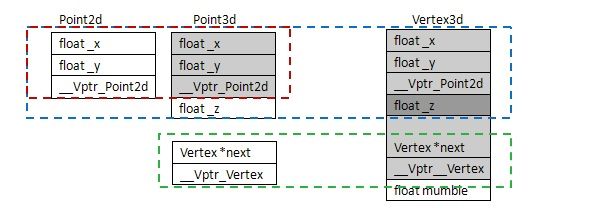
下图演示单一继承并含有虚函数情况下的数据布局。Point2d 和Point3d是继承关系。Point2d含有虚函数,而Point3d自身没有虚函数。

注意:vptr放在类的末尾。这种方式在刚开始被很多编译器采用,因为可以保存base c struct的内存布局。
但是到了C++2.0,开始支持虚拟继承和抽象基类;并且由于OO的兴起,某些编译器开始把vptr放到class object的起头处。比如微软的第一个C++编译器就是采用这种方法。

前端存放的好处就是编译器可以直接访问虚函数表而不需要通过offset。当然代价就是与C的struct不再兼容。但是谁会从一个C struct派生出具有虚函数的C++ class呢?
如果是前端存放,还存在一个问题:如果基类没有虚函数,派生类有虚函数,那么单一继承的自然多态就会被打破。如果要将派生类转换成基类,必须编译器的介入。但是这种情况也比较少,因此多态就是为了继承,谁会设计出这种继承呢?既然这不是大多数的case,采用vptr在开头,那么就具有很好的意义。这种conventional实际上很利于编译器将C++编译到汇编,而且汇编也比较容易读。否则,放在结尾的话,每个class的data member数量是不一样的,因此vptr存储的offset也不一样。而放到头上,那么0号位置存的就是vptr,1号位置存的就是第一个data member,这样不单利于编译代码,也便于我们阅读反汇编的汇编代码。
3. 数据成员(data member)的内存布局
在上一小节中我们讨论了vptr的不同存放方式。编译器需要通过设置offset来存取vptr和data member。在98页关于对一个nonstatic data member的存取操作描述,feel confused:作者的意思是如果是直接取对象的第一个data member,那么需要在对象的地址+1。我不是太明白。如果是存取对象的第一个成员,那么对象的地址应该就是指向第一个成员的,它可能是vptr,也可能是第一个data member。那么如果是汇编,那么直接取该地址的内容,该地址的内容有可能是成员的值,也可能存的仍是地址(指针),那么offset+1没有意义。如果是C++的code,那么本身不需要这么麻烦,谁会直接将对象所在的地址进行解释,而不是通过C++的方式?当然某些高性能编程可能是,但是我实在想不出有任何理由要这样去做。
C++语言保证“出现在派生类中的基类对象,有其完整性”,这么做是为了在位拷贝的时候,能够拷贝正确。一般每个成员都会独占一个地址,意思是在32位机器上,每个数据成员至少占用4个B。当然为了内存对齐,比如有一下class:class data{
char a;
char b;
int c;
};
那么a和b可能会share一个地址单元,即sizeof(data) = 8;但是子类,父类的数据成员可以为了空间效率share一个地址单元吗?
假如Concrete1 和Concere2都有一个char的属性,而且Concere2继承自Concrete1。那么如果这两个数据成员share一个地址单元会有什么问题?那么我们思考一下以下的赋值能符合我们的预期吗?
Concrete1 *pc1_1, pc1_2; Concrete2 c2; pc1_1 = &c2; //memory allocate for pc1_2 *pc1_2 = *pc1_1;
注意,从pc1_1到pc1_2的memberwise复制(复制一个一个的member)时,pc1_1的char b就被抹掉了。那么pc1_1就丢掉了派生类的信息。而这个复制很显然不是我们需要的!
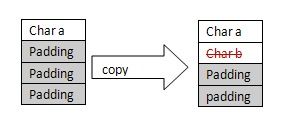
这也是为什么C++语言保证“出现在派生类中的基类对象,有其完整性”!

3. 多重继承(Multiple Inheritance)
对于一个多重派生对象,将其地址指定给“最左端(也就是第一个)基类的指针”,情况和单一继承时相同,因为两者都指向相同的起始地址。需要付出的成本只是地址的指定操作而已,至于第二个或后继的base class的地址指定操作,则需要进行地址修改:加上或者减去介于中间base class大小。下图展示了多继承的关系。涉及到4个类 Point2d、Point3d、Vertex和Vertex3d(p115)

下面展示了多重继承的对象模型。
注意,多继承的情况下,drived clas可能会有两个或两个以上虚函数表指针。
请看下面的表达式:
Vertex3d v3d; Vertex* pv; Point2d* p2d; Point3d * p3d;那么这个操作 pv = &v3d 需要转换内部代码
pv = (Vertex*)(((char*)&v3d) + sizeof(Point3d))
那么如果pv是从另外一个Vertex3d的指针(比如是pv3d)拷贝过来呢?那么需要考虑空指针的情况。
pv = pv3d
?(Vertex*)(((char*)&v3d) + sizeof(Point3d))
:0;下面这两个操作,只需要拷贝地址就行了。
p2d = &v3d;
p3d = &v3d;
以下引自陈皓先生的名著《C++ 对象的内存布局(上)》中多重继承。使用的是VC++和GCC3.4.4

