MIT 操作系统实验 MIT JOS lab2
MIT JOS lab2
首先把内存分布理清楚,由/boot/main.c可知这里把kernel的img的ELF header读入到物理地址0x10000处
这里可以回顾JOS lab1的一个小问,当时是问的bootloader怎么就能准确的吧kernle 镜像读入到对应的地址呢?
这里就是main.c在作用.
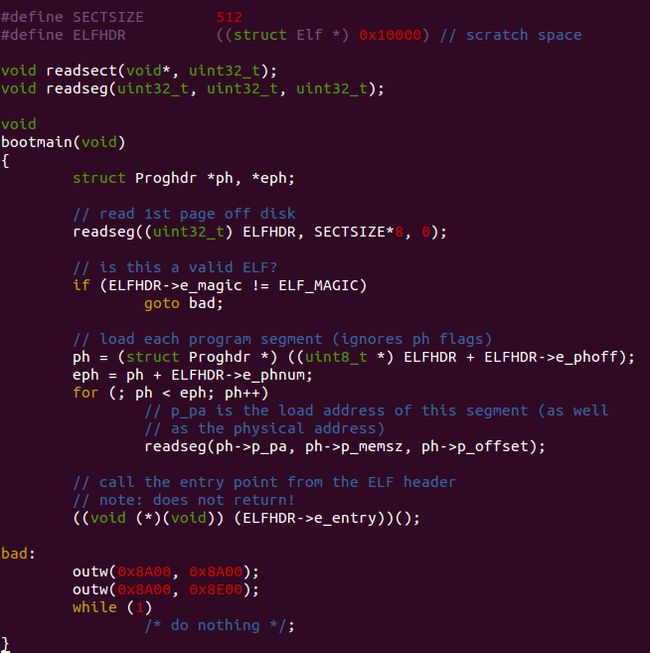
这里往ELFHDR即0x10000处读入了8个SECTSIZE(这里读入的是一个PAGESIZE 4KB),
从注释//is this a valid ELF? 开始,bootmain下面的部分就开始读入kernel 镜像到物理内存ph->p_pa处

由对应的反汇编知道把0x1001c处的值(52),和0x10000相加,得到ph,即指向结构体struct Proghdr的指针
这下是铁打的0x100000,ph->p_pa的值,这里会把 kernel 镜像到物理内存ph->p_pa处即 0x100000
![]()
52是struct Elf 内e_phoff的偏移量,12是struct Proghdr内p_pa的偏移量
Part 1: Physical Page Management
其实下面才是14年版本的第一个exercise 1

然后 bootmain 的最后一句跳转到0x10000c 处,开始执行 entry.S 的代码. 这里不记得了就去看lab 1
内存分布就清楚了

注意到kernel结束之后就是free memory了,而在free memory的最开始存放的是pgdir,这块内存同样由boot_alloc申请

而实验要求我们去填补函数boot_alloc()

这里注意要4k页面对齐
boot_alloc的实现是很"精巧"的.这里JOS的作者对于C的熟悉程度是出神入化的.
很巧妙的利用了局部静态变量nextfree没有显式的赋值初始化的时候,会默认初始化为0,并且只初始化一次
这里,这两个特点都利用的很好. 如果nextfree是第一次使用,就进入if判断语句,如果之前进入过if判断语句了,再次调用boot_alloc的时候就不需要再进入if语句了.
// This simple physical memory allocator is used only while JOS is setting
// up its virtual memory system. page_alloc() is the real allocator.
//
// If n>0, allocates enough pages of contiguous physical memory to hold 'n'
// bytes. Doesn't initialize the memory. Returns a kernel virtual address.
//
// If n==0, returns the address of the next free page without allocating
// anything.
//
// If we're out of memory, boot_alloc should panic.
// This function may ONLY be used during initialization,
// before the page_free_list list has been set up.
static void *
boot_alloc(uint32_t n)
{
static char *nextfree; // virtual address of next byte of free memory
char *result;
// Initialize nextfree if this is the first time.
// 'end' is a magic symbol automatically generated by the linker,
// which points to the end of the kernel's bss segment:
// the first virtual address that the linker did *not* assign
// to any kernel code or global variables.
if (!nextfree) {
extern char end[];
nextfree = ROUNDUP((char *) end, PGSIZE);
}
// Allocate a chunk large enough to hold 'n' bytes, then update
// nextfree. Make sure nextfree is kept aligned
// to a multiple of PGSIZE.
//
// LAB 2: Your code here.
result = nextfree;
nextfree = ROUNDUP(n, PGSIZE);
return result;
}
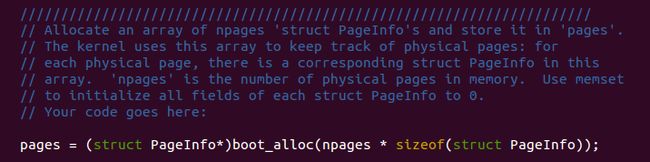
被要求开辟npages数目的结构体PageInfo空间,由pages指向该空间
紧接着就开始page_init()了

