没有接口的情况下开发手机客户端
最近一个开发项目用到了图书馆的一些数据,图书馆用的系统又没提供数据接口,所以老规矩,用HttpClient和Jsoup这两大开源工程上,用Android手机来模拟图书馆查询的请求与响应,
网站是学校的图书馆网:lib.gdou.edu.cn
第一步:分析并模拟网站的请求与响应
工具就不用介绍了,百度一大把,有些浏览器还自带,按一下你的F12,看有没有?~_~
URi的生成代码部分与请求:
生成后的变成:
[url=http://210.38.138.1:81/searchresult.aspx?anywords=java&dt=ALL&cl=ALL&dp=20&sf=M_PUB_YEAR&ob=DESC&sm=table&dept=ALL]http://210.38.138.1:81/searchresult.aspx?anywords=搜的关键字&dt=ALL&cl=ALL&dp=20&sf=M_PUB_YEAR&ob=DESC&sm=table&dept=ALL
在上面拿到Html响应后进入到Joup包里去解释,得到想要的图书条目
Joup里的代码部分:
第二步就进行数据的显示与布局
这里由于自己做一个布局的话一费时,二来我与不太会做界面,所以直接拿开源工程饭否的界面,改了一下就用上。请高手见谅。。。
这步重点是ListView的用法与异步的使用
代码比较多,我就不贴了,自己找代码看下
软件运行界面:
网站是学校的图书馆网:lib.gdou.edu.cn
第一步:分析并模拟网站的请求与响应
工具就不用介绍了,百度一大把,有些浏览器还自带,按一下你的F12,看有没有?~_~
首先是搜索的页面的分析,其他的同理:

输入关键字后得到,在后台扑获的数据为
- Request URL:http://210.38.138.1:81/search.aspx
- Request Method:POST
- Status Code:302 Found
- <font color="\"#ff0000\"">Request Headersview source //http请求头部分</font>
- Accept:text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
- Accept-Charset:GBK,utf-8;q=0.7,*;q=0.3
- Accept-Encoding:gzip,deflate,sdch
- Accept-Language:zh-CN,zh;q=0.8
- Cache-Control:max-age=0
- Connection:keep-alive
- Content-Length:5273
- Content-Type:application/x-www-form-urlencoded
- Cookie:ASP.NET_SessionId=sls3z2f2bux2mbbmin5hiv55; sulcmiswebpac=B0A84B140CE5D6A7A4E6FCBC672F3C68117288906D6A6FB1391C78220BFDE5F884CF686A3C2AB0933C93CB6237BA2A0281BE8A2EA3D43775BF0C7E718904A5385EB7CA5C3CD7375266E20498A647065205DF37BE7C48B395AC7A6D8E22DFFC06
- Host:210.38.138.1:81
- Origin:http://210.38.138.1:81/search.aspx
- User-Agent:Mozilla/5.0 (Windows NT 6.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.46 Safari/535.11
- <font color="\"#ff0000\"">Form Dataview URL encoded //用post提交的表单数据</font>
- __VIEWSTATE: //这里一长串的数据被我省略了,要看自己抓一下就可以了,这串没弄明白是提交上去干什么的,不知是不是用来保存数据的,等高手解释吧
- ctl00$ContentPlaceHolder1$splb:ANYWORDS
- ctl00$ContentPlaceHolder1$keywordstb:java
- ctl00$ContentPlaceHolder1$searchbtn:快速检索
- ctl00$ContentPlaceHolder1$deptddl:ALL
- ctl00$ContentPlaceHolder1$depthf:ALL