使用图片表示是下面这个样子:
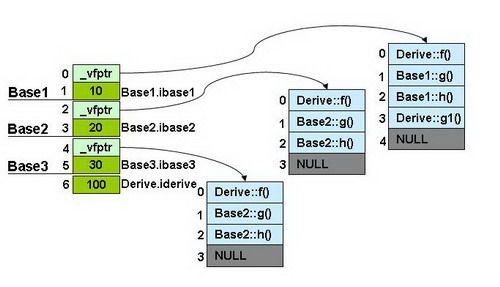
我们可以看到:
1) 每个父类都有自己的虚表。
2) 子类的成员函数被放到了第一个父类的表中。
3) 内存布局中,其父类布局依次按声明顺序排列。
4) 每个父类的虚表中的f()函数都被overwrite成了子类的f()。这样做就是为了解决不同的父类类型的指针指向同一个子类实例,而能够调用到实际的函数。
4. 虚拟多继承情况
下图可以表现Vertex3d 的继承体系图。左为多重继承,右为虚拟多重继承。
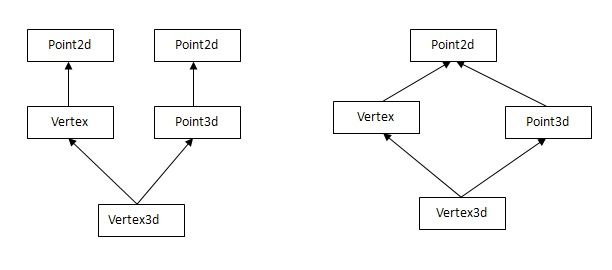
各个class的定义如下:
class Point2d{
...
protect:
float _x, _y;
};
class Vertex: public virtual Point2d{
...
protected:
Vertex *next;
};
class Point3d: public virtual Point2d{
...
protected:
float _z;
};
class Vertex3d: public Vertex, public Point3d{
...
protected:
float mumble;
};
不论是 Vertex还是 Point3d都内含一个 Point2d。然而在 Vertex3d的对象布局中,我们只需要单一一份 Point2d就好。如何使多重继承,那么Vertex3d对象中将有两个Point2d,那么对Point2d的引用可能会有歧义。所以引入虚拟继承。然而编译器要实现虚拟继承,实在是困难度颇高。虚拟继承的原则就是:让 Vertex和 Point3d各自维护的Point2d 折叠成一个有Vertex3d维护的单一Point2d,并且还可以保存base class 和derived class的指针之间的多台指定操作。
如果一个class含有virtual base classsubobjects, 那么,该对象将被分割为两部分:一个不变局部和一个共享局部。不变局部中的数据,不管后继如何演化,总是拥有固定的offset,所以这部分数据可以直接存取。至于共享局部(即virtual base class),这一部分的数据,其位置会因为每次的派生操作而有变化,所以他们只能被间接存取。各家编译器实现技术之间的差异就是间接存取的方法不同。
如何存取class的共享局部呢?cfront编译器会在每一个derived class中安插一个指向virtual base class的指针,这样就可以间接存取。这样的实现模型会有下面两个主要缺点:
1.每一个对象必须针对其每一个virtual base class 背负一个额外的指针。
解决方法有:第一个,Microsoft编译器引入所谓的virtual base class table。每一个class object如果有一个或多个virtual base class,就会由编译器安插一个指针,指向virtual base class table。至于真正的virtual base class 指针,当然是被放在该表格中。请看下面的虚拟继承对象模型,如图。
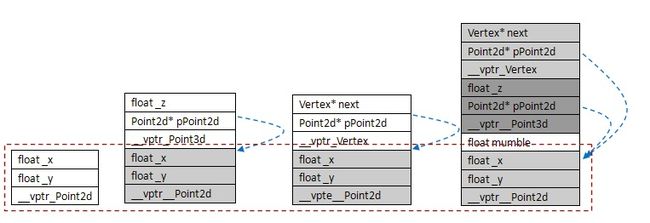
红框内即所谓的“共享局部”,其位置会因每次派生操作而有所变化。虚拟破坏了base class 的对象完整型,虚拟继承会在自己类中生成一个虚函数表指针。
第二个、在virtual function table 中放置virtual base class的offset(不是地址)。
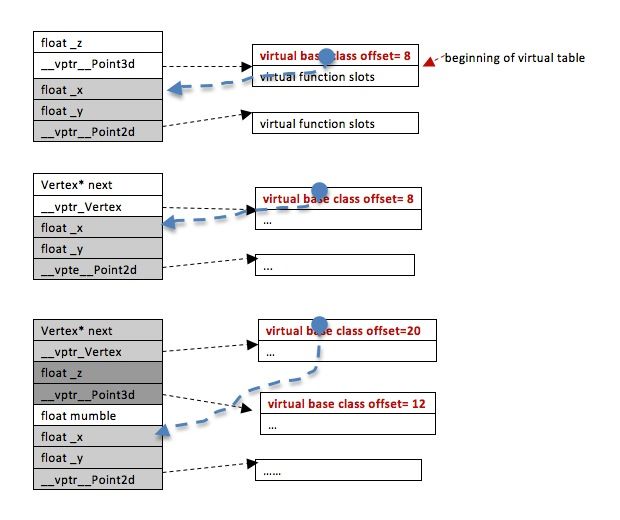
这个方法的好处是,巧妙的利用了虚函数表的结构,使得drived class 能够节省一个指针的大小。上图中蓝色曲线是offset
2.由于虚拟继承串链的加长,导致间接存取层次的增加。例如:如果我们有三层虚拟衍化,我就需要三次间接存取(经由三个virtual base class指针)。
这个问题的解决方案有:拷贝所有的virtual base class 的指针到drived class中。这样就解决了存取时间的问题,虽然会有空间的开销。
参考资料:
1. http://blog.csdn.net/haoel/archive/2008/10/15/3081328.aspx
2. http://blog.csdn.net/hherima/article/details/8888539