page_init()中,通过page_free_list这个全局中间变量,把后一个页面的pp_link指向前一个页面,于是这里就把所有的pages都链接起来了
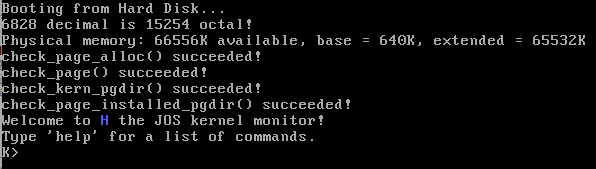
会达到什么效果?看下面的图


把有颜色(蓝,红)的部分标记为已经使用,白色部分标记为空闲
void
page_init(void)
{
// The example code here marks all physical pages as free.
// However this is not truly the case. What memory is free?
// 1) Mark physical page 0 as in use.
// This way we preserve the real-mode IDT and BIOS structures
// in case we ever need them. (Currently we don't, but...)
// 2) The rest of base memory, [PGSIZE, npages_basemem * PGSIZE)
// is free.
// 3) Then comes the IO hole [IOPHYSMEM, EXTPHYSMEM), which must
// never be allocated.
// 4) Then extended memory [EXTPHYSMEM, ...).
// Some of it is in use, some is free. Where is the kernel
// in physical memory? Which pages are already in use for
// page tables and other data structures?
//
// Change the code to reflect this.
// NB: DO NOT actually touch the physical memory corresponding to
// free pages!
size_t i;
uint32_t pa;
page_free_list = NULL;
for (i = 0; i < npages; i++) {
if(i == 0)
{
pages[0].pp_ref = 1;
pages[0].pp_link = NULL;
continue;
}
else if(i < npages_basemem)
{
pages[i].pp_ref = 0;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
else if(i <= (EXTPHYSMEM/PGSIZE) || i < (((uint32_t)boot_alloc(0) - KERNBASE) >> PGSHIFT))
{
pages[i].pp_ref++;
pages[i].pp_link = NULL;
}
else
{
pages[i].pp_ref = 0;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
pa = page2pa(&pages[i]);
if((pa == 0 || (pa >= IOPHYSMEM && pa <= ((uint32_t)boot_alloc(0) - KERNBASE) >> PGSHIFT )) && (pages[i].pp_ref == 0))
{
cprintf("page error: i %d\n",i);
}
}
}
page_alloc函数的实现. 就是把当前free list中的空闲页释放一个,然后更新page_free_list,让ta指向下一个空闲页即可
struct PageInfo *
page_alloc(int alloc_flags)
{
struct Page* pp = NULL;
if(!page_free_list)
{
return NULL;
}
pp = page_free_list;
page_free_list = page_free_list->pp_link;
if(alloc_flags & ALLOC_ZERO)
{
memset(page2kva(pp),0,PGSIZE);
}
return pp;
}
对应的page_free就是把pp描述的page加入到free list当中去,使得pp成为最新的page_free_list.
这里assert 断言,为了确保 当前待释放页面pp,没有进程再引用这块页面.(pp_ref == 0), 或者, pp->pp_link == NULL,一般到不了这一步,因为这种情况只可能是释放page table.
void
page_free(struct PageInfo *pp)
{
// Fill this function in
// Hint: You may want to panic if pp->pp_ref is nonzero or
// pp->pp_link is not NULL.
assert(pp->pp_ref == 0 || pp->pp_link == NULL);
pp->pp_link = page_free_list;
page_free_list = pp;
}

这里就是提醒大家一定一定要搞清楚分段和分页的机制,不然后面很难懂.
这地方都急不得,我以前也是去挖 linux 0.11的坑,花了很多时间,但是好像什么都没学到,其实也不是的.这其中就打下了理解分段分页的基础,也写了blog作为笔记贴.

可以看出,左右两边分别是qemu和gdb分别用xp指令和x指令去查看地址内容指令.

其实也没什么.无非就是让你去了解虚拟地址和物理地址的区别
再思考下面这个问题.

