关于CPU编程—无锁编程
Lock-free 算法通常比基于锁的算法要好:
- 从其定义来看,它们是 wait-free 的,可以确保线程永远不会阻塞。
- 状态转变是原子性的,以至于在任何点失败都不会恶化数据结构。
- 因为线程永远不会阻塞,所以当同步的细粒度是单一原子写或比较交换时,它们通常可以带来更高的吞吐量。
- 在某些情况下,lock-free 算法会有更少的同步写操作(比如 Interlocked 操作),因此纯粹从性能来看,它可能更便宜。
但是 lock-freedom 并不是万能药。下面是一些很明显的不利因素:
- 乐观的并发使用会对 hot data structures 导致 livelock。
- 代码需要大量困难的测试。通常其正确性取决于对目标机器内存模型的正确解释。
- 基于众多原因,lock-free 代码很难编写和维护。
无锁编程与分布式编程那个更适合多核CPU?
前一篇文章
多核系统中三种典型锁竞争的加速比分析讲过了三种典型锁竞争情况下的加速比情况,特别是分布式锁竞争的加速比和CPU核数成正比,有很好的加速比性能。由于近些年在学术界中,无锁编程属于研究热点。那么使用无锁编程是不是可以取得更好的加速比性能呢?或者说无锁编程是不是更适合多核CPU系统呢?
无锁编程主要是使用原子操作替代锁来实现对共享资源的访问保护,举个例子,要对某个整数变量进行加1操作的话,用锁保护操作的代码如下:
int a = 0;
Lock();
a+= 1;
Unlock();
如果对上述代码反编译可以发现 a+=1;被翻译成了以下三条汇编指令:
mov eax,dword ptr [a]
add eax,1
mov dword ptr [a],eax
如果在单核系统中,由于在上述三条指令的任何一条执行完后都可能发生任务切换,比如执行完第1条指令后就发生了任务切换,这时如果有其他任务来对a进行操作的话,当任务切换回来后,将继续对a进行操作,很可能出现不可预测的结果,因此上述三条指令必须使用锁来保护,以使这段时间内其他任务无法对a进行操作。
需要注意的是,在多核系统中,因为多个CPU核在物理上是并行的,可能发生同时写的现象;所以必须保证一个CPU核在对共享内存进行写操作时,其他CPU核不能写这块内存。因此在多核系统中和单核有区别,即使只有一条指令,也需要要加锁保护。
如果使用原子操作来实现上述加1操作的话,例如使用VC里的InterlockedIncrement来操作的话,那么对a的加1操作需要以下语句
InterlockedIncrement (&a);
这条语句最终的实际加1操作会被翻译成以下一条带lock前缀的汇编指令:
lock xadd dword ptr [ecx],eax
使用原子操作时,在进行实际的写操作时,使用了lock指令,这样就可以阻止其他任务写这块内存,避免出现数据竞争现象。原子操作速度比锁快,一般要快一倍以上。
使用lock前缀的指令实际上在系统中是使用了内存栅障(memory barrier),当原子操作在进行时,其他任务都不能对内存操作,会影响其他任务的执行。因此这种原子操作实际上属于一种激烈竞争的锁,不过由于它的操作时间很快,因此可以看成是一种极细粒度锁。
在无锁(Lock-free)编程环境中,主要使用的原子操作为CAS(Compare and Swap)操作,在VC里对应的操作为InterlockedCompareExchange或者InterlockedCompareExchangeAcquire;如果是64位的操作,需要使用InterlockedCompareExchange64或者InterlockedCompareExchangeAcquire64。使用这种原子操作替代锁的最大的一个好处是它是非阻塞的。
按照微软MSDN的说明,InterlockedCompareExchange带有全局的内存栅障(full memory barrier),在使用了full memory barrier的情况下,即使不是访问同一内存变量的原子操作也会发生竞争,从竞争形式上来讲,会发生固定式锁竞争或随机锁竞争现象,并且无法实现分布式锁竞争的竞争模式,比起使用普通锁的竞争会更激烈,因此最终得到的加速比会比上一篇文章里讲的固定式锁竞争还要糟糕。
对于象InterlockedCompareExchangeAcquire这类的原子操作,没有使用full memory barrier,因此性能理论上会比使用full memory barrier的原子操作好很多(由于目前这类原子操作只有在特定的机器才支持,具体性能到底如何没有测试过,微软的MSDN里也对性能方面作出说明)。但是如果采用固定式锁竞争形式,其加速比仍然是按照前面的固定式锁竞争的加速比公式来计算:
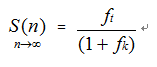
由于原子操作速度比锁快,其实相比于普通锁操作,相当于加锁解锁时间减少了2~3倍左右,不妨以2倍来计算,对应的任务粒度会增大一倍,为 ![]() ,另外由于原子操作内的锁内计算通常只是简单一两条指令,因此其锁粒度很小,可以近似看成为0,因此加速比为:
,另外由于原子操作内的锁内计算通常只是简单一两条指令,因此其锁粒度很小,可以近似看成为0,因此加速比为:

因此在固定式锁竞争情况下,加速比的极限值约等于使用普通锁时的2倍任务粒度大小,大约比使用 普通锁时的加速比大一倍左右。加速比并不能随CPU核数增长而线性增加。
对于随机式锁竞争情况,加速比为:
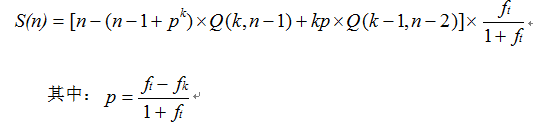
如果讲普通锁操作改成原子操作,将锁粒度近似看成0,那么
 ,对于任务粒度非常大的情况,概率p的增加并不大;对于任务粒度非常小的情况,概率p最大可以增大近似一倍,加速比相比于普通锁也可以获得一定程度的提高。
,对于任务粒度非常大的情况,概率p的增加并不大;对于任务粒度非常小的情况,概率p最大可以增大近似一倍,加速比相比于普通锁也可以获得一定程度的提高。
,对于任务粒度非常大的情况,概率p的增加并不大;对于任务粒度非常小的情况,概率p最大可以增大近似一倍,加速比相比于普通锁也可以获得一定程度的提高。
对于普通锁随机竞争情况下的最坏情况,加速比为:

改成原子操作后,加速比为:

只是相对于普通锁竞争情况提高了一些,并不能随CPU核数增加而增加。
注意上面没有考虑无锁编程的算法开销,采用无锁编程时,要完成一个CAS操作需要在一个循环里来完成,有可能要循环很多次才能完成一次写操作,因此实际性能并达不到上面的计算结果。
因此即使使用无锁编程,如果锁竞争形式仍然是固定式竞争或随机竞争的形式,加速比性能仍然是不乐观的,仍然跟分布式锁竞争的加速比差很远,因为分布式锁竞争在最坏情况下加速比也可以做到接近CPU核数。
当然有人也会提出,既然分布式锁竞争的加速比性能这么好,那么将原子操作替代普通锁来进行分布式竞争,岂不是可以取得更好的加速比性能?理论上来说,如果以不带
full memory barrier
的原子操作来替代普通锁进行分布式竞争,是可以取得比普通锁进行分布式竞争更好的加速比,分布式加速比为
 ,使用原子操作后,任务粒度将会增大2~3倍,对于任务粒度非常小的情况,比如任务粒度小于0.5(这种情况实际中很难出现),加速比将比使用普通锁时增大一倍左右,对于任务粒度较大的情况,加速比增加并不明显。
,使用原子操作后,任务粒度将会增大2~3倍,对于任务粒度非常小的情况,比如任务粒度小于0.5(这种情况实际中很难出现),加速比将比使用普通锁时增大一倍左右,对于任务粒度较大的情况,加速比增加并不明显。
对于任务粒度的大小,很大程度上取决于程序员对任务的划分,只要程序员在划分任务时不要将任务粒度划得太小,这样就可以降低任务粒度对加速比造成的影响。
但是使用分布式锁竞争时,性能已经可以和单核多任务时的程序性能接近了,使用无锁编程难度非常高,程序复杂度也非常高,非专业人士难以掌握,普通程序员想要进行无锁编程几乎是不可能的事情。而分布式编程的难度和以前单核多任务时代的数据结构算法编程难度差不多,普通程序员都可以掌握。因此在实际情况中只要任务粒度不是太小,就没有必要过于追求性能,使用普通锁的分布式锁竞争已经足够了。
从目前无锁编程的发展来看,已经实现了的无锁算法很有限,并且功能也很有限,并且无锁编程是独立于以前的单核时代的编程的,使用无锁编程几乎无法复用以前的成果。分布式编程是在原有的单核多任务编程基础上发展而来,可以继承以前单核时代的成果,比如队列池便可以继承已有的队列算法,因此采用分布式编程可以大大减轻将现有单核程序移植到多核系统中的工作量,只要对现有程序进行一些重构即可完全支持多核CPU系统。
综上所述,可以得到下表所示的结论
|
|
比较项目
|
无锁编程
|
分布式编程
|
|
1
|
加速比性能
|
取决于竞争方式,除非也采用分布式竞争,否则不如分布式锁竞争的性能
|
加速比和CPU核数成正比关系,接近于单核多任务时的性能
|
|
2
|
实现的功能
|
有限
|
不受限制
|
|
3
|
程序员掌握难易程度
|
难度太高,过于复杂,普通程序员无法掌握,目前世界上只有少数几个人掌握。
|
和单核时代的数据结构算法难度差不多,普通程序员可以掌握
|
|
4
|
现有软件的移植
|
使用无锁算法后,以往的算法需要废弃掉,无法复用
|
可以继承已有的算法,在已有程序基础上重构即可。
|
从上表的四个方面的综合比较可以看出,无锁编程的实用价值是远远不如分布式编程的,因此分布式编程比无锁编程更适合多核CPU系统。
转自:http://blog.csdn.net/windows_zf/article/details/3086498