- <font color="\"#ff0000\"">Response Headersview source //http响应的数据</font>
- Cache-Control:private
- Content-Length:243
- Content-Type:text/html; charset=utf-8
- Date:Mon, 25 Jun 2012 02:20:34 GMT
- Location:/searchresult.aspx?anywords=java&dt=ALL&cl=ALL&dp=20&sf=M_PUB_YEAR&ob=DESC&sm=table&dept=ALL
- //302重定向到这个http里,所以要提交查找图书,直生成这个URI就行了,然后提交到服务器上面,就可以省去前面的请求与响应了
- PSP:CP=CAO PSA OUR
- Server:Microsoft-IIS/6.0
- X-AspNet-Version:2.0.50727
- X-Powered-By:ASP.NET
URi的生成代码部分与请求:
- public List<SearchBook> searchBook(String method, String word, int page) {
- this.method = method;
- this.word = word;
- HttpClient client = new DefaultHttpClient();
- List<NameValuePair> qparams = new ArrayList<NameValuePair>();
- qparams.add(new BasicNameValuePair(method, word));
- qparams.add(new BasicNameValuePair("dt", "ALL")); //这些可以自己到网页上看一下代表什么
- qparams.add(new BasicNameValuePair("cl", "ALL"));
- qparams.add(new BasicNameValuePair("dp", "20"));
- qparams.add(new BasicNameValuePair("sf", "M_PUB_YEAR"));
- qparams.add(new BasicNameValuePair("ob", "DESC"));
- qparams.add(new BasicNameValuePair("sm", "table"));
- qparams.add(new BasicNameValuePair("dept", "ALL"));
- qparams.add(new BasicNameValuePair("page", page + ""));
- URI uri;
- try {
- uri = URIUtils.createURI("http", "210.38.138.1:81", -1,
- "/searchresult.aspx",
- URLEncodedUtils.format(qparams, "GBK"), null);
- HttpGet httpget = new HttpGet(uri);
- System.out.println(httpget.getURI());
- addHttpGetHeader(httpget);
- HttpResponse response = client.execute(httpget);
- HttpEntity entity = response.getEntity();
- // System.out.println(EntityUtils.toString(entity));
- return JsoupUtils.getSearchBook(EntityUtils.toString(entity)); //拿到请求回来的html数据到JsopUtils包里面去解释,得到想要的数据
- } catch (ClientProtocolException e) {
- e.printStackTrace();
- } catch (ParseException e) {
- e.printStackTrace();
- } catch (URISyntaxException e) {
- e.printStackTrace();
- } catch (IOException e) {
- e.printStackTrace();
- }
- return null;
- }
生成后的变成:
[url=http://210.38.138.1:81/searchresult.aspx?anywords=java&dt=ALL&cl=ALL&dp=20&sf=M_PUB_YEAR&ob=DESC&sm=table&dept=ALL]http://210.38.138.1:81/searchresult.aspx?anywords=搜的关键字&dt=ALL&cl=ALL&dp=20&sf=M_PUB_YEAR&ob=DESC&sm=table&dept=ALL
在上面拿到Html响应后进入到Joup包里去解释,得到想要的图书条目
Joup里的代码部分:
- //解释搜书,使用Joup
- public static List<SearchBook> getSearchBook(String html){
- List<SearchBook> list=new ArrayList<SearchBook>();
- Document doc=Jsoup.parse(html);
- searchNumber=Integer.parseInt(doc.getElementById("ctl00_ContentPlaceHolder1_countlbl").text());//查找Html标签,得到特定内容
- if(searchNumber==0){
- return null;
- }
- Elements es=doc.getElementsByClass("tb").get(0).getElementsByTag("tr"); //得到表单的数据,遍历到一个类的对象中,用一个List来保存类对象,有用过jsoup都认识这个用法,不清楚去百度一下
- for(int i=1;i<es.size();i++){
- SearchBook book=new SearchBook();
- Elements tdes= es.get(i).getElementsByTag("td");
- for(int j=0;j<tdes.size();j++){
- switch (j) {
- case 0:
- book.setSystemnumber(tdes.get(j).getElementsByTag("input").attr("value"));
- break;
- case 1:
- book.setName(tdes.get(j).text().trim());
- break;
- case 2:
- book.setWriter(tdes.get(j).text().trim());
- break;
- case 3:
- book.setPublish(tdes.get(j).text().trim());
- break;
- case 4:
- book.setDate(tdes.get(j).text().trim());
- break;
- case 5:
- book.setSearchnumber(tdes.get(j).text().trim());
- break;
- case 6:
- book.setMax(tdes.get(j).text().trim());
- break;
- case 7:
- book.setMin(tdes.get(j).text().trim());
- break;
- default:
- break;
- }
- }
- list.add(book);
- System.out.println(book);
- }
- return list;
- }
第二步就进行数据的显示与布局
这里由于自己做一个布局的话一费时,二来我与不太会做界面,所以直接拿开源工程饭否的界面,改了一下就用上。请高手见谅。。。
这步重点是ListView的用法与异步的使用
代码比较多,我就不贴了,自己找代码看下
软件运行界面:

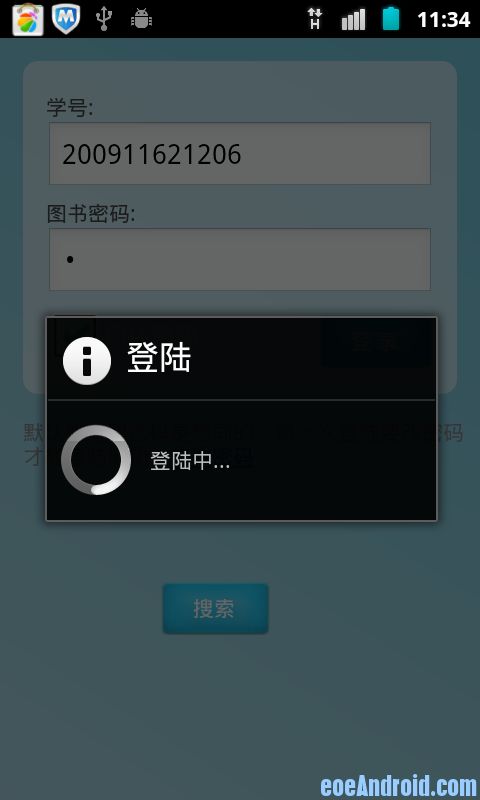
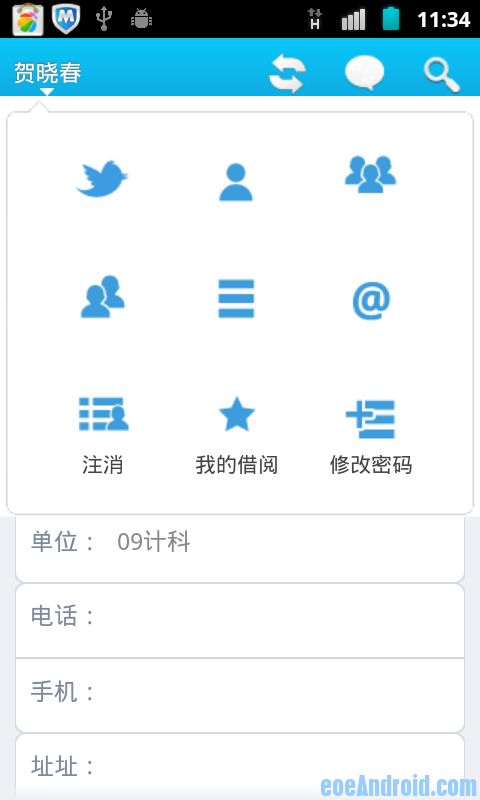


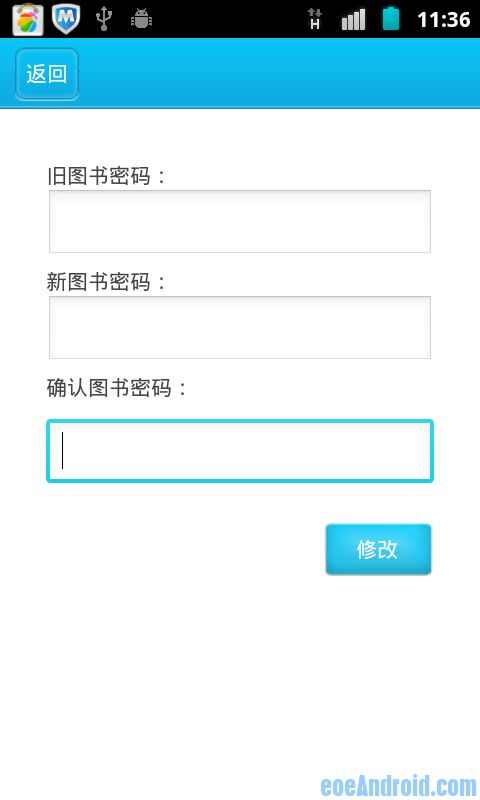
这些功能都可以对映到网页上的功能
总结:
个人觉得是搜索功能是完成的比较完全的,在详细图书查看本来是想做一个图书图片查看的和内容,可惜图书的图片不是图书管理系统里,抓图有点不方便,内容和目录又合在一起,显示非常乱,这个网页做得太差了,所以没去抓下来,只抓了有用的藏书地点,修改密码的功能与说一下,存在的问题就是修改成功与失败都返回同一个状态号,所以软件判断不了修改结果。只能自己重登陆试下。
最后,说下搜索功能是不需要登陆的
源码包地址:http://www.eoeandroid.com/thread-180939-1-1.html