答案是 uintptr_t.
任何指针指向的都是虚拟地址: )

pgdir_walk是很关键的函数
下图是page directory 和 page table的组织形式

pte_t *
pgdir_walk(pde_t *pgdir, const void *va, int create)
{ //pgdir 本身是虚拟地址 解引用得到的是page directory的物理地址(QAQ 多么痛的领悟~)
pde_t *pde = NULL;
pte_t *pgtable = NULL;
struct PageInfo *pp;
pde = &pgdir[PDX(va)];
if(*pde & PTE_P)
{
pgtable = (KADDR(PTE_ADDR(*pde)));
}
else
{
if(!create ||
!(pp = page_alloc(ALLOC_ZERO)) ||
!(pgtable = (pte_t*)page2kva(pp)))
{
return NULL;
}
pp->pp_ref++;
*pde = PADDR(pgtable) | PTE_P |PTE_W | PTE_U;
}
return &pgtable[PTX(va)];
}
create 标志是1 如果当前va地址所属的页不存在,那么申请开辟这页,
create 如果标志是0.仅仅是查询va地址所属的页是否存在. 存在就返回对应的page table的入口地址,不存在就返回NULL.
boot_map_region该函数把虚拟地址[va,va+size)的区域映射到物理地址pa开始的内存中去
static void
boot_map_region(pde_t *pgdir, uintptr_t va, size_t size, physaddr_t pa, int perm)
{
uintptr_t va_next = va;
physaddr_t pa_next = pa;
pte_t * pte = NULL;//page table entrance
ROUNDUP(size,PGSIZE);//page align
assert(size%PGSIZE == 0 || cprintf("size:%x \n",size));
int temp = 0;
for(temp = 0;temp < size/PGSIZE;temp++)
{
pte = pgdir_walk(pgdir,va_next,1);
if(!pte)
{
return;
}
*pte = PTE_ADDR(pa_next) | perm | PTE_P;
pa_next += PGSIZE;
va_next += PGSIZE;
}
}
page_lookup函数检测va虚拟地址的虚拟页是否存在
不存在返回NULL,
存在返回描述该虚拟地址关联物理内存页的描述结构体PageInfo的指针.... (PageInfo 结构体仅用来描述物理内存页)
不要对函数参数做检查
struct PageInfo *
page_lookup(pde_t *pgdir, void *va, pte_t **pte_store)
{
pte_t* pte = pgdir_walk(pgdir,va,0);
if(!pte)
{
return NULL;
}
*pte_store = pte;
return pa2page(PTE_ADDR(*pte));
}
先熟悉一下这个
http://blog.csdn.net/cinmyheart/article/details/39994769
不然下面函数的最后一行代码不明白
page_remove 清除va所在虚拟内存页,怎么清除?把这个虚拟页的关联物理页的page table entrance 置为NULL就OK啦(原本page table entrance解引用得到的就是物理页地址)
void
page_remove(pde_t *pgdir, void *va)
{
pte_t* pte = pgdir_walk(pgdir,va,0);
pte_t** pte_store = &pte;
struct PageInfo* pp = page_lookup(pgdir,va,pte_store);
if(!pp)
{
return ;
}
page_decref(pp);
**pte_store = 0; //关键一步
tlb_invalidate(pgdir,va);
}
page_insert 把pp描述的物理页与虚拟地址va关联起来
如果va所在的虚拟内存页不存在,那么pgdir_walk的create为1,创建这个虚拟页
如果va所在的虚拟内存页存在,那么取消当前va的虚拟内存页也和之前物理页的关联,并且为va建立新的物理页联系——pp所描述的物理页
int
page_insert(pde_t *pgdir, struct PageInfo *pp, void *va, int perm)
{
pte_t* pte = pgdir_walk(pgdir,va,0);
physaddr_t ppa = page2pa(pp);
if(pte)
{
if(*pte & PTE_P)
{
page_remove(pgdir,va);//取消va与之物理页之间的关联
}
if(page_free_list == pp)
{
page_free_list = page_free_list->pp_link;//update the new free_list header
}
}
else
{
pte = pgdir_walk(pgdir,va,1);
if(!pte)
{
return -E_NO_MEM;
}
}
*pte = page2pa(pp) | PTE_P | perm; //建立va与pp描述物理页的联系
pp->pp_ref++;
tlb_invalidate(pgdir,va);
return 0;
}
Part 2: Virtual Memory
终于到part 2了....
Virtual, Linear, and Physical Addresses
In x86 terminology, a virtual address consists of a segment selector and an offset within the segment. A
linear address is what you get after segment translation but before page translation. A physical address
is what you finally get after both segment and page translation and what ultimately goes out on the
hardware bus to your RAM
A C pointer is the "offset" component of the virtual address.
哈哈,写了也有段时间的C语言了,指针的本质是什么,段内偏移
From code executing on the CPU, once we're in protected mode (which we entered first thing in boot/boot.S ), there's no way to directly use a linear or physical address. All memory references are interpreted as virtual addresses and translated by the MMU, which means all pointers in C are virtual addresses.
* 解引用都是对于虚拟地址来做的,如果你对物理地址解引用,硬件会把ta当作虚拟地址来操作
If you cast a physaddr_t to a pointer and dereference it, you may be able to load and store to the resulting address (the hardware will interpret it as a virtual address), but you probably won't get the memory location you intended.
Part 3: Kernel Address Space
JOS divides the processor's 32bit linear address space into two parts. User environments (processes),
which we will begin loading and running in lab 3, will have control over the layout and contents of the
lower part, while the kernel always maintains complete control over the upper part.
注意下面ULIM是分界线,ULIM以上是内核地址空间,以下是用户空间
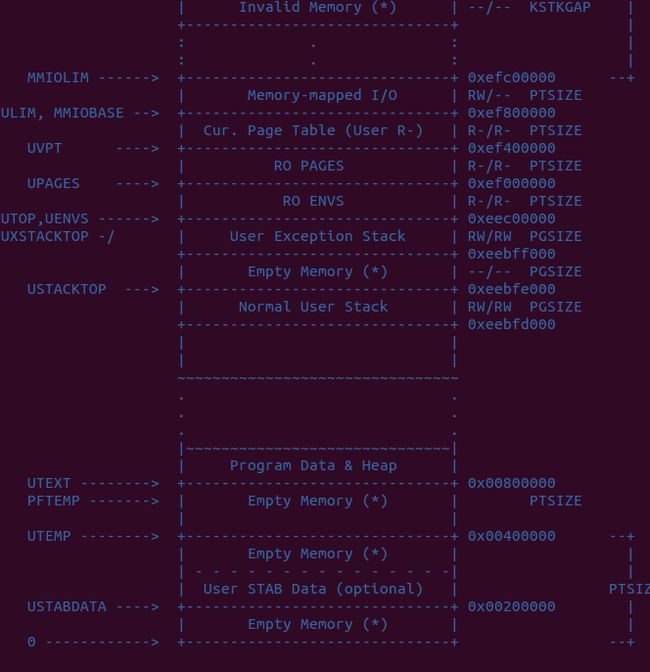
这个页面布局代表的是启用地址转换以后,无论是操作系统还是用户程序,看到的虚拟内存布局,这也就是说,操
操 作系统和用户程序使用的是同一套页目录和页表

https://github.com/jasonleaster/MIT_JOS_2014/blob/lab2/kern/pmap.c
特别注意,内核这个部分的函数参数的指针不能做“常规的类型检查”直接return,我为这个bug....从晚上6点debug到现在(12点XX)

请叫我大自然的搬运工: 因为北大的童鞋各种破题,于是就自动跳转Clann24同学的github吧:
https://github.com/Clann24/jos/tree/master/lab2
We have placed the kernel and user environment in the same address space. Why will user programs not be able to read or write the kernel's memory? What specific mechanisms protect the kernel memory?
Because PTE_U is not enabled.
What is the maximum amount of physical memory that this operating system can support? Why?
2G, becuase the maximum size of UPAGES is 4MB, sizeof(struct PageInfo))=8Byte, so we can have at most4MB/8B=512K pages, the size of one page is 4KB, so we can have at most 4MB/8B*4KB)=2GB physical memory.
How much space overhead is there for managing memory, if we actually had the maximum amount of physical memory? How is this overhead broken down?
We need 4MB PageInfos to manage memory plus 2MB for Page Table plus 4KB for Page Directory if we have 2GB physical memory. Total:6MB+4KB
Revisit the page table setup in kern/entry.S and kern/entrypgdir.c. Immediately after we turn on paging, EIP is still a low number (a little over 1MB). At what point do we transition to running at an EIP above KERNBASE? What makes it possible for us to continue executing at a low EIP between when we enable paging and when we begin running at an EIP above KERNBASE? Why is this transition necessary?
After jmp *%eax finished. It is possible because entry_pgdir also maps va [0, 4M) to pa [0, 4M), it's necessary because later a kern_pgdir will be loaded and va [0, 4M) will be abandoned.
